spark的安装与配置
1、百度搜索Spark,找到【Downloads | Apache Spark】点击进入Spark官方下载页面

2、点击选择你的hadoop版本所对应的Spark版本,(这里我下载的版本是spark-2.3.3-bin-hadoop2.7.tgz)点击椭圆圈中的信息
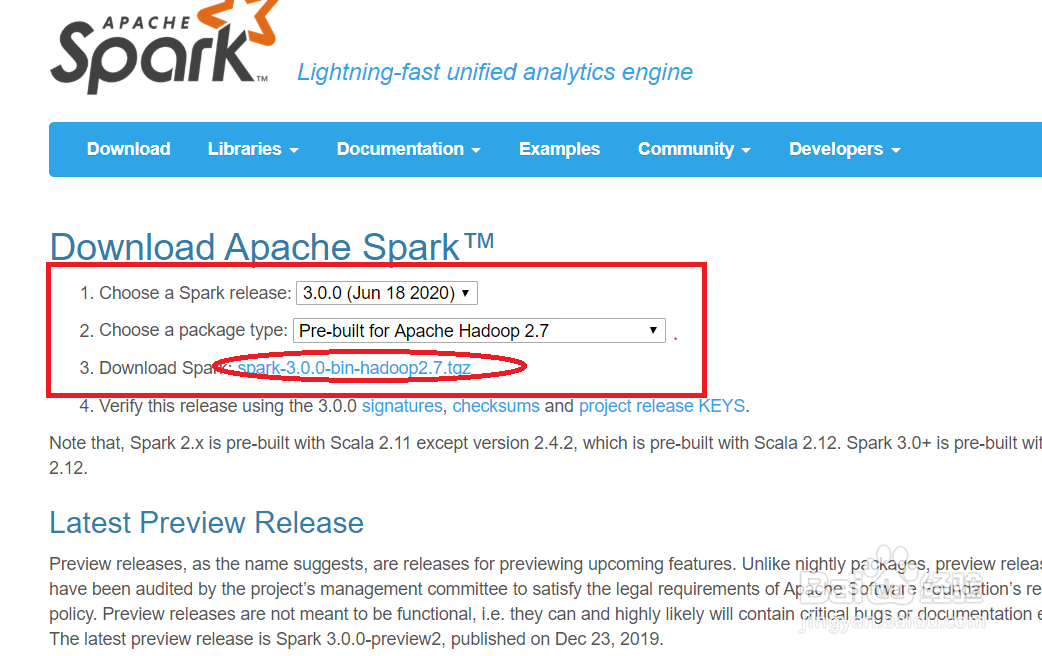
3、这里点击第一个,选择要安装的目录


4、将下载好的spark压缩包通过U盘传到Ubuntu系统下
(因为我将一台电脑装成了Ubuntu系统,没有用到虚拟机,所以我用的U盘来传文件)
5、将下载 spark-2.3.3-bin-hadoop2.7.tgz 文件文件移到/opt目录下并解压

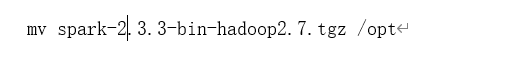
6、重命名文件(这里我命名的文件名是spark)

7、编辑/etc/profile文件,添加环境变量(不要忘了source)

1、编辑spark-env.sh文件(vim ./conf/spark-env.sh),在第一行添加以下配置信息:

2、验证Spark安装和配置,通过运行Spark自带的示例,验证Spark是否安装成功

3、运行结果如下图所示,可以得到π 的 14位小数近似值

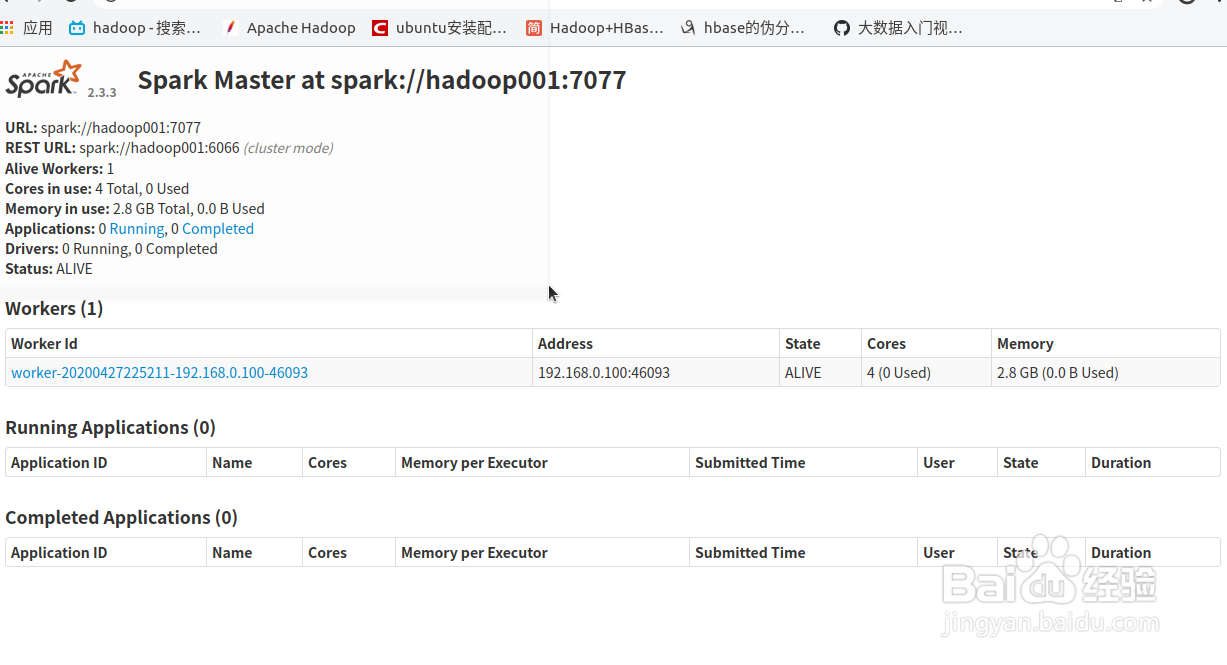
4、在主机的浏览器输如【localhost:8079】(单机模式)就可以看到有两个节点在spark集群上
声明:本网站引用、摘录或转载内容仅供网站访问者交流或参考,不代表本站立场,如存在版权或非法内容,请联系站长删除,联系邮箱:site.kefu@qq.com。
阅读量:103
阅读量:56
阅读量:122
阅读量:109
阅读量:36