windows下控制台应用程序乱码原因探究
1、既然我们知道乱码产生的原因是编码与解码的不匹配。我们只有知道了汉字的编码,了解这些编码上的不同,我们才能搞清楚不匹配的原因。我们这里分别通过C语言代码的方式,以及一些辅助软件的方式来查看汉字的编码。编码都是采用十六进制数进行显示的。
首先,我们来看看C语言的代码:
#include <stdio.h>
int main(int argc, char *argv[])
{
char wz[] = "水杯";
unsigned char *p = (unsigned char *)wz;
unsigned i = 0;
printf("sizeof(wz) is %d\n", sizeof(wz));
for (; i < sizeof(wz); i++)
{
printf("byte: %x\n", p[i]);
}
printf("chinese output :%s\n", wz);
return 0;
}
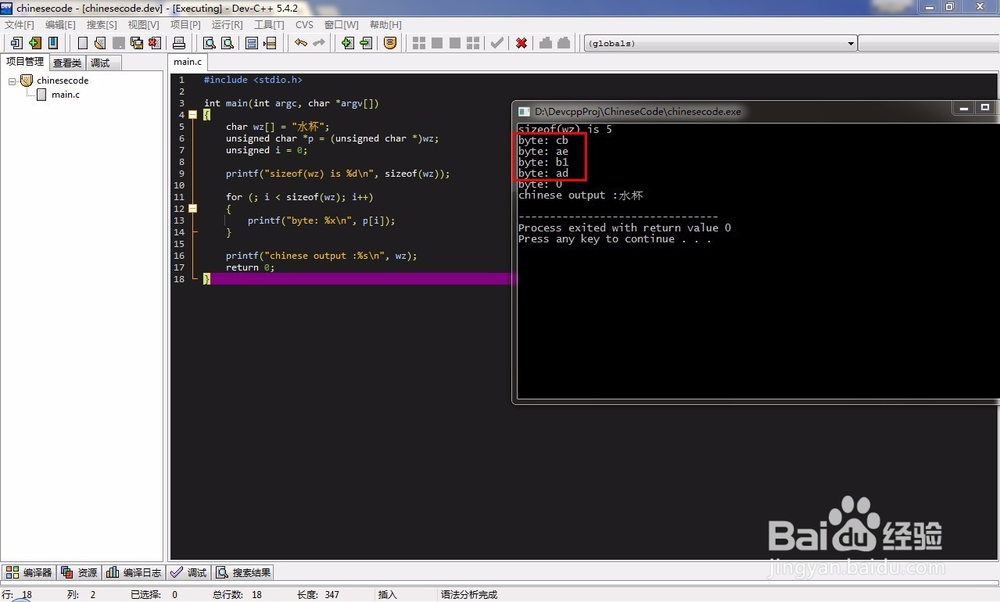
可以看到输出的汉字“水杯”的编码,至于是哪个编码待会再说。
2、我们再通过notepad++来查看“水杯”的编码。
在notepad++中输入“水杯”,然后点击菜单 插件 - Converter - ASCII->HEX。
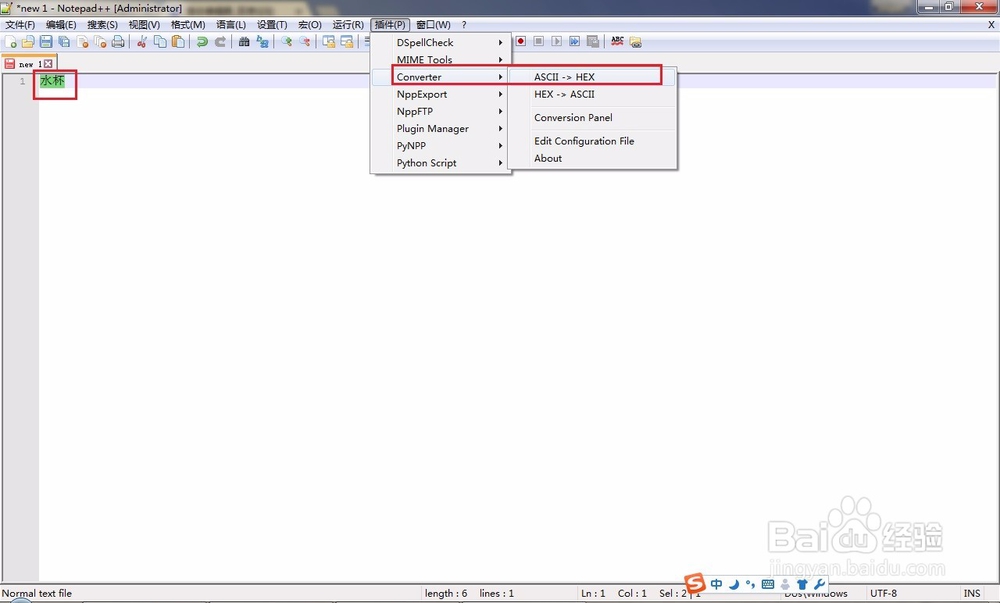
3、来看看显示的结果是什么。
可以看到notepad++显示的结果与我们C语音程序显示的不一样,notepad++是6个字节,C语音程序是4个字节。

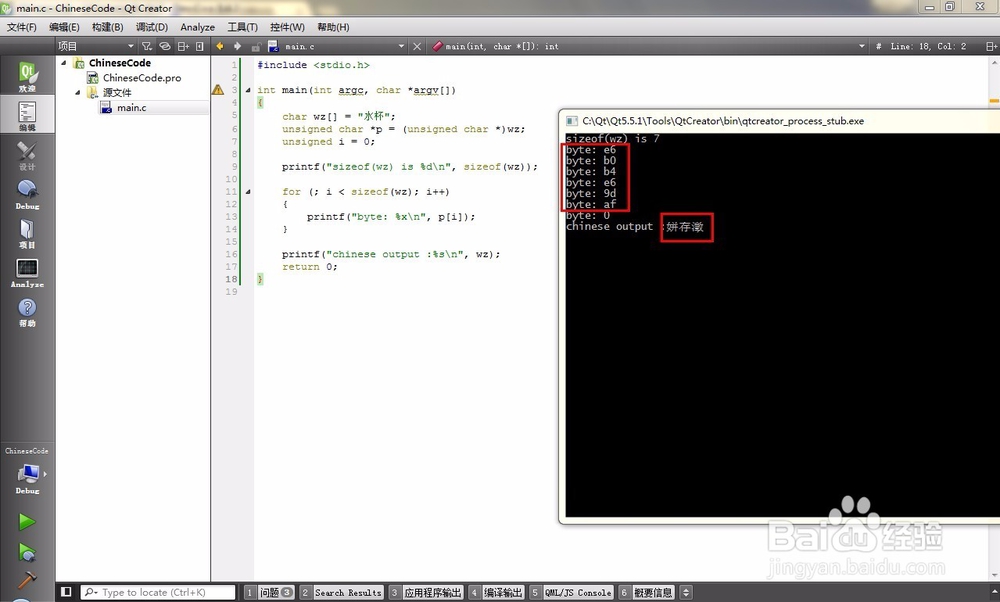
1、我们先在QtCreator中运行下程序看看。
可以看到乱码出现了,显示了三个字“姘存澂”,这显然不是水杯。
我们再看看输出的字节编码,是不是和notepad++中是一样的。
因为每个汉字占用2个字节,而notepad++和我们的乱码程序明显是6个字节,也就是3个汉字。
2、看看“水杯”二字的相关编码。
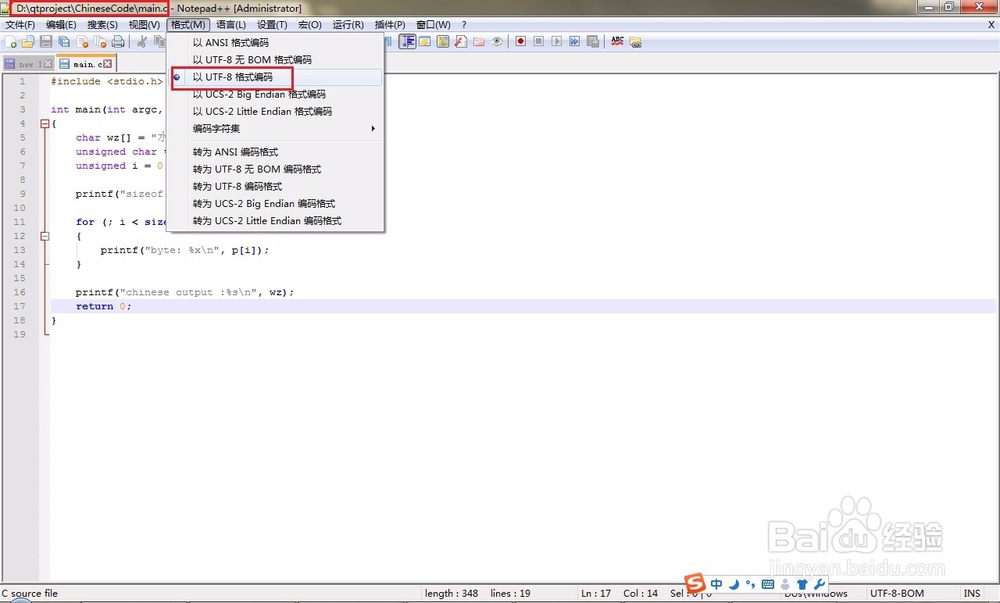
先来看看notepad++的。可以看到是“UTF8无BOM格式编码”。原来这个6字节的“水杯”编码是UTF8。

3、我们再来看看我们的C语言源文件的编码。
可以看到是“以UTF8格式编码”,有无BOM并不会对汉字编码造成影响。所以我们的源文件也是UTF8格式,而且从打印输出的十六进制编码也可以看出来。
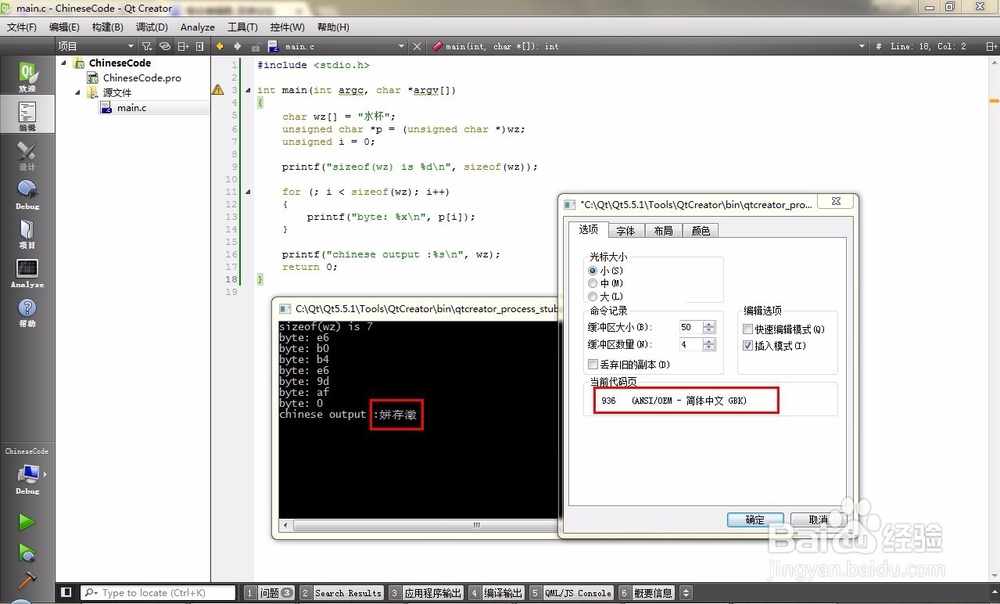
4、再来看看问题的根源。
可以看到,我们的控制台代码页是 936(ANS/OEM- 简体中文 GBK),并不是UTF8,所以用GBK解码UTF8必然是乱码。
1、解决方案我已经在“Windows下控制台应用程序乱码解决方案”经验中介绍了。
这里再演示下。我用记事本或者notepad++将源代码转换为ANSI编码,然后保存。
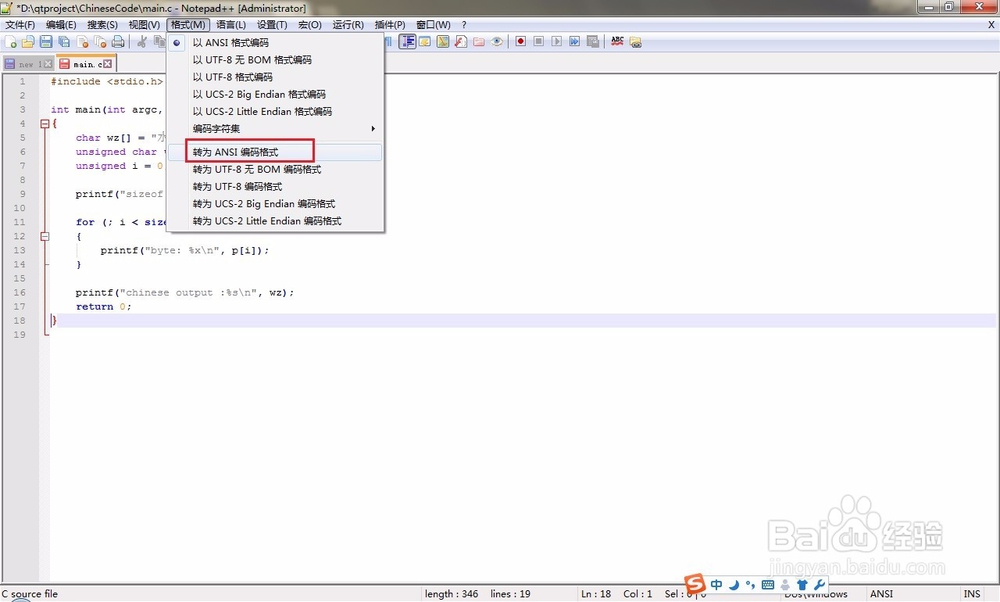
2、然后,再QtCreator中点击Yes to all。
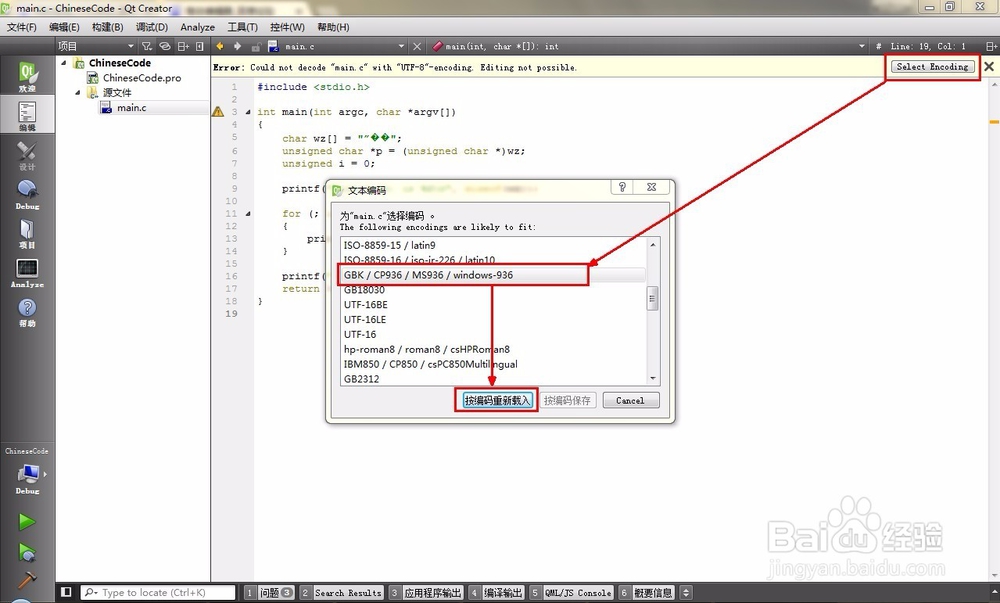
之后,源代码中的汉字会变为乱码。

3、按下图中的操作进行。
然后我们的代码就正常了。
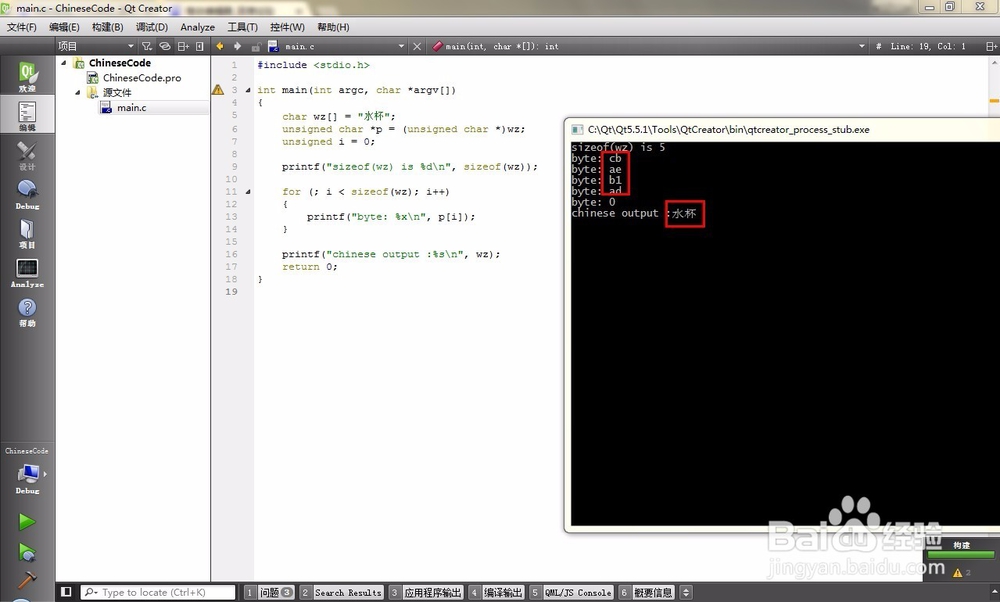
4、运行下看看。
乱码问题解决,可以看到我们的“水杯”汉字编码也变为了四个字节。
5、我们可以在notepad++中检验下ANSI编码格式的汉字。
与我们的ANSI源代码编译运行的一样。
6、从实验中我们可以看到QtCreator对汉字的编码与源代码的编码是一致的,所以要解决乱码问题需要从源代码着手。
1、我们知道ANSI编码肯定是没问题的,那么utf8编码的文件在Devc++中是什么样的呢。
我们看到源代码是 无BOM的UTF8编码。但是Devc++打开后,源代码中的汉字变成了乱码。

2、我们将源代码中的汉字改正过来。然后 保存 。
再看看源代码的编码,竟然是ANSI,我们打开前明明是UTF8。
Devc++是按照ANSI进行读文件和写文件的。所以我们只要在Devc++中编辑代码,那么乱码的问题就不是大问题。不过本身也不是大问题。
1、主要是这句:unsigned char *p = (unsigned char *)wz;
代码中的第一个unsigned不能够丢掉,否则会因为溢出的问题,导致单字节被提升为四字节。
看看运行结果就知道了。
每个打印输出前都加了六个f。
