Sql Server 2008 Group by的使用方法
1、我的电脑是Windows7 64位,所以我安装的是Sql server2008 r2(64位).
大伙安装的时候也一定要记得看一下自己的操作系统是多少位.你是32位操作系统的就安装32位的Sqlserver 版本不限制. 2005 2012都可以.
2、你安装好之后在开始菜单里面找.
找到之后可以创建一个快捷方式到桌面.
我已经截图把位置告诉你了.

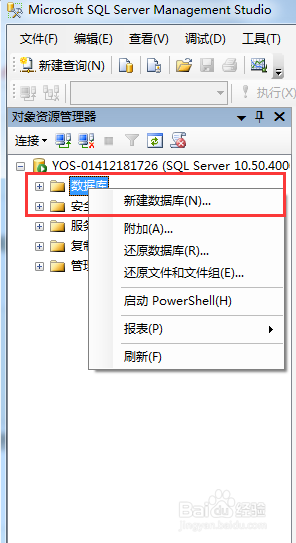
3、如果没什么问题的话,你点击连接就进去到数据库里面了.
右键新建.
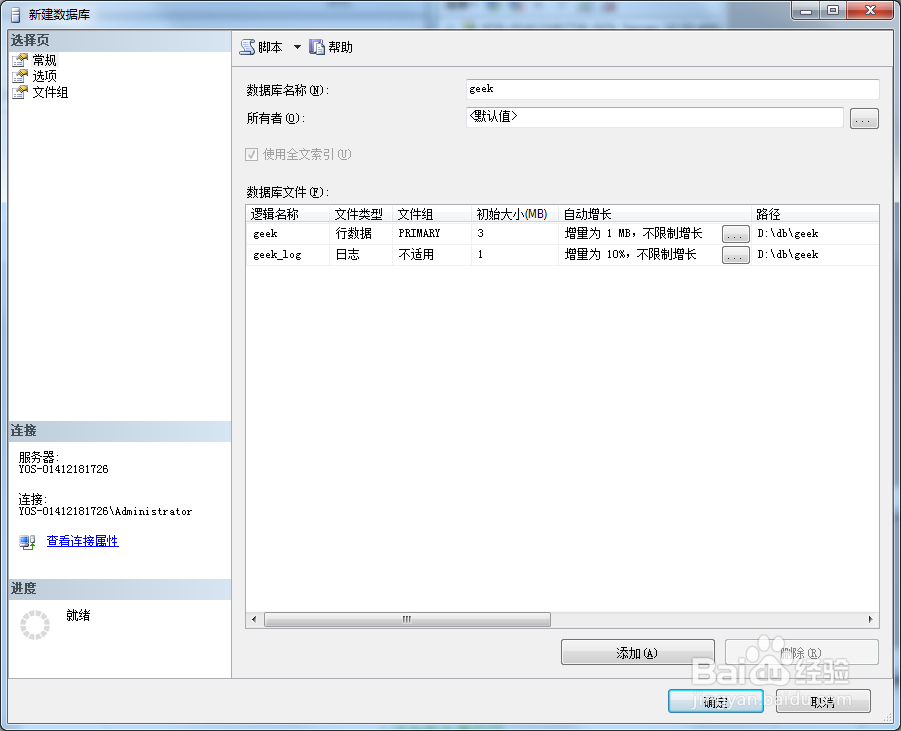
4、弹出这个对话框,按照图片中的设置.
记得路径保存到其他盘,自己新建一个文件夹.
放到C盘,如果数据库文件大了,会拖慢整个电脑的运行.
5、大家看我保存到这个文件夹下,就多了两个文件.
我们所有关于这个数据库的操作,将来其实都是对这两个文件的操作.

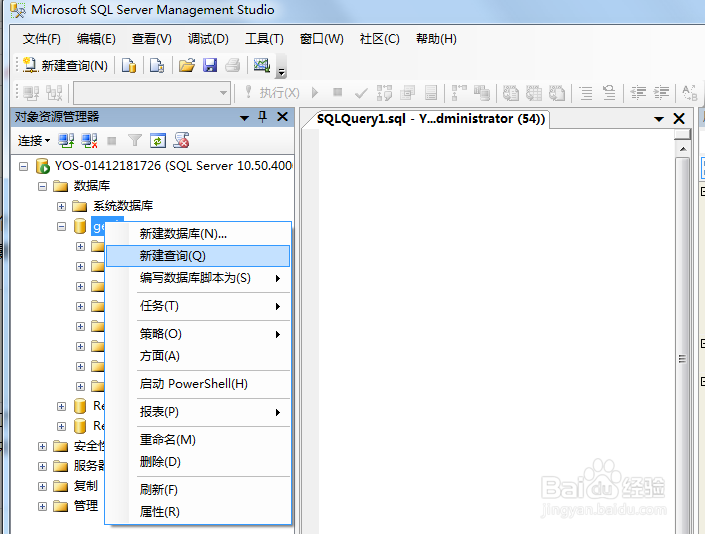
6、在我们刚刚新建的数据库上点击右键查询,我们要用Sql语句创建一个表我们再写几条插入数据的数据.
写上一个创建表的 sql语句. 当然,我们也可以用设计图创建.
当然我下面的写法只支持sql server2008数据库以上的写法.
create table Person
(
id int,
name nvarchar(5),
sex char(2),
age int,
job nvarchar(20)
);
insert into Person (id,name,sex,age,job)
values
(1,'李小明','男',25,'C#程序员'),
(2,'王小红','女',19,'学生'),
(3,'李小明','男',22,'学生');

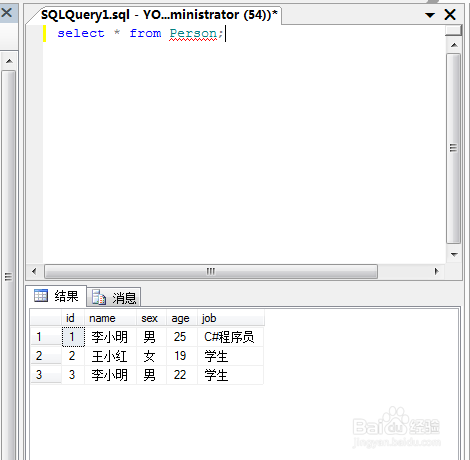
7、我们用一条查询语句,把刚才的数据都查询出来.
select * from Person;
可以看到图中所显示的数据.
8、那么我们现在就要使用group by这个语句了.
这是一个分组的语句,我们先看一下它的写法.
select name from Person group by name;

9、从上面的结果我们不难看出,我们根据姓名进行了分组.
另一种说法其实就是把重复的过滤了.
比如我数据库里面有50个人都输入了公司.
我如果对公司这个字段group by就可以知道这50个人到底一共归属几个公司.
我们上面的sql语句,其实是把第二列独立出来,并且把重复的过滤出去了.
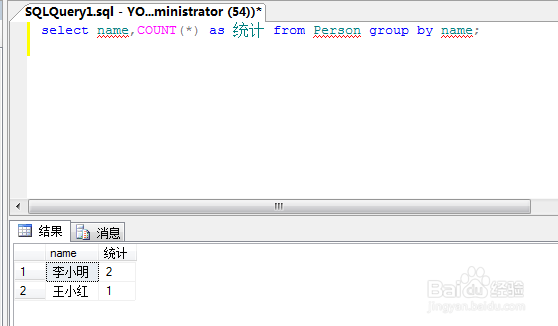
10、我们再来写一个聚合函数. 字面意思就是把一些重复的东西聚集起来,并且显示出有多少个.
select name,COUNT(*) from Person group by name;
可以由下图很明显的得知聚合函数的意义和好处.

11、当然,我们还可以再给系统自己生成的列重新起个名字.
select name,COUNT(*) as 统计 from Person group by name;
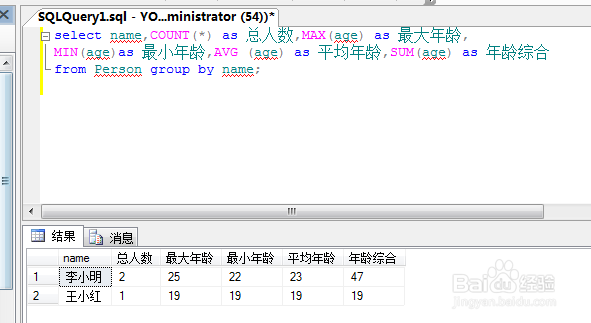
12、select name,COUNT(*) as 总人数,MAX(age) as 最大年龄,
MIN(age)as 最小年龄,AVG (age) as 平均年龄,SUM(age) as 年龄综合
from Person group by name;
再来个更强大的功能.看看我们的sql语句.
13、当然,我们可以再里面增加几条数据,再加大家一个更强大的用法.
大家也跟我一样,再增加几条数据.
那么我们现在把姓名出现过2次或者2次以上的查询出来.

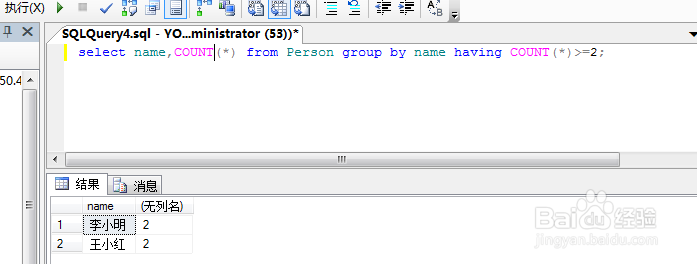
14、select name,COUNT(*) from Person group by name having COUNT(*)>=2;
通过having和聚合函数的配合,我们就得到了想要的结果.
15、其他更强大的sql语句写法,我们在下一篇中介绍学习.