熊猫采集器如何采集小说
1、点击 新建项目(标准)。
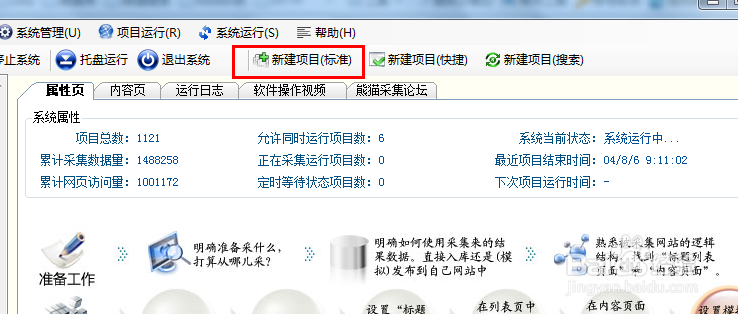
2、随便输入一个项目名称,也可以创建一个类别,方便管理,其他地方保持默认,然后点击下一步。
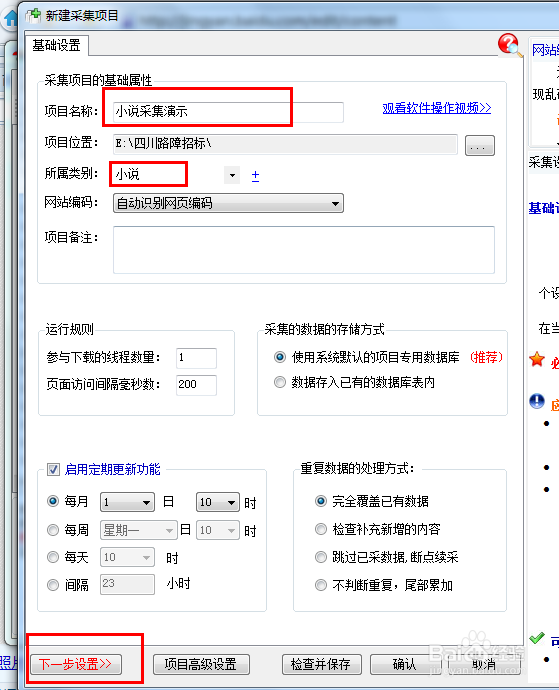
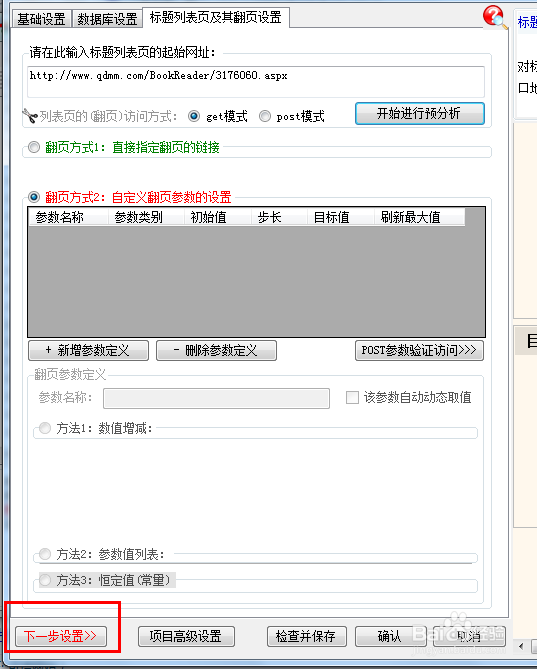
3、标题列表页及其翻页设置,列表页是包含我们要采集内容的链接网址的页面,比如百度搜索一个关键词,会列出来很多网页,有点类似这个。我们随便找一部小说的章节列表,复制该网页的网址。
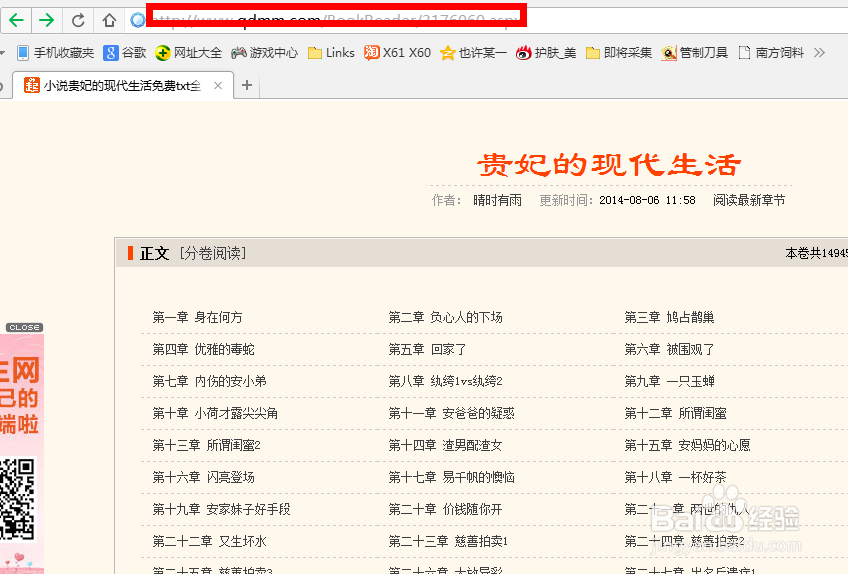
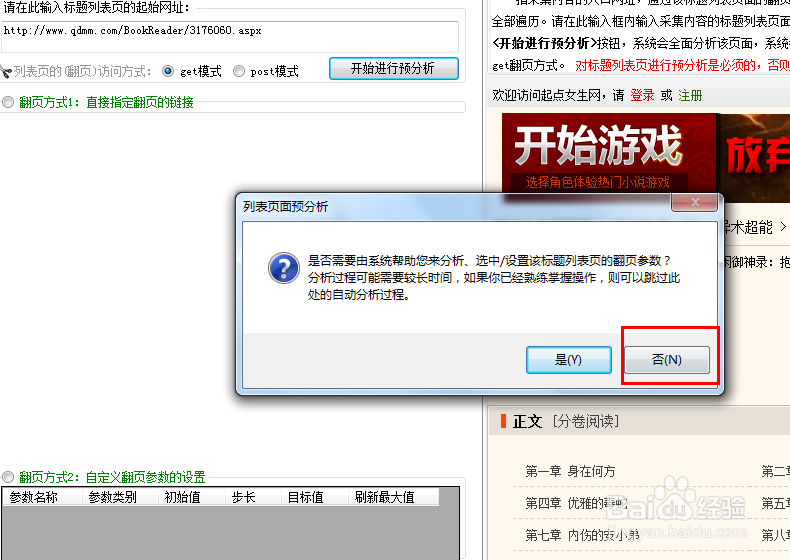
4、把上一步复制的网址粘贴到软件中的标题列表页的起始网址位置处,点开始进行预分析。
5、软件会询问是否需要自动进行翻页设置,因为这地方我们只采集这一页的上的链接,不需要翻页,选择否,保持默认设置,直接点击下一步。
6、然后是选择内容页,这个步骤就是告诉软件需要采集哪些链接里面的内容。我们在软件左边随便选择一个需要采集的链接。一般情况下软件会自动分析,和你所选择链接相似的链接都会被框选,由于各个网站千变万化,有时软件的自动框选并不准确,就像这里软件只选中了两个链接,显然不是我们想要的结果。
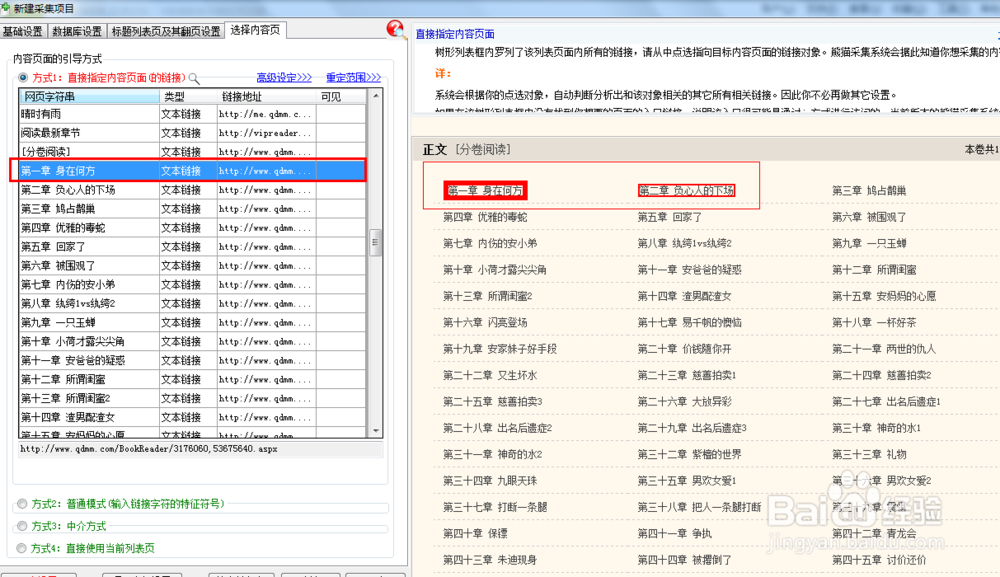
7、一般遇到这种情况情况我们可以首先点击软件右上方的 重定范围,如果一次不行,可以继续重试,每点击一次重试软件会扩大一次框选范围,当达到我们要求后点击取消按钮就可以了。

8、如果直到最后都没能达到我们预期,那么就需要到高级设置里进行微调。

9、点击软件上方的高级设定,打开高级设定的对话框,这里面可以进行的设置的选项还是挺多的,这里不一 一细说,后面准备弄个单独的文章来介绍这里。
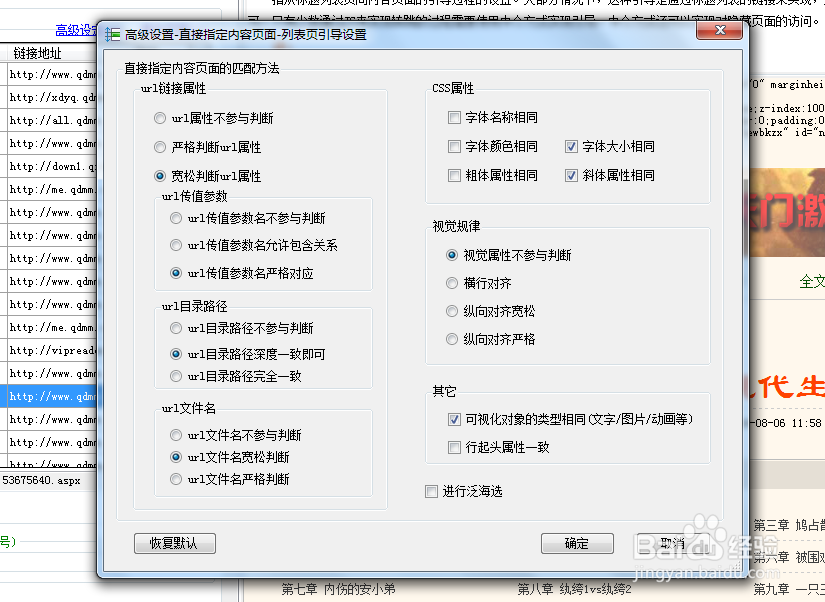
10、针对这个网站,我们把进行泛海选勾上,然后点击确定。
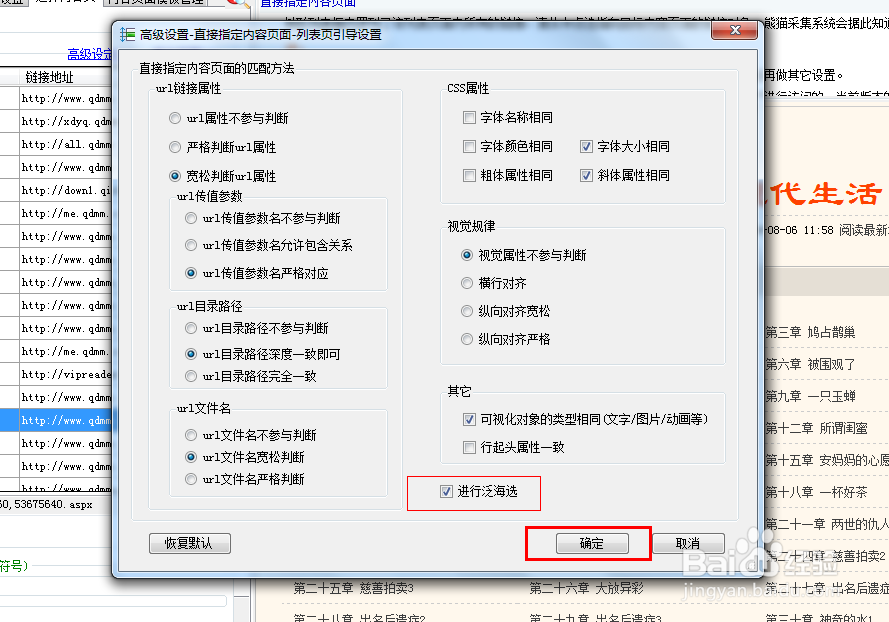
11、发现所有的章节都被自动框选上了,选择内容页设置完成,点击下一步设置进入下一步。
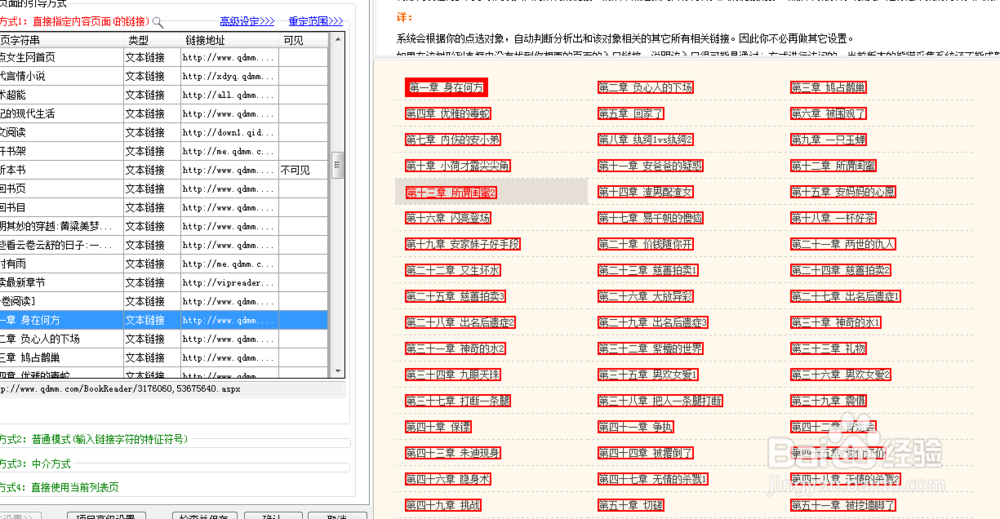
12、来到内容页面模板管理,直接点击添加新模板,会把我们在上一步选中的链接作为模板,这地方也可以自己选择一个模板,然后把网址粘贴到添加新模板按钮左边的文本框里,点击添加新模板。
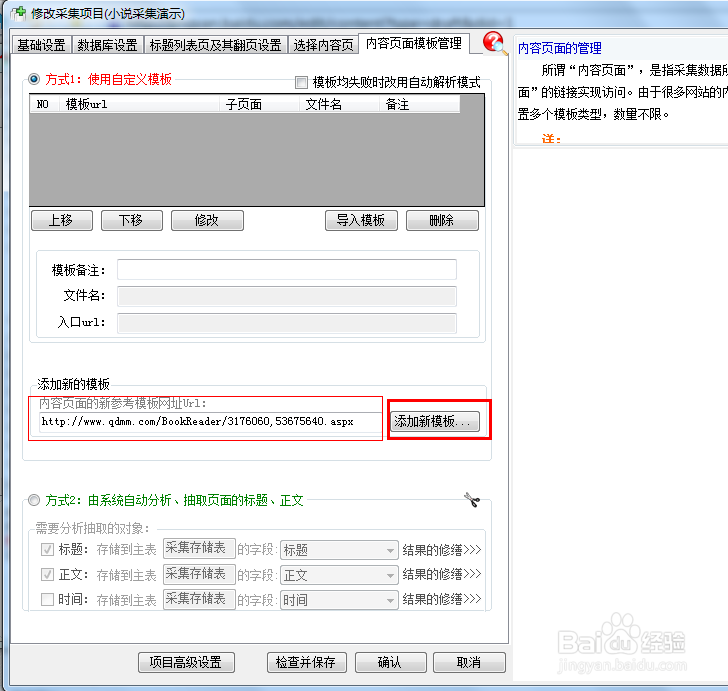
13、点击添加新模板之后会弹出一个设置模板的新窗口。点击软件上方的开始分析,稍等片刻之后软件会询问你是否需要软件自动提取标题正文,由于该功能只适用于新闻资讯类的简单采集,这里我们选择否。
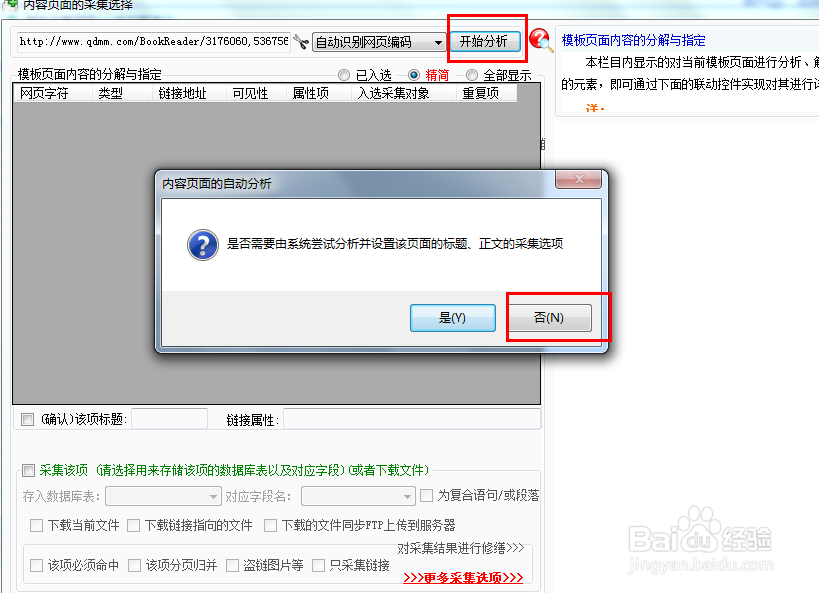
14、此时软件会根据模板页面的内容分析展示在软件的左边,但查看之后可以发现,左边模板页面内容的分析与指定区域只有标题信息,并看不到我们要的正文信息。

15、此时我们可以把模板页面的网址复制到浏览器打开,点击查看源代码,可以发现源代码中确实没有小说正文的内容,这说明正文是通过js脚本加载的,一番分析之后可以找到一个以.txt结尾的链接,这个就是实际正文所在的网址。
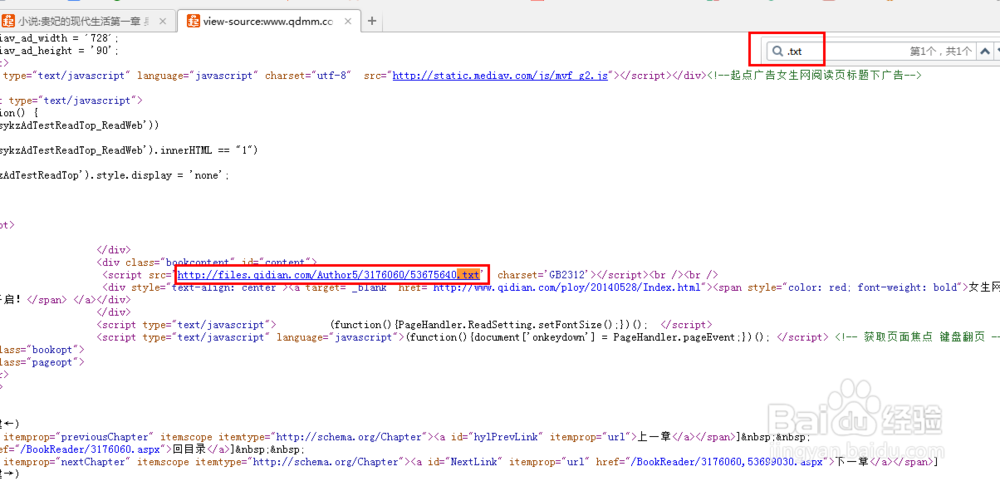
16、点击那个以.txt结尾的链接就可以看到完整的小说正文了。
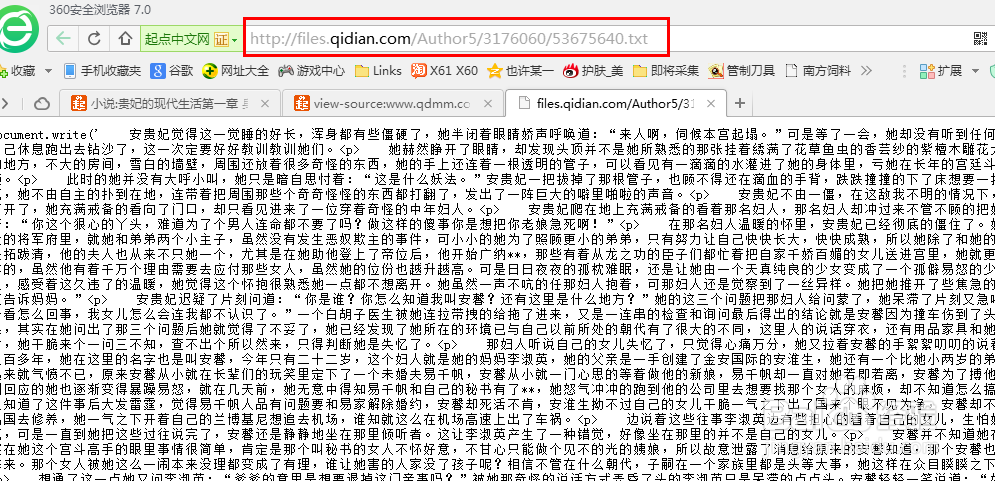
17、弄清了该网站的加载原理,接下来就是在软件中设置采集了。这是我们需要用到软件里面一个下级子页面的功能,简单说就是从当前模板页面调到另一个页面进行采集的功能。
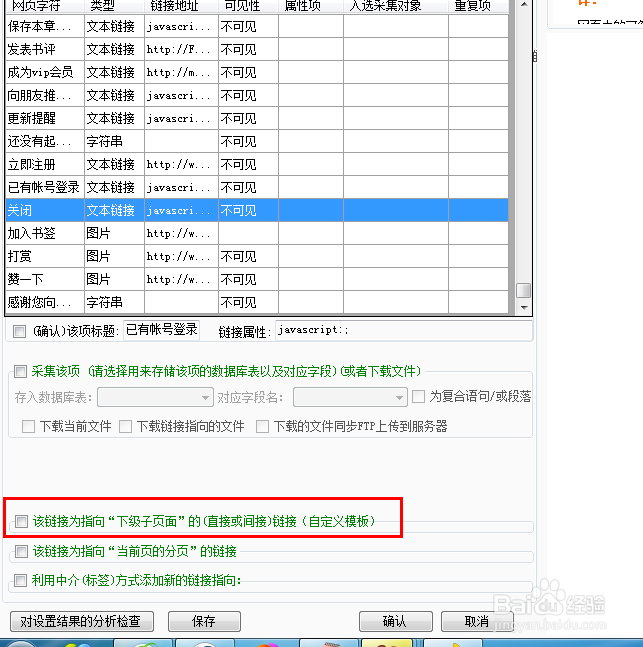
18、但由于这地方我们要的链接在网页中并不存在,我们还需要先自己添加一个这样的链接,软件有一个利用中介方式添加新的指向能够人为的在软件中添加一个新的链接。
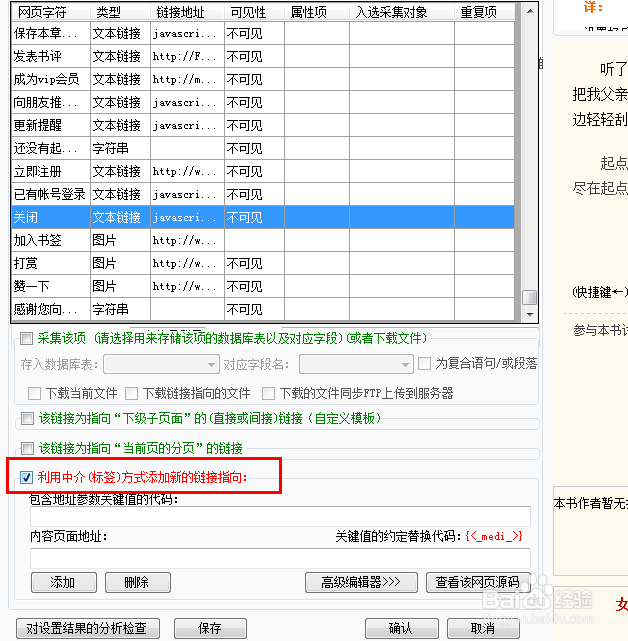
19、利用链接的前后特征字符构造出我们要的链接,然后点击添加按钮。
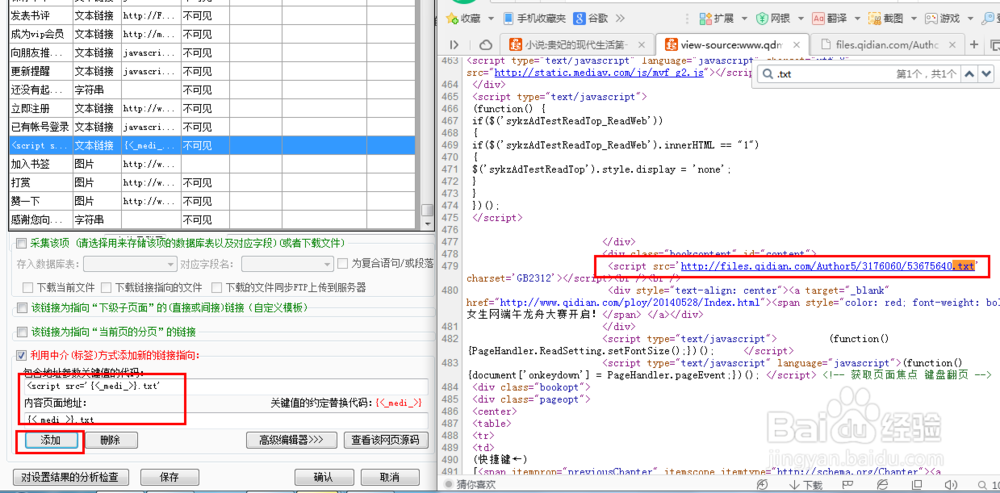
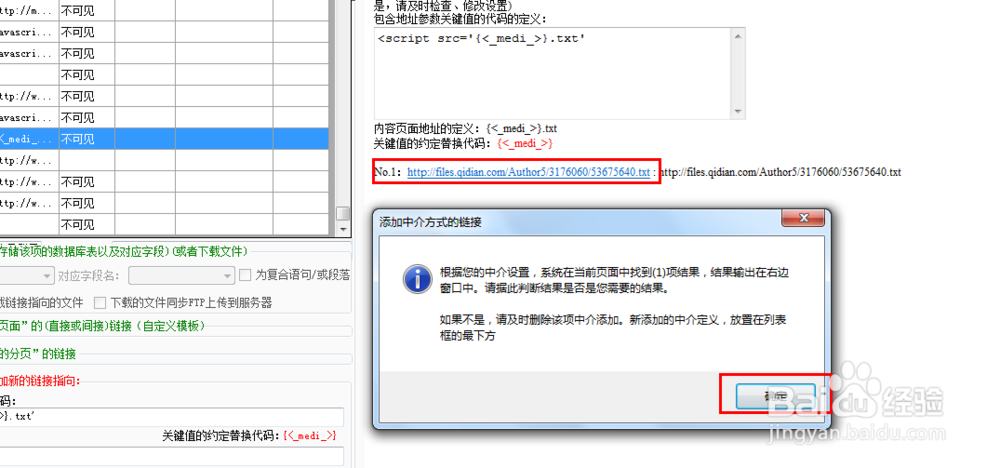
20、然后系统会让你确认中介设置是否正确,如果没有问题点击确定就可以。
21、这时我们软件左方的最下面会多出一个自定义链接,选中并作为下级子页面,然后点击分析该页面按钮,就会调到另一个页面进行采集。
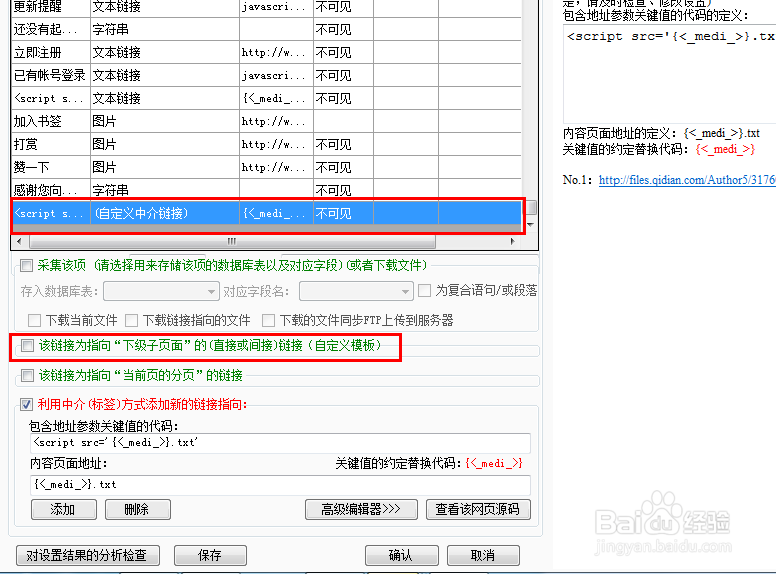
22、在此之前别忘了先把标题采集一下,注意每级页面保证至少采集一项内容,以避免不必要的问题。
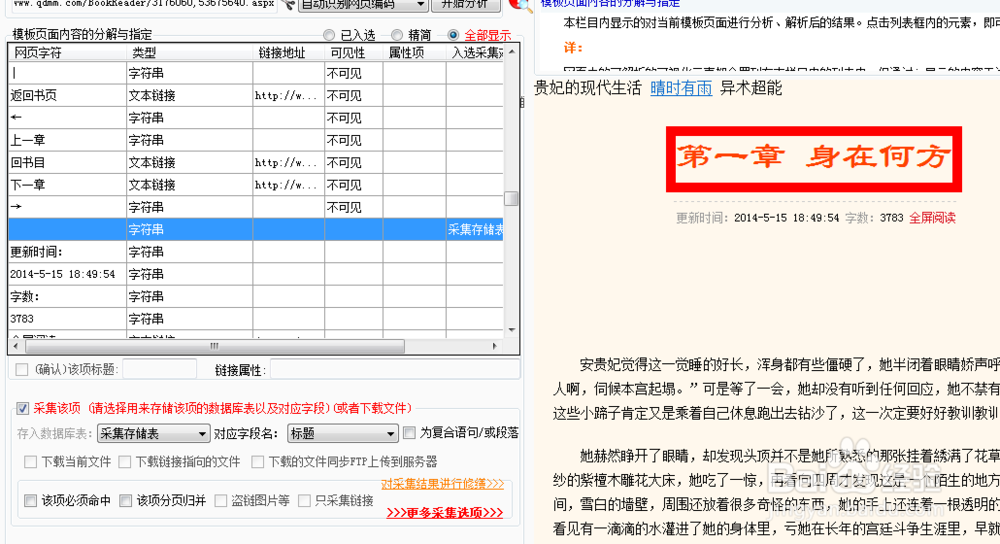
23、然后选中我们刚才添加的自定义链接,勾选该链接为当前页的下级子页面复选框,右边会出来分析该页面的按钮,点击该按钮可以跳转到下级页面的设置。
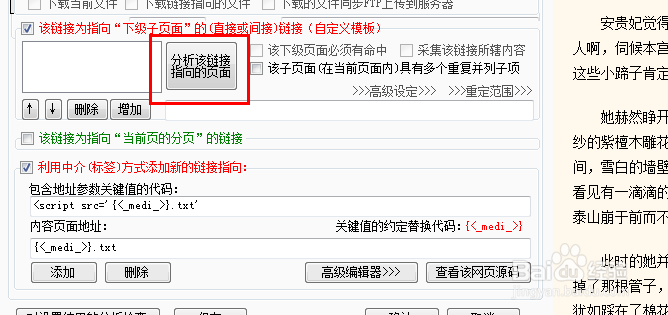
24、点击开始分析,小说的正文就全部出现了,完全采集就可以了。但这里我们选用另一种更简单方式来采集,直接采集网页的源代码,这样就不会漏采任何段落。
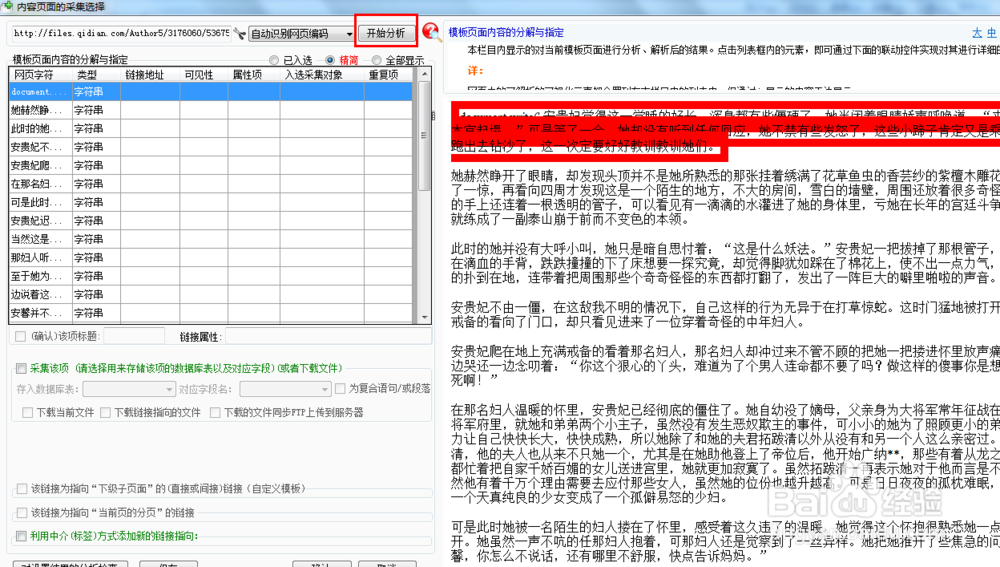
25、先随便设置采集一项,然后一路点击确定保存模板。注意:如果这里什么都不采集就点确定,系统会认为这是无效的模板,那么待会又要从新设置中介方式。
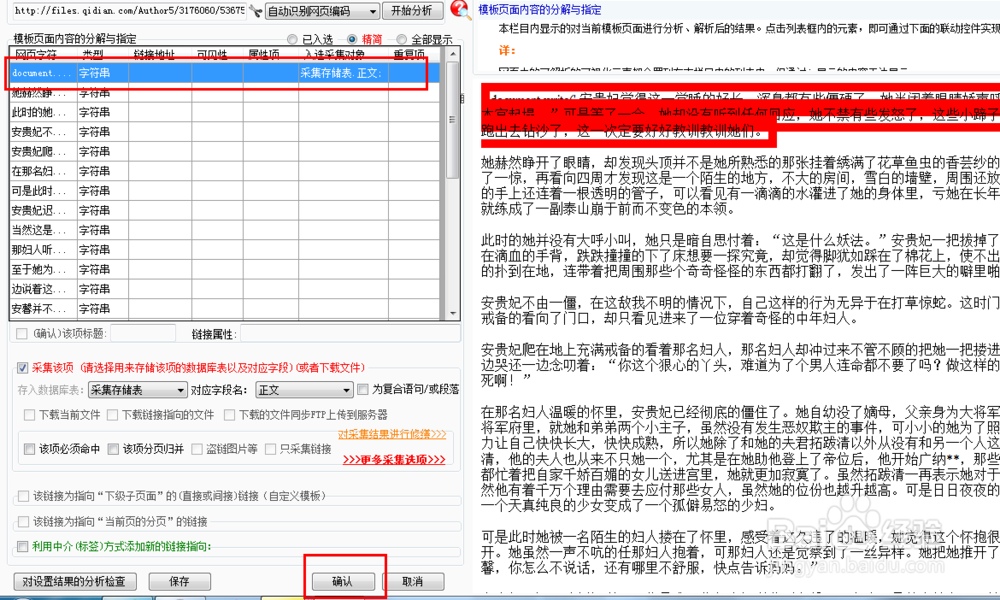
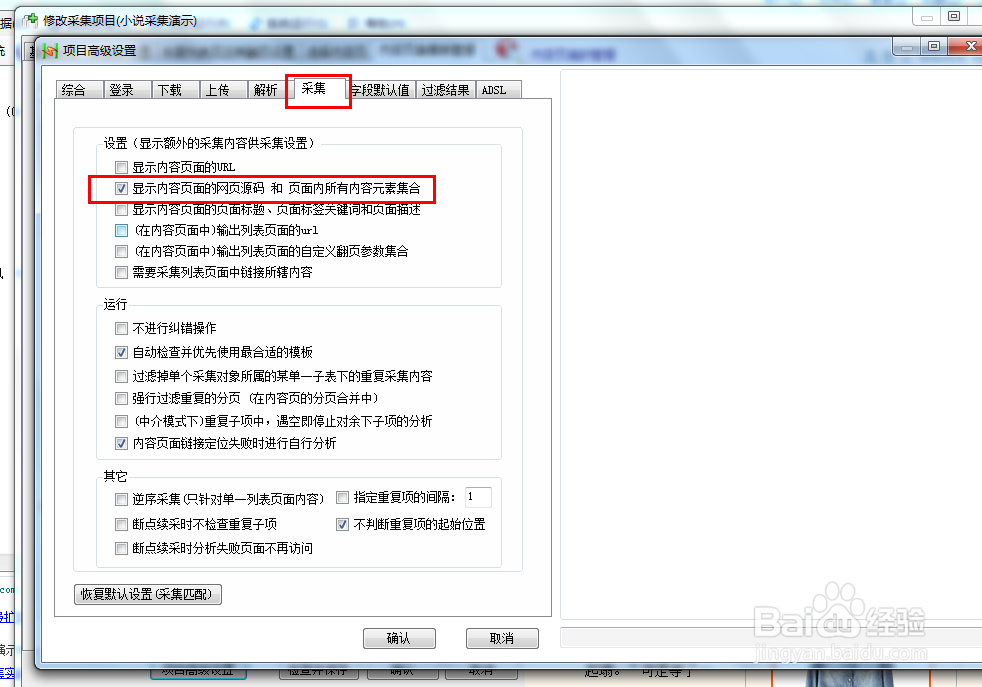
26、回到主界面,点击软件下方的项目高级设置。
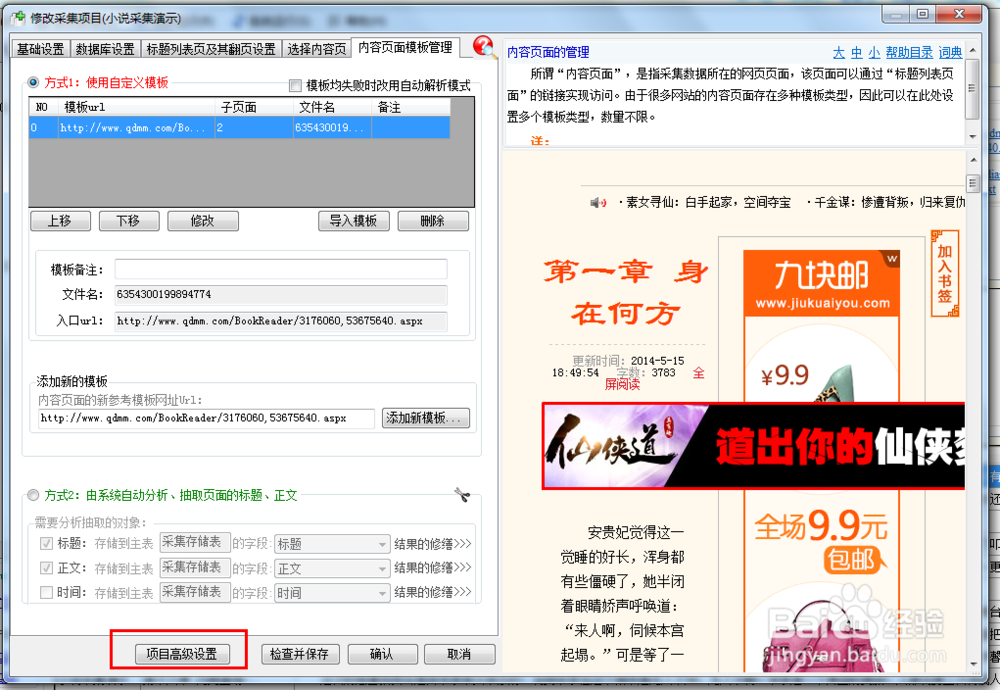
27、点击采集选项卡,勾选采集内容页面的网页源码选项,确认保存。
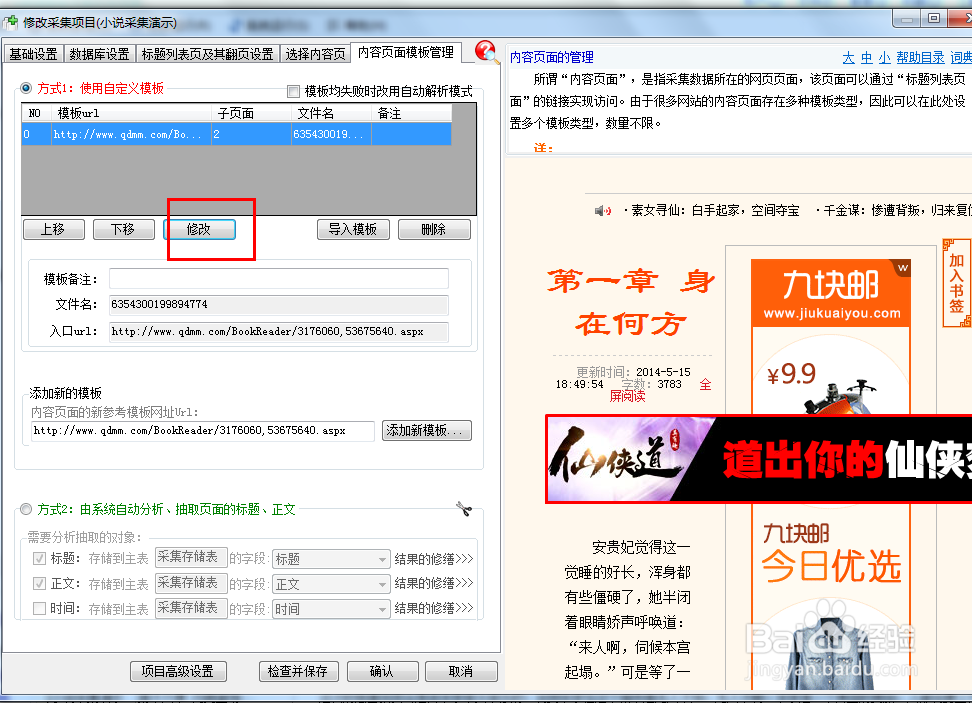
28、点击修改按钮来修改我们的模板。
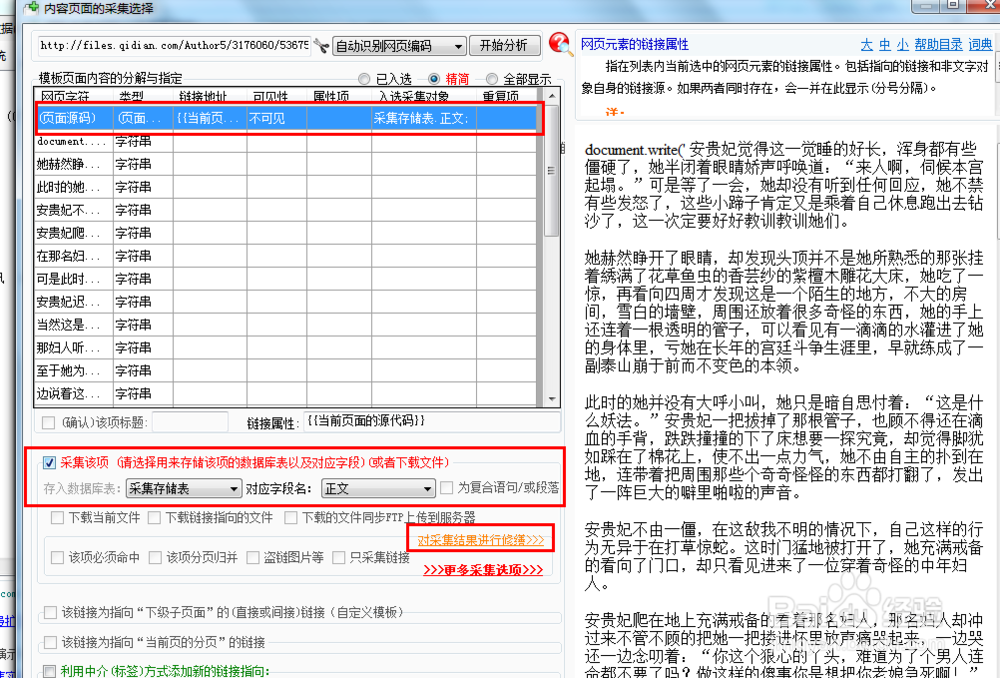
29、来到我们刚才采集小说正文的地方,可以看到上面多了一个网页源码的采集选项,选中采集。
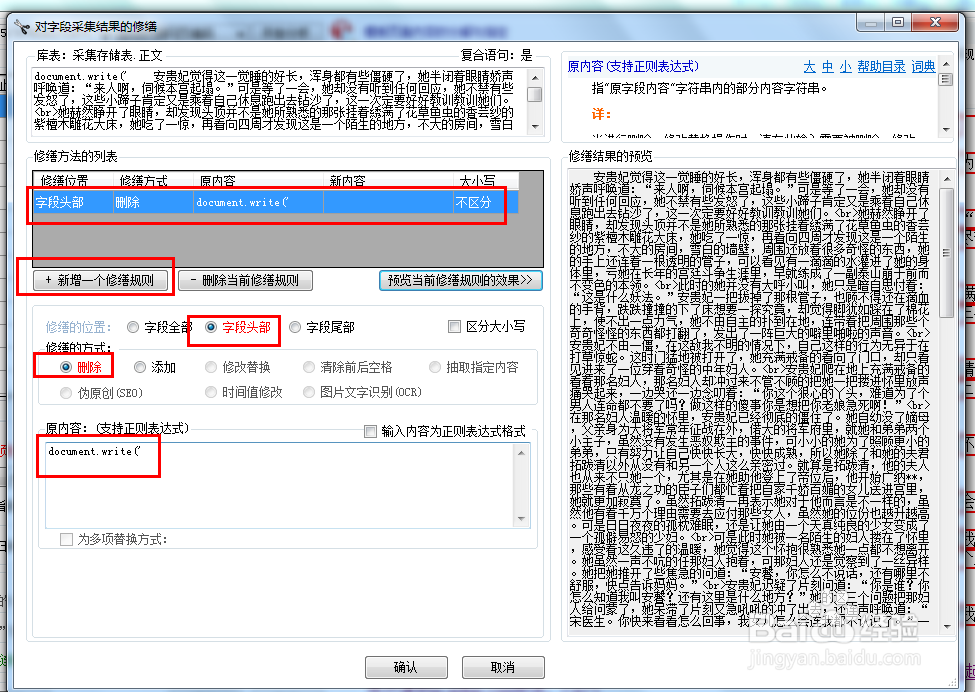
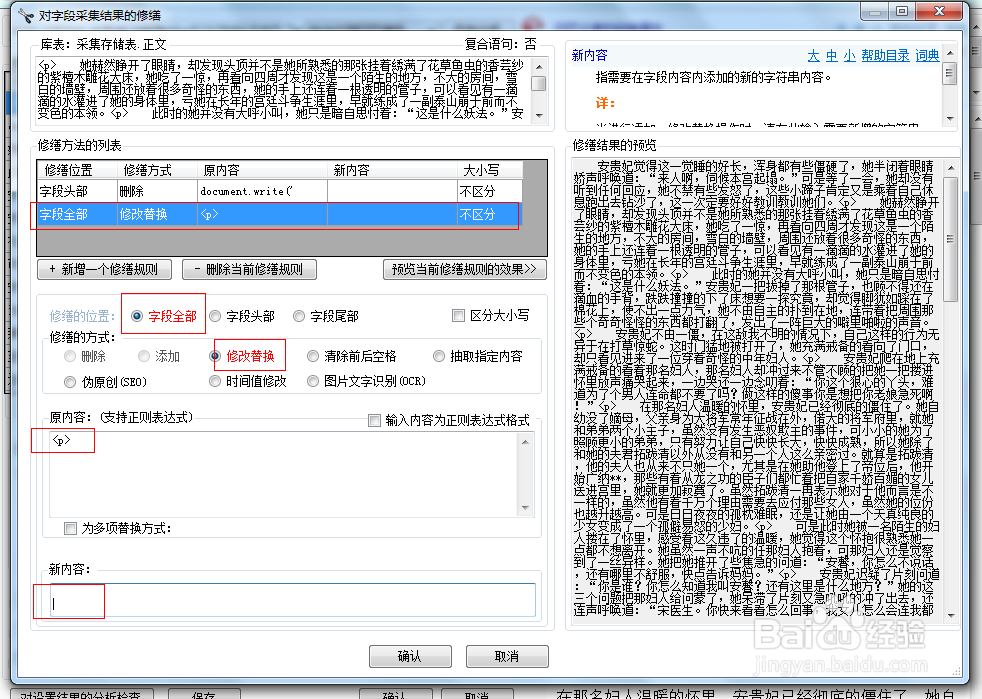
30、对采集结果修缮一下,去掉不要的内容。
31、如果不是发布到自己网站,而是要导出成txt文档,还可以把网页中的段落标记符""替换成实际的换行,如果是要发布到自己的网站,这步可以省略。
32、到此,采集设置全部完成,一路点击确定保存配置,然后可以点击运行按钮开始采集。
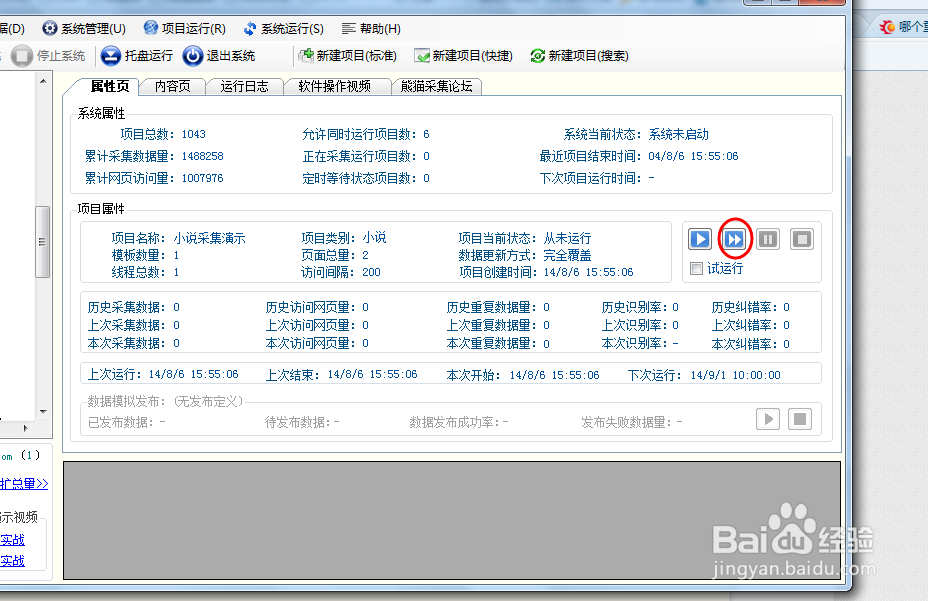
33、大约两三分钟之后,一部完整的小说就采集完成了。

34、采集完之后,点击软件上方的项目管理-->打开项目文件夹。
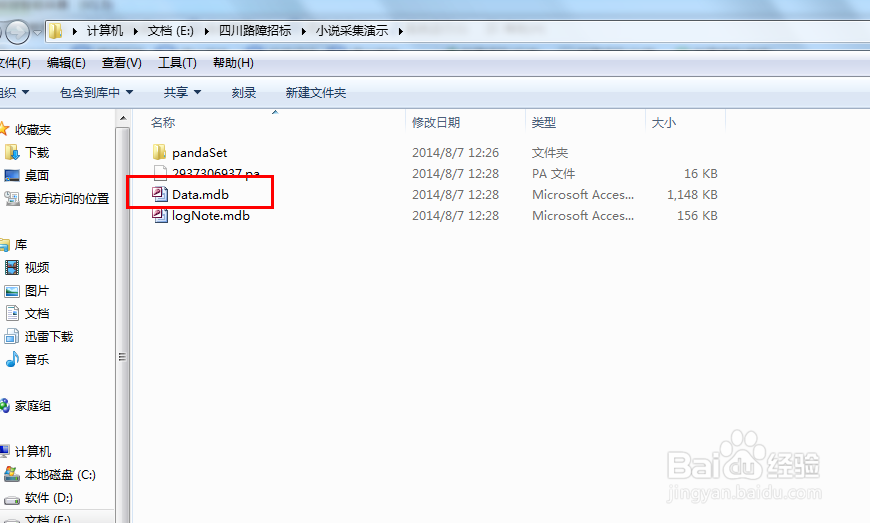
35、里面的data.mdb就是我们采集的数据存放的地方,可以用微软的excel打开(注意wps无法打开)。打开excel,直接把data.mdb拖到excel中就可以了。
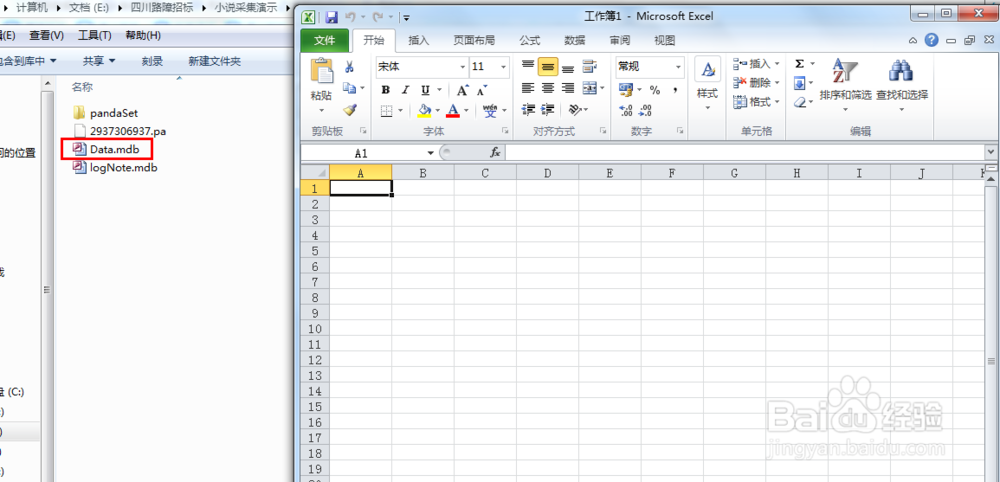
36、点击启用。

37、选择采集存储表,点确定。

38、选中标题和正文两列,复制到txt文件中。
39、有一点点不完美的地方,稍微编辑一下就ok了,小说的采集到此为止。
