潜类别分析模型(LCA)(2)
1、在mplus中做潜类别分析的时候我们需要做很多的模型,从类别为1到类别k的时候模型的LMR或者是BLRT的P值不显著为止,然后我们比较每个模型的参数结果
2、如下图,我们可以看到如何得到这些值,我在上一节中已经将结果部分的相应的部分进行截图给大家,有不理解的参考上一节的内容。
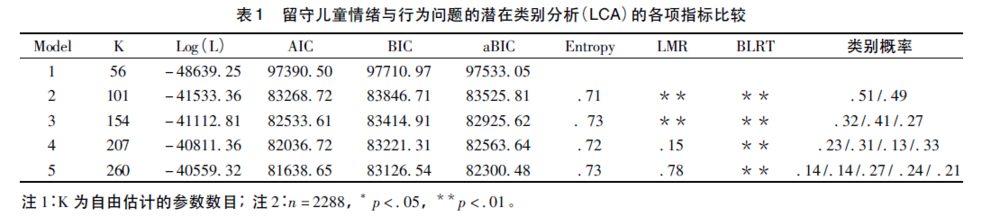
确定模型类别个数 从表1 可知,随着分类数目的增多,似然比Log( L) 和信息指数AIC,BIC 以及aBIC(调整后的BIC) 也不断的减小,但是保留3 个类别时的Entropy 值是最高的。此外,保留3 个类别的时LMR 值能达到非常显著的水平( p ﹤ . 01) ,而4 个类别的分类时LMR 值不再显著,即根据LMR 指标来看,3个潜类别的模型明显优于2 个潜类别的模型,4 个潜在类别模型相比较3 个潜类别的模型而言没有优势。nylund,Asparouhov和Muthen( 2007) 在对数据进行蒙特卡洛模拟研究时发现,LMR 值是对潜在类别的分类最为敏感的指标,由此我们可以考虑选择3 个潜在类别的分类( C1,C2,C3).
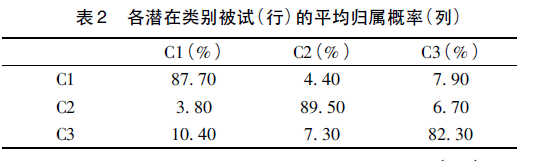
3、归属概率矩阵 然后我们需要画出对于确定好类别的归属概率矩阵,以便说明模型分类的结果是可信的。如下图所示是文章当中的表格。
从表2 可知,每个类别中的留守儿童( 行) 归属于每个潜在类别的平均概率( 列) 从82. 3%到89. 5,这说明3 个潜在类别分类模型的结果是可信的。
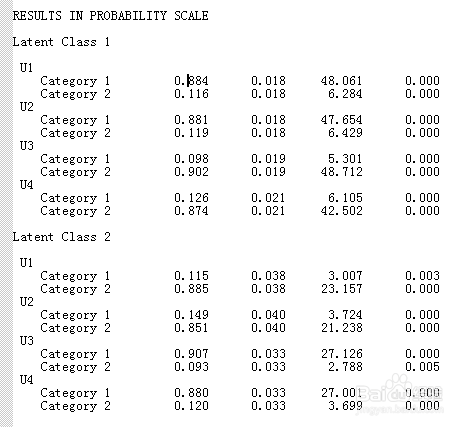
4、然后接着画出3个潜在类别在各个条目上的应答概率。拿muthen网站上的二分类变量的数据进行举例,告诉大家如何画这个应答概率图。首先我们在output中找到如下图所示的结果,这个就是概率的结果,在本例中category1是得0分的,category2是得1分的。所以我们看到在第一个latent class中U1变量得1分的占11.6,u2中占11.9,依次类推,建立如下图2的excel表格,然后画图,如下图3所示,可以看出class1基本上是U3,U4得分为主,class2基本上是U1,U2为主
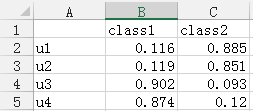
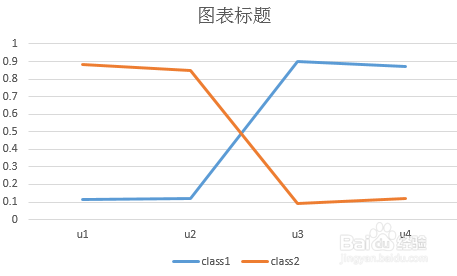
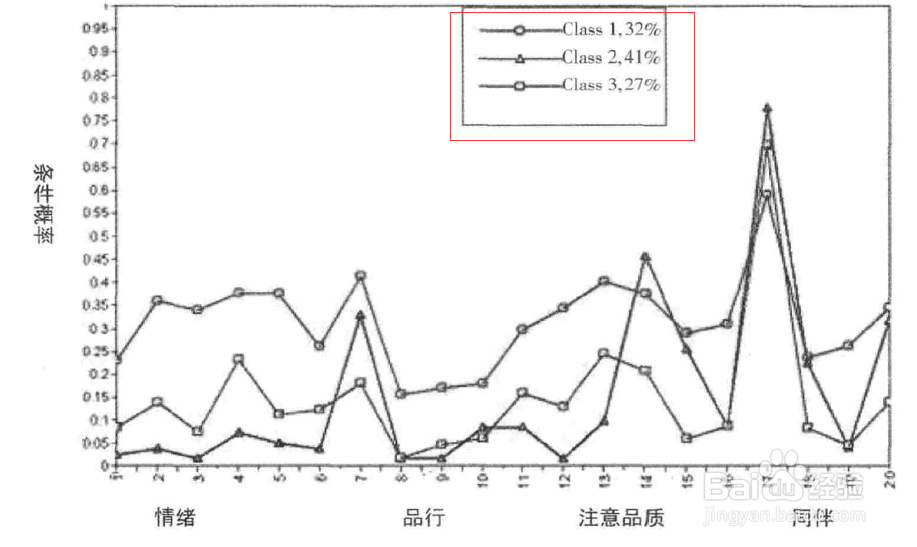
5、我们可以同时看一下在论文当中的表格是如何呈现的。红色框住的地方我们可以在output当中找到,如下图二所示的结果所对应。