用pyppeteer来爬取zol笑话大全
1、首先打开zol笑话大全网址http://xiaohua.zol.com.cn/lengxiaohua/,按f12打开开发者模式,然后定位笑话段子的元素如图:

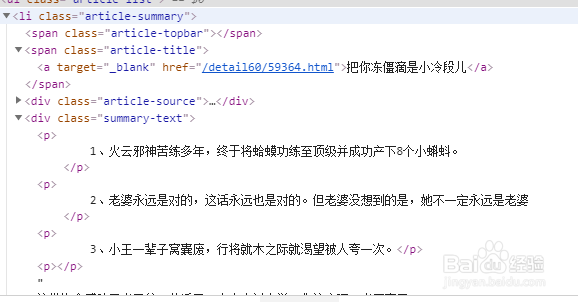
2、从图中可以看出段子的标题藏在li标签下的a标签中,段子的内容藏在第二个div标签下,接下来就好办了。因为pyppeteer这个模块的妙处,你可以不用设置爬虫的代理或者是header就可以直接干了。
3、接下来上代码:
from pyppeteer import launch
import asyncio
import re
from lxml import etree
async def gettxt(i):
browser=await launch()#没有参数默认开启无头模式
page=await browser.newPage()#新建一个网页
await page.goto('http://xiaohua.zol.com.cn/lengxiaohua/'+str(i)+'.html')
page_source=await page.content()
return page_source
def callback(future):
page_source=future.result()
tree=etree.HTML(page_source)
li_list=tree.xpath('//li[@class="article-summary"]')
for i in li_list:
title=i.xpath('.//span[@class="article-title"]/a/text()')
txt=str(i.xpath('.//div[@class="summary-text"]/p/text()')).replace('\\n\\t','')
print(title)
print(txt)
print('+'*50)
for i in range(1,11):
coroutine=gettxt(i)
loop=asyncio.get_event_loop()
task=asyncio.ensure_future(coroutine)
task.add_done_callback(callback)
loop.run_until_complete(task)
4、代码测试结果如下,喜欢的可以自己动手尝试一下。

1、await page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 Edge/16.16299'):用来设置header
await page.setViewport({'width':width,'height':height}):用来设置整个页面
一些基本的网站一般是检测webdriver的,但是设置了以下的其中一个代码就不会被检测出来了:
await page.evaluate('''() =>{ Object.defineProperties(navigator,{ webdriver:{ get: () => false } }) }''')
await page.evaluate('''() =>{ window.navigator.chrome = { runtime: {}, }; }''')
await page.evaluate('''() =>{ Object.defineProperty(navigator, 'languages', { get: () => ['en-US', 'en'] }); }''')
await page.evaluate('''() =>{ Object.defineProperty(navigator, 'plugins', { get: () => [1, 2, 3, 4, 5,6], }); }''')