python使用requests爬取网页出现中文乱码
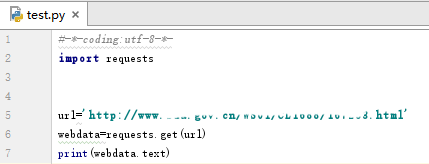
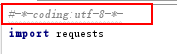
1、演示代码如下,在爬取中文网页时,会发现返回结果中的中文为乱码。
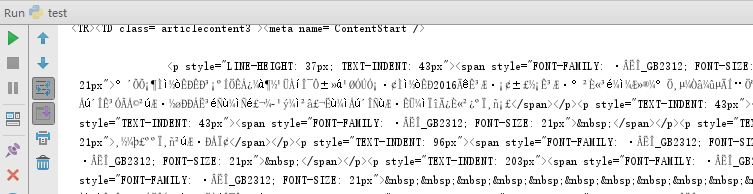
2、在浏览器中,在待爬取网页上右键单击,选择“查看页面源代码”。可以在HEAD中看到页面的编码为‘GBK’。

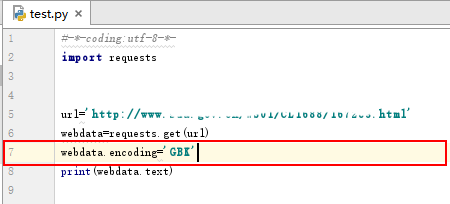
3、在代码中添加一行,指定requests对象encoding值为‘GBK’。
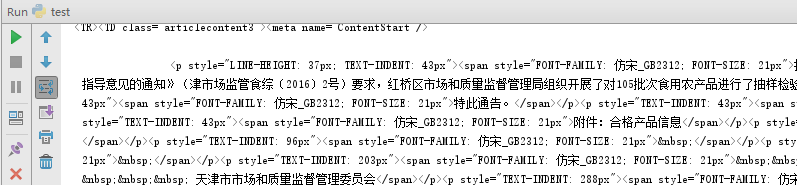
4、再次执行,可以发现返回的页面文本中,中文已正常编码显示:
5、以上代码在python3中测试。Py3.X源码文件默认使用utf-8编码,这与python2不同。Python2还要注意在代码开始指定代码的默认编码。
声明:本网站引用、摘录或转载内容仅供网站访问者交流或参考,不代表本站立场,如存在版权或非法内容,请联系站长删除,联系邮箱:site.kefu@qq.com。
阅读量:154
阅读量:50
阅读量:42
阅读量:115
阅读量:46