如何java写/实现网络爬虫抓取网页
1、首先,在我们动手写代码之前,我们先要想清楚这个爬虫要具备什么功能才可以把网页爬取下来,还有爬虫要采用什么数据结构来实现?能否控制爬虫自动重启?

2、思考完以上问题之后,我们需要确定要写几个类来实现这些功能,这样我们就得把爬虫的几个类的功能用图来表示一下,在这里小崔只实现基本的功能,所以画的图比较简单,但是如果大家把这个搞懂的话,在自己添加需要的特定功能即可。

3、下面我们要根据我们要解决的问题,一个一个来设计我们的各个类。我们的问题主要有:
①.如何下载一个网页②.如何从一个网页中提取URL③.如何构建URL队列④如何让爬虫开始工作

4、第一个问题,解决如何下载网页

5、这里我们要用一下第三方的开源包来完成此功能,因为java自带的实现此功能的包不太好用,请自行百度将此包下载下来。包的名称为HttpClient。
6、可能很多朋友还不知道这个包该怎么用,为了减少大家的麻烦,节省大家的时间,小崔在这里给大家介绍一下这个包的用法。
(1)通过get的⽅方式获取到Response对象。(2)获取Response对象的Entity。(3)通过Entity获取到InputStream对象,然后对返回内容进⾏行处理。

7、可能很多新手只对我这么一说不能深切的体会到其中的内涵,下面我将其以代码的形式展现出来。
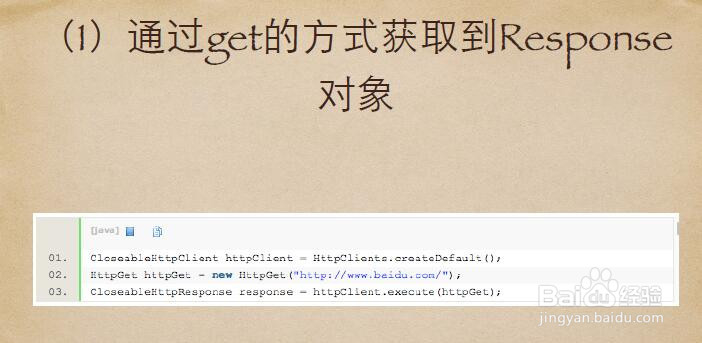
8、下面是获取Response对象的Entity的代码示例

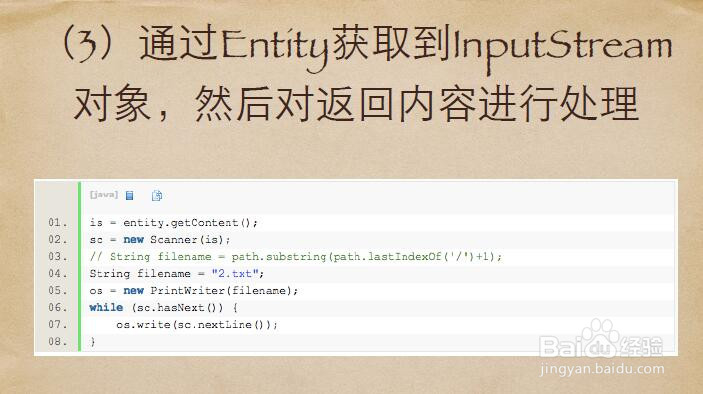
9、通过Entity获取到InputStream对象,然后对返回内容进⾏行处理
10、好了,第一个问题我们就解决了,下面我们来解决第二个问题,如何从⼀一个⺴⽹网⻚页中提取URL

11、提取URL,这里我们还是使用一款第三方的开源jar包,Jsoup是一款Java的HTML解析器,可以直接解析某个URL地址、HTML文本内容,它提供了一套非常省力的API,可以通过DOM、CSS以及类似于JQuery的操作方法来取出和操作数据。

12、利⽤用JSOUP从⽂文件中加载网页File input = new File("D:/test.html");Document doc = Jsoup.parse(input,"UTF-8","网址/");请⼤大家注意最后⼀一种HTML ⽂文档输⼊入⽅方式中的parse 的第三个参数,为什么需要在这⾥里指定⼀一个⺴⽹网址呢(虽然可以不指定,如第⼀一种⽅方法)?因为HTML ⽂文档中会有很多例如链接、图⽚片以及所引⽤用的外部脚本、css⽂文件等,⽽而第三个名为baseURL 的参数的意思就是当HTML ⽂文档使⽤用相对路径⽅方式引⽤用外部⽂文件时,jsoup会⾃自动为这些URL 加上⼀一个前缀,也就是这个baseURL。例如<a href=/project>开源软件</a> 会被转换成<a href=⺴⽹网址>开源软件</a>。

13、下面是解析并提取HTML 元素实例代码

14、下面我们来解决第三个问题,如何构建URL队列

15、要想构建URL队列,我们首先需要对爬虫中的队列进行分析,爬⾍虫中的队列分析如下:①初始种⼦子队列②爬⾍虫开始的地⽅方③只使⽤用⼀一次④ArrayList⾜足矣⑤待爬取队列⑥每次从队列取出URL去爬⑦爬过的URL需要从队列中删除⑧LinkedList⑨已爬取队列每次爬取过的URL要添加到队列中每次从网页中发现新的URL时,要判断该URL是否已经存在于已爬取队列(查找),如果不存在,则将该URL添加到待爬去队列Hashtable

16、解决完这些问题,一个简单的爬虫就完成了,下面就可以让你的爬虫开始工作了,如果需要某些特定的功能,自己在类里实现相应的功能即可。
