SEO教程之搜索引擎工作原理介绍
1、爬行和抓取:
爬行和抓取是搜索引擎工作的第一步,完成数据收集的任务。
搜索引擎蜘蛛访问网站页面时类似于普通用户使用的浏览器。蜘蛛程序发出页面访问请求后,服务器返回 HTML代码,蜘蛛程序把收到的代码存入原始页面数据库。搜索引擎为了提高爬行和抓取速度,都使用多个蜘蛛并发分布爬行。

2、跟踪链接:
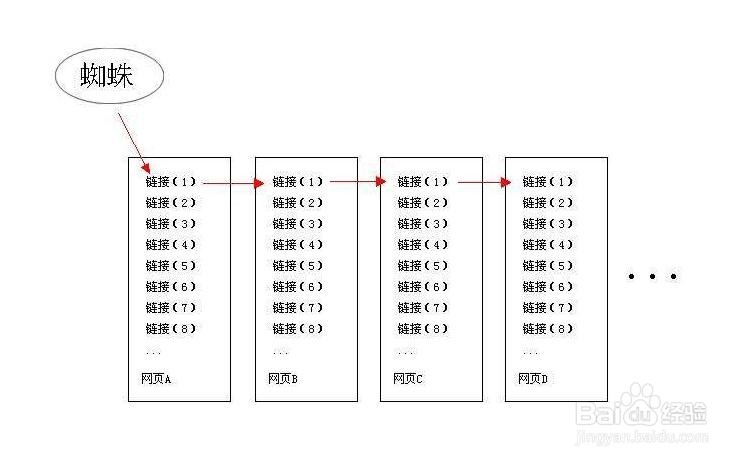
为了抓取网上尽量多的页面,搜索引擎蜘蛛会跟踪页面上的链接,从一个页面爬到下一个页面,就好像蜘蛛在蜘蛛网上爬行那样,这也就是搜索引擎蜘蛛这个名称的由来。

3、地址库:
为了避免重复爬行和抓取网址,搜索引擎会建立一个地址库,记录已经被发现还没有抓取的页面,以及已经被抓取的页面。
蜘蛛按重要性从待访问地址库中提取 URL,访问并抓取页面,然后把这个 URL从待访问地址库中删除,放进已访问地址库中。

4、文件存储:
搜索引擎蜘蛛抓取的数据存入原始页面数据库。其中的页面数据与用户浏览器得到的 HTML是完全一样的。每个 URL都有一个独特的文件编号。

5、爬行时的复制内容检测:
检测并删除复制内容通常是在下面介绍的预处理过程中进行,但现在的蜘蛛在爬行和抓取文件时也会进行一定程度的复制内容检测。遇到权重很低的网站上大量转载或抄袭内容时,很可能不再继续爬行。这也就是为什么有的站长在日志文件中发现了蜘蛛,但页面从来没有被真正收录过。
6、预处理:
搜索引擎蜘蛛抓取的原始页面,并不能直接用于查询排名处理。搜索引擎数据库中的页面数都在数万亿级别以上,用户输入搜索词后,靠排名程序实时对这么多页面分析相关性,计算量太大,不可能在一两秒内返回排名结果。因此抓取来的页面必须经过预处理,为最后的查询排名做好准备。
和爬行抓取一样,预处理也是在后台提前完成,用户搜索时感觉不到这个过程。

7、提取文字:
现在的搜索引擎还是以文字内容为基础。蜘蛛抓取到的页面中的 HTML代码,除了用户在浏览器上可以看到的可见文字外,还包含了大量的 HTML格式标签、JavaScript 程序等无法用于排名的内容。搜索引擎预处理首先要做的就是从 HTML文件中去除标签、程序,提取出可以用于排名处理的网页面文字内容。
