如何利用Python 进行K-means聚类分析?
1、利用pandas导入数据集。这里有两个变量,假设学生的数学与英语两个成绩如下:
import pandas as pd
df=pd.DataFrame({'math':[98,78,54,89,24,60,98,44,96,90],'english':[92,56,90,57,46,75,76,87,91,88]})

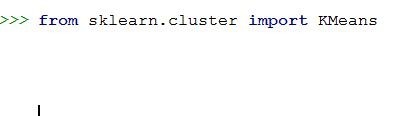
2、导入机器学习报的K-means分析工具。
from sklearn.cluster import KMeans
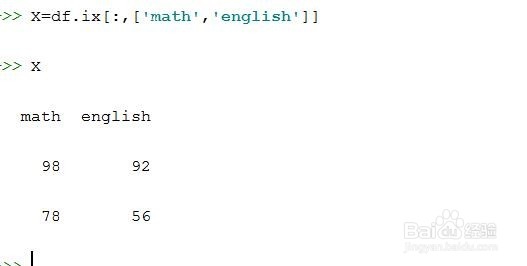
3、处理训练集。假设数据中有分类结果,可以将分类结果作为目标变量。与逻辑回归不同,在没有y的情况下,直接用X变量集也可以进行K-means训练。
X=df.ix[:,['math','english']]
4、建立模型。n_clusters参数用来设置分类个数,即K值,这里表示将样本分为两类。
clf_KMeans=KMeans(n_clusters=2)
其他参数为默认值,可以根据实际情况进行调整。

5、模型训练。得到预测值。
cluster=clf_KMeans.fit_predict(X)
print(cluster)
从结果中可以看到,样本被分为了两类。

6、根据聚类结果绘制散点图形。
plt.figure()
plt.scatter(X['math'], X['english'],c=cluster)
plt.title("K-means test")
plt.show()
由于本例样本较少,分类个数较少,聚类效果不是很明显。

7、增加聚类个数。并绘制图形。
cluster2=KMeans(n_clusters=4).fit_predict(X)
plt.figure(1)
plt.scatter(X['math'], X['english'],c=cluster2)
plt.title("K-means test")
plt.show()
从图形上看,比2类时效果好很多。当然,在样本量足够的情况下,进行聚类分析,要根据实际情况或聚类效果选择K值。
