如何识别PDF扫描件中的文字
1、打开PDF文档,选择工具“转换->OCR->当前文件”
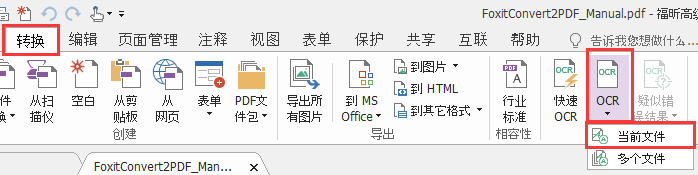
2、在弹出的属性设置中,选择要识别的页面范围,语言要选择当前文档中包含的语言中,默认是勾选“简体中文”和“英文”。
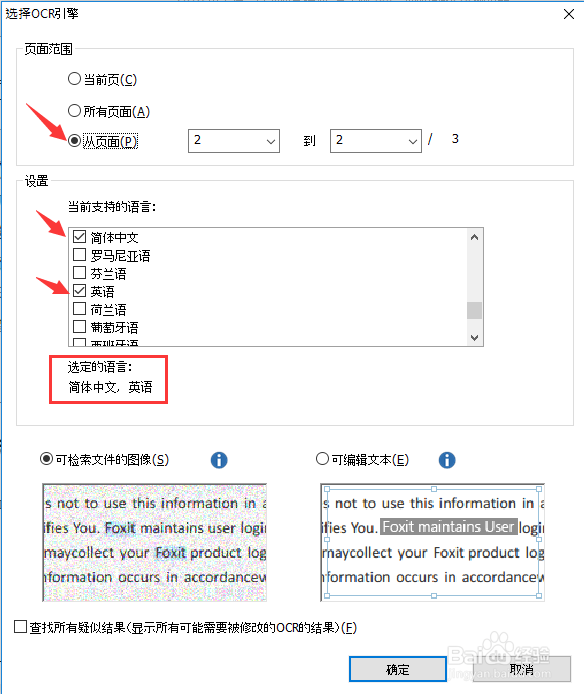
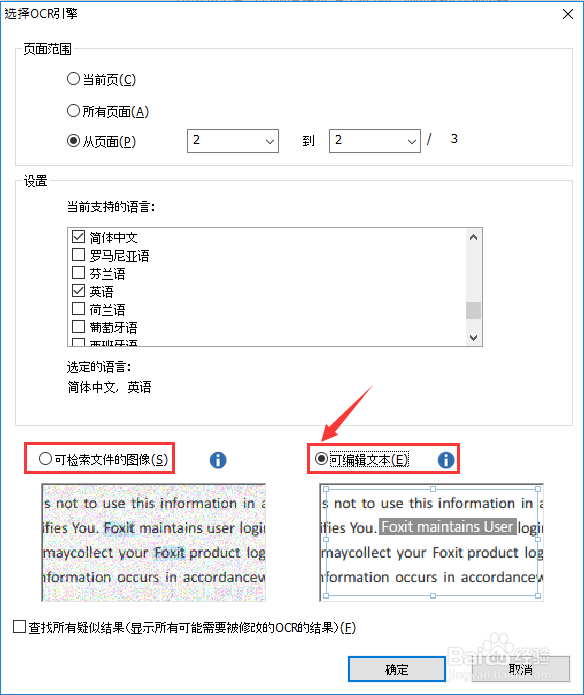
3、PDF文档文字识别有两种结果,一种是只可以搜索文本信息,保留当前排版;另一种是即可搜索文本信息,还可以编辑文本信息。
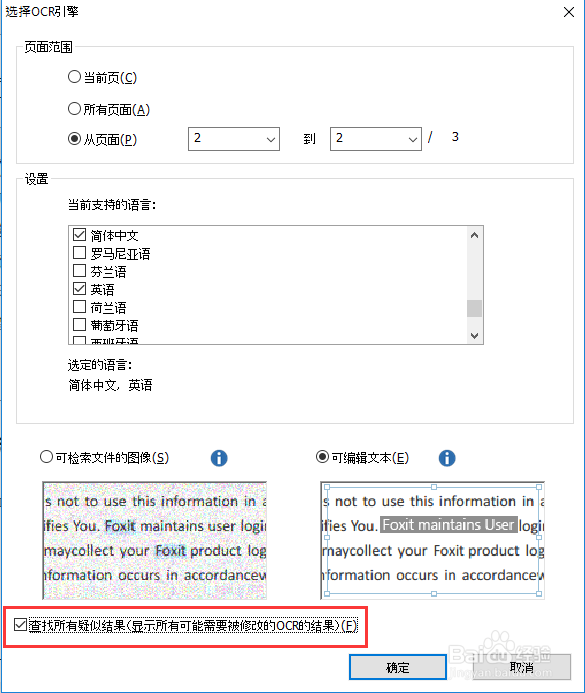
4、同时,在当前设置中,还可以勾选“查找所有疑似结果”。若有勾选,会在识别完成后,提示所有疑似结果。
5、文字识别完成后,程序会自动提示,“OCR识别疑似错误”,如果确实识别有错误,可以手动输入正确内容
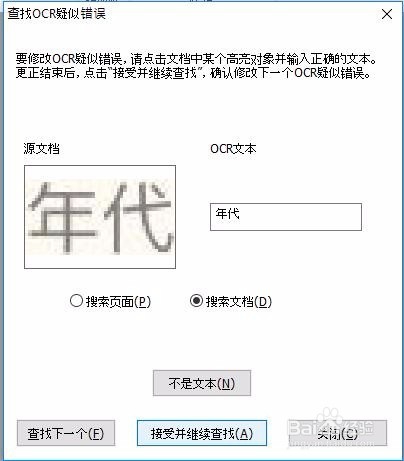
6、确认完所有 “OCR识别疑似错误”后,即可得到可编辑的PDF文档

声明:本网站引用、摘录或转载内容仅供网站访问者交流或参考,不代表本站立场,如存在版权或非法内容,请联系站长删除,联系邮箱:site.kefu@qq.com。
阅读量:87
阅读量:195
阅读量:188
阅读量:161
阅读量:107