MindSpore怎样使用混合精度
1、计算流程
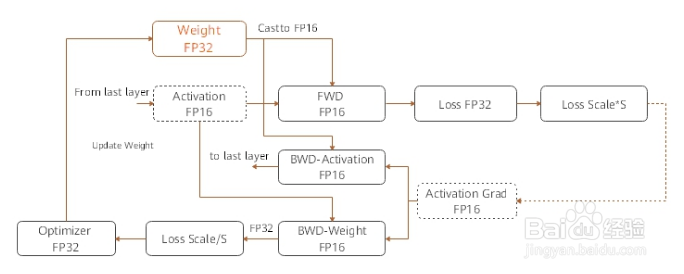
1. 参数以FP32存储;
2. 正向计算过程中,遇到FP16算子,需要把算子输入和参数从FP32 cast成FP16进行计算;
3. 将Loss层设置为FP32进行计算;
4. 反向计算过程中,首先乘以Loss Scale值,避免反向梯度过小而产生下溢;
5. FP16参数参与梯度计算,其结果将被cast回FP32;
6. 除以Loss scale值,还原被放大的梯度;
7. 判断梯度是否存在溢出,如果溢出则跳过更新,否则优化器以FP32对原始参数进行更新。
MindSpore混合精度典型的计算流程如下图所示讨拒特:
2、自动混合精度
使用自动混合精度,需要调用相应的接口,将待训练网络和优化器作为输入传进去;该接口会将整张网络的算子转换成FP16算子(除BatchNorm算子和Loss涉及到的算子外)。
具体的实现步骤为:
1. 引入MindSpore的混合精度的接口amp;
2. 定义网络:该步骤和普通的网络定义没有区别(无需手动配置某个算子的精度);
3. 使用amp.build_train_network接口封装网络模型、优化器和损失函数,在该步骤中MindSpore会将有需要的算子自动进行类型转换。
代码样例如下:
import numpy as np
import mindspore.nn as nn
from mindspore import Tensor, context
from mindspore.ops import operations as P
from mindspore.nn import Momentum
# The interface of Auto_mixed precision
from mindspore import amp
context.set_context(mode=context.GRAPH_MODE)
context.set_context(device_target="Ascend")
# Define network
class Net(nn.Cell):
def __init__(self, input_channel, out_channel):
super(Net, self).__init__()
self.dense = nn.Dense(input_channel, out_channel)
self.relu = P.ReLU()
def construct(self, x):
x = self.dense(x)
x = self.relu(x)
return x
# Initialize network
net = Net(512, 128)
# Define training data, label
predict = Tensor(np.ones([64, 512]).astype(np.float32) * 0.01)
label = Tensor(np.zeros([64, 128]).astype(np.float32))
# Define Loss and Optimizer
loss = nn.SoftmaxCrossEntropyWithLogits()
optimizer = Momentum(params=net.trainable_params(), learning_rate=0.1, momentum=0.9)
train_network = amp.build_train_network(net, optimizer, loss, level="O3", loss_scale_manager=None)
# Run training
output = train_network(predict, label)
3、手动混合精度
MindSpore还支持手动混合精度。假定在网络中只有一个Dense Layer要用FP32计算,其他Layer都用FP16计算。混合精度配置以Cell为粒度,Cell默认是FP32类型。
以下是一个手光诸动混合精度的实现步骤:
1. 定义网络: 该步骤与自动混合精度中的步骤2类似;
2. 配置混合精度: 通过net.to_float(mstype.float16),把该Cell及其子Cell中所有的算子都配置成FP16;然后,将模型中的dense算闲三子手动配置成FP32;
3. 使用TrainOneStepCell封装网络模型和优化器。
代码样例如下:
import numpy as np
import mindspore.nn as nn
import mindspore.common.dtype as mstype
from mindspore import Tensor, context
from mindspore.ops import operations as P
from mindspore.nn import WithLossCell, TrainOneStepCell
from mindspore.nn import Momentum
context.set_context(mode=context.GRAPH_MODE)
context.set_context(device_target="Ascend")
# Define network
class Net(nn.Cell):
def __init__(self, input_channel, out_channel):
super(Net, self).__init__()
self.dense = nn.Dense(input_channel, out_channel)
self.relu = P.ReLU()
def construct(self, x):
x = self.dense(x)
x = self.relu(x)
return x
# Initialize network and set mixing precision
net = Net(512, 128)
net.to_float(mstype.float16)
net.dense.to_float(mstype.float32)
# Define training data, label
predict = Tensor(np.ones([64, 512]).astype(np.float32) * 0.01)
label = Tensor(np.zeros([64, 128]).astype(np.float32))
# Define Loss and Optimizer
loss = nn.SoftmaxCrossEntropyWithLogits()
optimizer = Momentum(params=net.trainable_params(), learning_rate=0.1, momentum=0.9)
net_with_loss = WithLossCell(net, loss)
train_network = TrainOneStepCell(net_with_loss, optimizer)
train_network.set_train()
# Run training
output = train_network(predict, label)