搜索引擎原理要点
搜索引擎原理要点
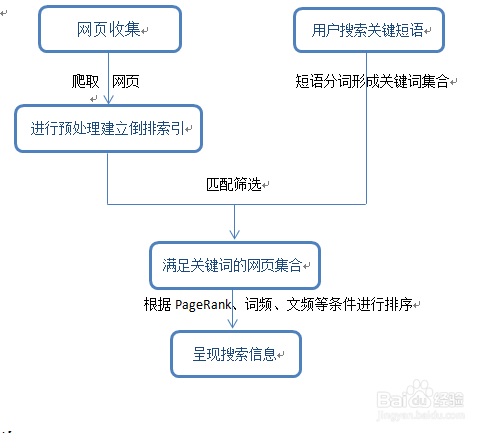
网页搜集:
定期搜集:在每个时间段中重新“批量收集网页”替换之前的。优点:实现简单,缺点:“时新性”(freshness)不高,还有重复搜集所带来的额外带宽的消耗。
增量搜集:开始搜集一批网页,后续搜集新出现的网页和相对上次有过更改的网页,删除现在不存在的网页。
搜集方式:
自动爬取:搜索引擎自动获取个网页中的URL得到网页集合,后期维护网页集合,出现新的保存,不存在的删除
网站拥有者主动提交站点:搜索引擎在一定时间会派出“蜘蛛”程序扫描网站信息,并且将网站信息存入数据库
预处理:
关键词的提取:提取出网页源文件的内容部分所含的关键词,中文需要切词软件,对内容进行词语分割,去除“的”、“在”等没有意义的“停用词”,将所有词语存入集合中
重复或转载网页的消除:为了维护搜索引擎的公平性、对用户的友好性需要在消除重复或转载的网页
链接分析:站点链接可以帮助搜索引擎判断网页的内容,分析重要程度
网页重要程度的计算:PageRank(越多站点引用某站点,说明该站点重要性越高)
查询服务:
对用户输入的短语或词组进行分词,生成一个用于参加匹配的查询词表;
与搜索引擎开始搜集的网页的倒排索引集合取交集,获得满足要求的文档集合的序号;
通过pageRank、词条出现的频率进行、文档频率等综合分析进行文档排序
获取文档中关键字周围的文字成文档摘要
体系机构(搜索引擎搜集网页的时候,要考虑效率、质量、礼貌问题):
1.利用较少的带宽、设备、时间资源完成预定的网页搜集
2.利用操作系统提供的异步通信机制
3.避免在搜集网页的过程中占用站点服务器太多的资源而影响站点的用户体验。
逻辑图:
关键词:搜索引擎、搜索引擎优化、SEO、搜索引擎原理、搜索引擎技术、百度技术