keras 文本分类教程
1、首先,是词袋模型,由于计算机只能处理数字型的变量,并不能直接把文本丢给计算机然后让它告诉我们这段文字的类别。于是,我们需要对词进行one-hot编码,假设我们总共有N个词。
2、然后,对词进行索引编码并构造一个N维零向量,如果这个文本中的某些词出现,就在该词索引值位置标记为1,表示这个文本包含这个词。

3、然后,是共现矩阵,为了使用上下文来表示单词间的关系,也有人提出使用基于窗口大小的共现矩阵,但仍然存在数据维度大稀疏的问题。
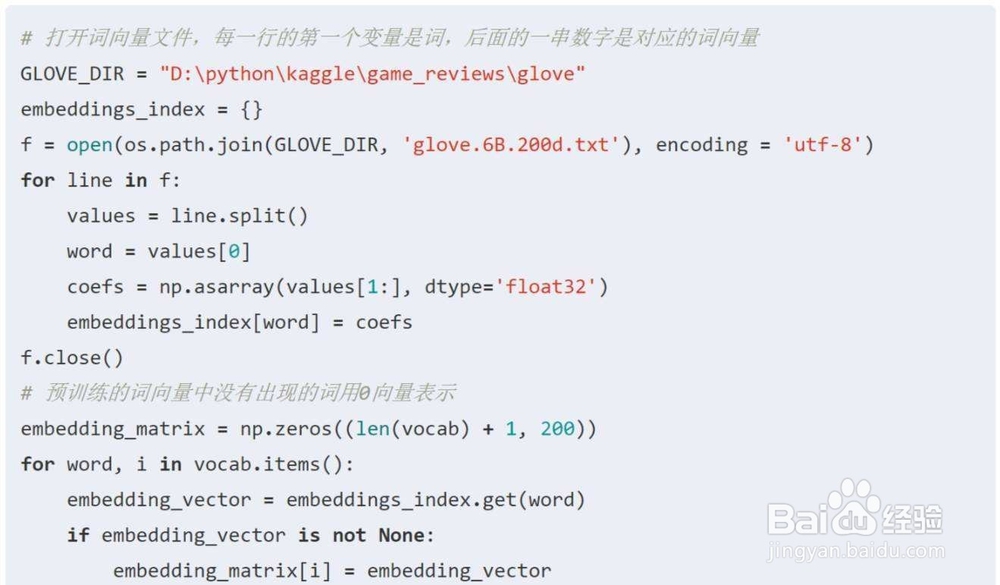
4、然后,是TF-IDF 用以评估一字词对于一个文档集或一个语料库中的其中一份文档的重要程度,是一种计算特征权重的方法。核心思想即,字词的重要性随着它在文档中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。有效地规避了那些高频却包含很少信息量的词。我们这里也是用TF-IDF 对文本变量进行特征提取。

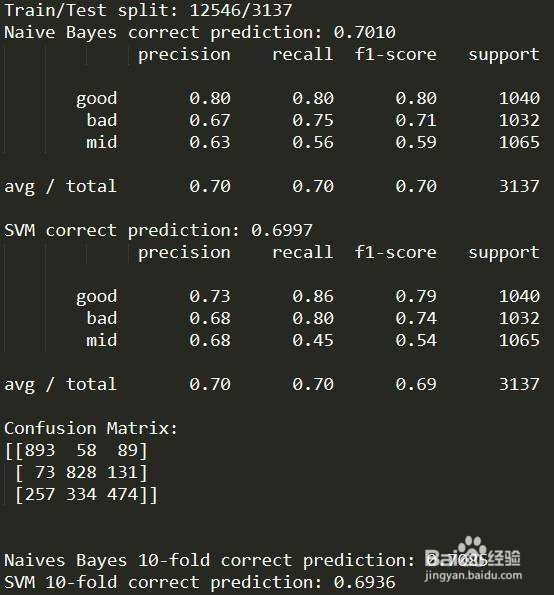
5、然后,分类器就是常见的机器学习分类模型了,常用的有以下两种,这里我不再赘述这两个模型的原理了。朴素贝叶斯:从垃圾邮件识别应用开始被广泛使用,支持向量机,很通俗地解释了SVM的工作原理。

6、最后,使用Scikit-Learn库能够傻瓜似的来实现你的机器学习模型,我们这里使用TfidfVectorizer函数对文本进行特征处理,并去除停用词,模型有多类别朴素贝叶斯和线性SVM分类器。结果很不令人满意,NB模型结果稍好,准确率为28%,领先SVM 1%。下面我们来看看深度学习模型强大的性能。
声明:本网站引用、摘录或转载内容仅供网站访问者交流或参考,不代表本站立场,如存在版权或非法内容,请联系站长删除,联系邮箱:site.kefu@qq.com。
阅读量:132
阅读量:161
阅读量:47
阅读量:77
阅读量:174