Hadoop文件系统数据定时、实时备份和恢复的方法
1、Hadoop 是一个分布式系统基础架构,是一个分布式文件系统HDFS(Hadoop Distributed File System),对于那些有着超大数据集(large data set)的应用程序的企业,如大数据公司一般都会用到Hadoop文件系统。
通过【ucache灾备云】平台可以实现Hadoop数据备份、恢复功能:
1、完全备份
将选定的数据源完全备份到指定目的地的备份集中化。它不会根据最新的变动比较后进行备份,而是直接将所有的数据和日志备份到【ucache灾备云】平台中,并产生一个时间点,以便恢复使用。
2、增量备份
是基于上一次完全备份,备份数据内容有变动以及变化的数据备份到平台,同时产生一个新的时间点,以便恢复使用。
3、差异备份
从上次完全备份或差异备份或增量备份以来变化的数据。
4、数据恢复
在Hadoop文件系统中文件数据被损坏或者丢失时,使用之前的文件系统备份集来实现文件数据的还原。
5、其它文件系统备份兼容
【ucache灾备云】平台除了可以对Hadoop文件系统数据定时、实时备份和恢复外,还同时支持windows\linnx\UNIX\ANYShare文件系统的自动定时、实时备份与恢复。

2、准备工作
Hadoop文件系统数据自动进行定时、实时备份和恢复的前提是在【ucache灾备云】-IDC崔琴婷- 开通管理账号,按容量订阅,即开即用。
MF型、企业型、定制型,任选其一进行开通,并登录WEB控制台。
注意事项
当集群有一个NameNode时,进行Hadoop文件系统备份,需要确保集群必须处在开启状态;当集群有多个NameNode时,需要一台active 一台standy,才可以正常使用,如果两个namenode都是standby,也需要执行相应的命令使集群保持正常状态。
3、第一步:新建备份任务
1、登录控制台,点击【定时/持续数据保护】→【数据备份】选项卡,进入备份任务的起始页,点击【新建】。
2、进入新建备份任务页面后,选择要保护的对象处,勾选客户端选择【hadoop虚拟客户端】,选择要保护的应用类型处勾选【Hadoop文件系统】
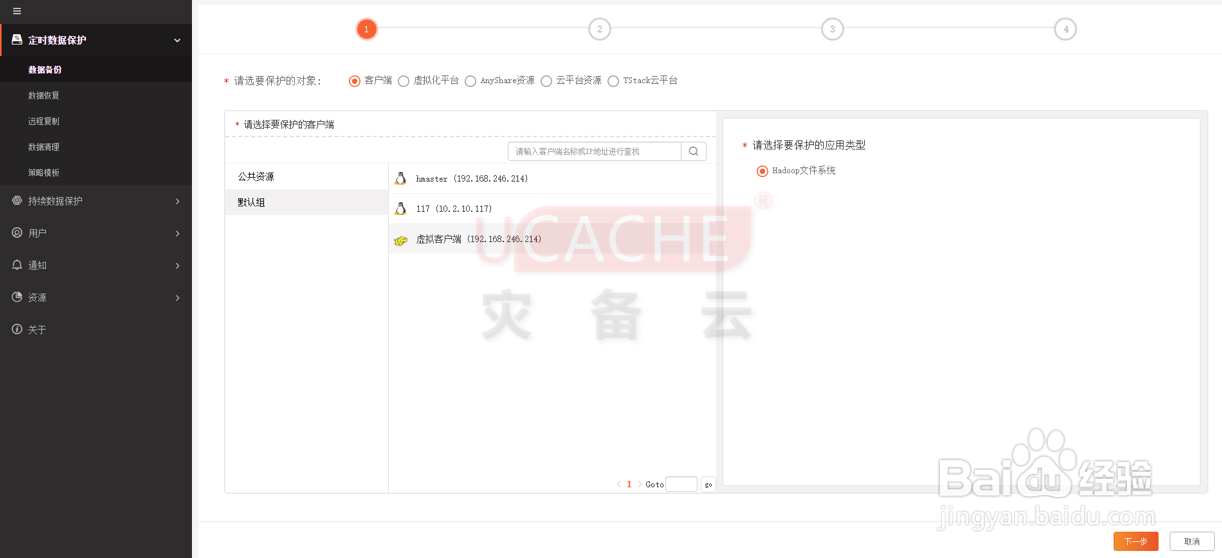
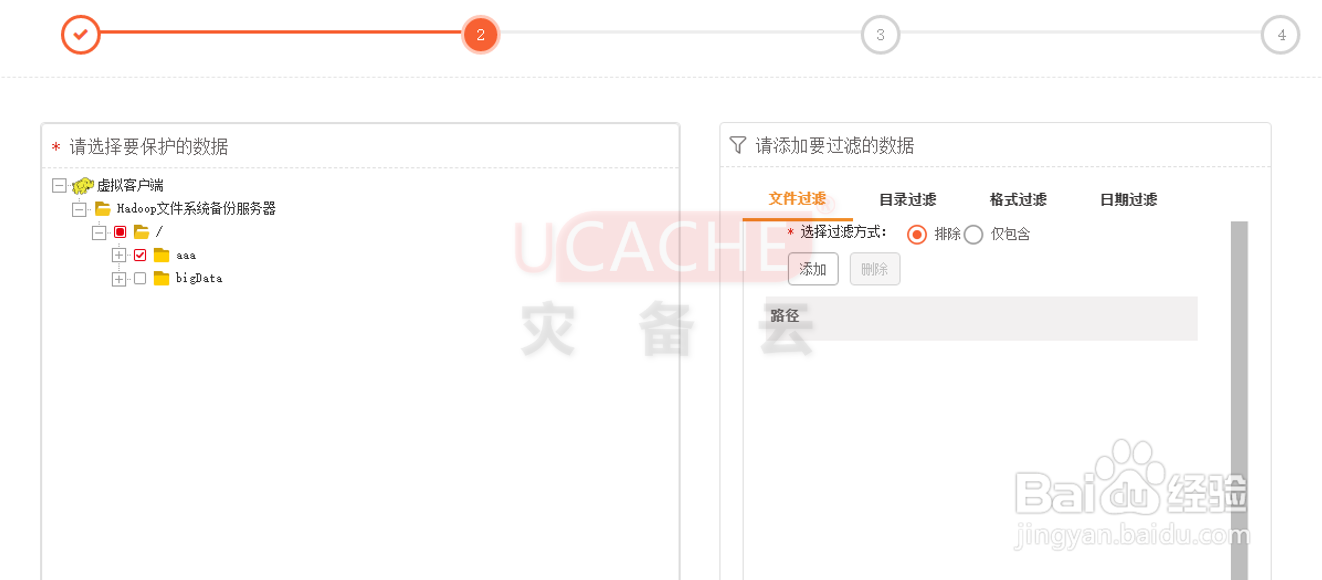
4、第二步:创建备份规则
点击“+”展开数据源层级,Hadoop定时备份任务支持自动发现数据源的功能,对要备份的文件进行勾选,同时创建备份规则(图1)。
说明:
过滤方式支持:文件过滤、目录过滤、格式过滤、日期过滤,选择相应的栏目,可进一步进行设置操作。例如:【格式过滤】(图2)

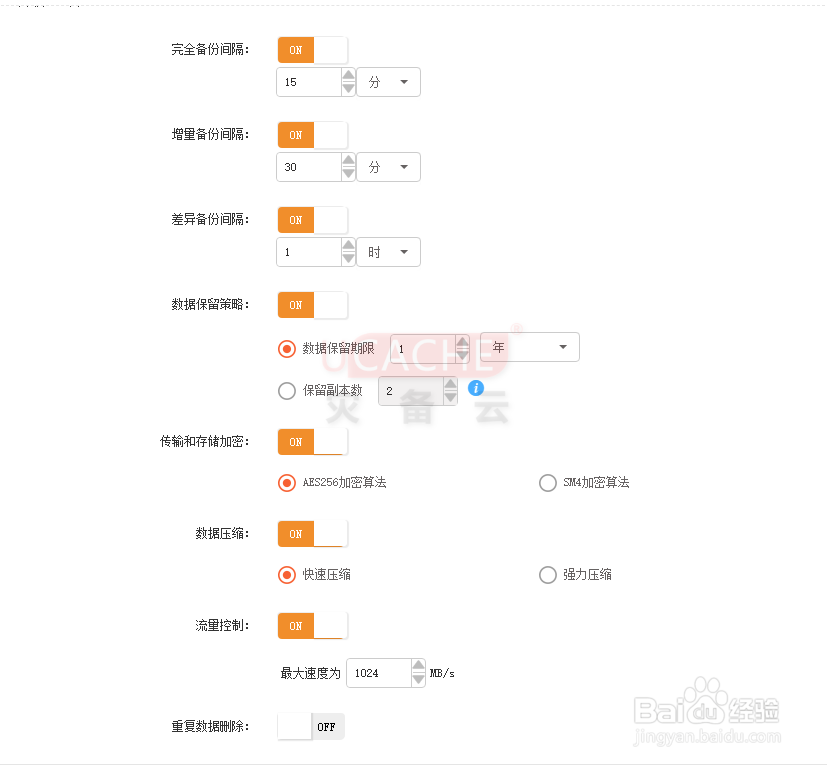
5、第三步:设置策略
根据用户自定义规则,进行相应的设置:【永久增量备份】、【数据保留策略】、【传输和存储加密】、【重复数据删除选项】、【数据压缩】、【流量控制】、【备份自动重试】等。
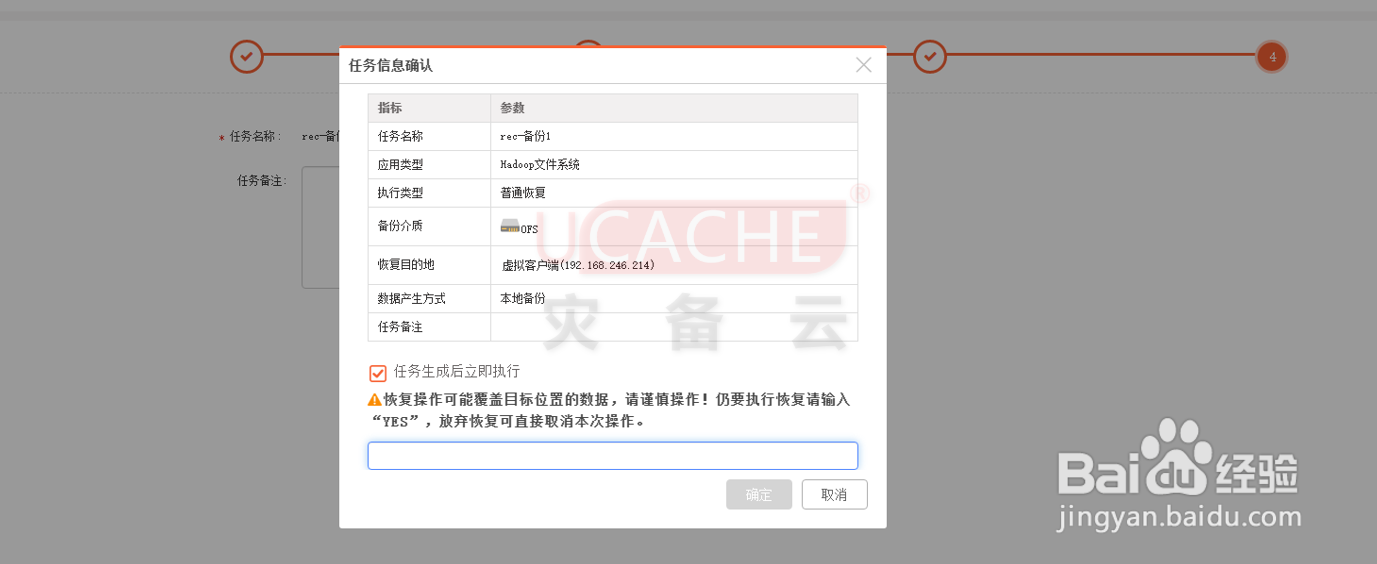
6、第四步:恢复测试
进入【数据恢复】页面,创建恢复任务,选择【恢复位置】,默认为恢复至其他Hadoop虚拟客户端,如果不选择路径,默认【恢复至原路径】,选择好路径后,确定【恢复策略】,点击【完成】。
注意:
【恢复策略】分三种:
1、替换已存在的文件;
2、仅替换比恢复文件更旧的文件;
3、跳过已存在的文件。
7、目前,微网聚力Ucache数据中心托管用户,已经有近3成的用户都已经开始使用【ucache灾备云】平台进行异地容灾备份服务,管理操作十分简单,功能体验不懂的可以随时在评论区留言