Hadoop学习入门介绍
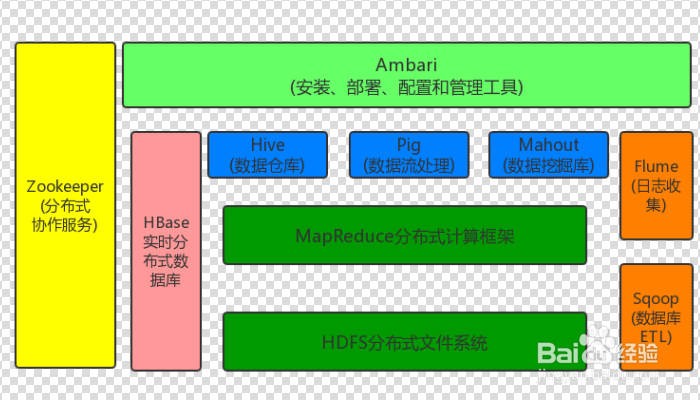
1、首先我们来了解一下Haddop的生态圈,Hadoop项目主要包括以下几个模块:HDFS是一个高可靠、高吞吐量的分布式文件系统;MapReduce是一个分布式的离线并行计算框架;Hadoop YARN是一个新的MapReduce框架,任务调度与资源管理;Pig 轻量级的语言,可以将命令转换为MapReduce程序;Hive 相当于SQL到MapReduce的映射器;HBase Nosql数据库 非关系型的列式数据库,其他的就不再一一介绍了,读者可自行了解。
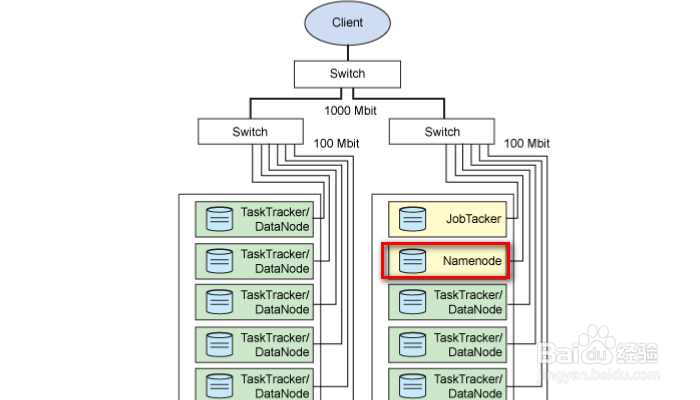
2、下面我们介绍一下Hadoop的架构,主要由以下几部分组成:NameNode、Secondary NameNode、DataNode、JobTracker和TaskTracker。NameNode是HDFS的守护程序,记录文件是如何分割成数据块的,以及这些数据块被存储到哪些节点上,可以对内存和I/O进行集中管理,是个单点在发生故障时将使集群崩溃。Secondary NameNode负责监控HDFS状态的辅助后台程序,每个集群都有一个,与NameNode进行通信,定期保存HDFS元数据快照,当NameNode故障可以作为备用NameNode使用。另外每台从服务器都运行一个DataNode,负责把HDFS数据块读写到本地文件系统。
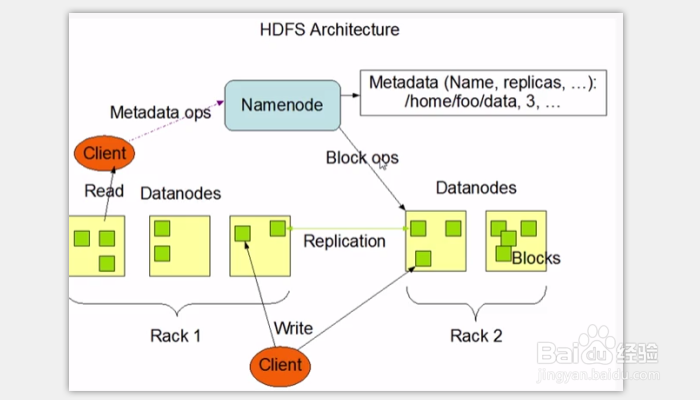
3、JobTracker主要用于处理作业(用户提交代码)的后台程序,决定有哪些文件参与处理,然后切割task并分配节点,同时监控task并且重启失败的task(于不同的节点上)。,每一个集群只有唯一一个JobTracker,位于Master节点上。TaskTracker(任务跟踪器)位于slave节点上,与dataNode结合(代码与数据一起的原则),管理各自节点上的task(由jobtracker分配), 每个节点只有一个tasktracker,但一个tasktracker可以启动多个JVM,用于并行执行map或reduce任务,TaskTracker可以与JobTracker交互。
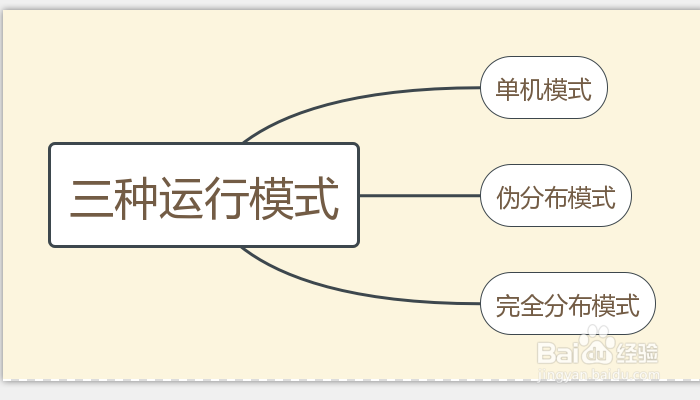
4、接下来是Hadoop的安装和准备工作:安装jdk,配置环境变量;hadoop安装,设置环境变量、设置用户路径、修改配置文件;配置SSH免密码登录:安装SSH 生成一对空口令密钥对,生成的公钥放在系统等。Hadoop有三种运行模式,分别是:单机模式、伪分布式、完全分布式。单机模式安装简单,无需任何配置,但是仅限于调试使用;伪分布式即在单节点上同时启动namenode、datanode、jobtracker、tasktracker、secondary namenode等5个进程,模拟分布式运行;完全分布式便是正常的分布式Hadoop集群。
5、Hadoop的具体安装我们不介绍,下面介绍一下Hadoop中配置相关的文件,如下图所示。需要注意的是我们在core-site.xml中配置NameNode的IP地址和端口号(fs.default.name)为hdfs://master:9000,我们修改mapred-site.xml文件配置作业跟踪器的位置(mapred.job.tracker):localhost:9001。

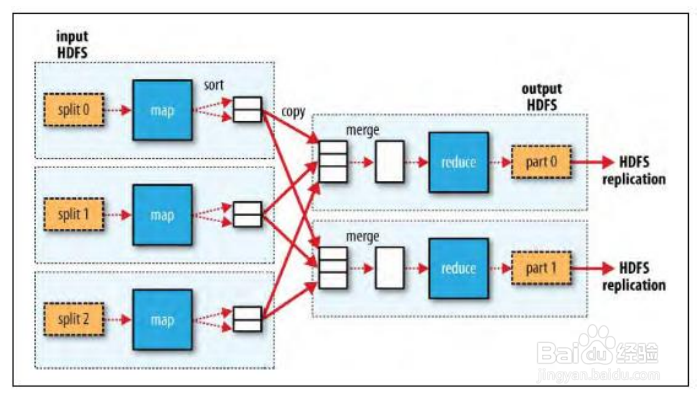
6、下面我们来简单了解一下MapReduce的原理。Map任务处理:读取输入文件内容,解析成key、value对;重写map方法,编写业务逻辑输出新的key、value对;对输出的key、value进行分区(Partitioner类);对数据按照key进行排序、分组,相同key的value放到一个集合中。Reduce任务处理:对多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点;对多个map任务的输出进行合并、排序,写reduce函数自己的逻辑,对输入的key、value处理,转换成新的key、value输出;把reduce的输出保存到文件中。
7、我们可以通过web来了解Hadoop的活动,通过浏览器和http访问jobtracker所在节点的50030端口监控jobtracker,通过浏览器和http访问namenode所在节点的50070端口监控集群,并在/logs目录下查看日志信息。Hadoop官网上有一些技术文档,如下图所示。