使用k-近邻算法改进约会网站的配对效果
1、问题背景
海伦一直使用在线约会网站寻找适合自己的约会对象。尽管约会网站会推荐不同的人选,但她并不喜欢每一个人。经过一番总结,她发现曾交往过三种类型的人:
类型一、 不喜欢的人
类型二、魅力一般的人
类型三、极具魅力的人
尽管发现了上述规律,但海伦依然无法将约会网站推荐的匹配对象归入恰当的分类。她觉得可以在周一到周五约会那些魅力一般的人,而周末则更喜欢与那些极具魅力的人为伴。
可以使用k-mean方法,帮助她将匹配对象划分到确切的分类中。此外海伦还收集了一些约会网站未曾记录的数据信息,她认为这些数据更有助于匹配对象的归类。
2、如何使用k-mean算法来实现
(1)收集数据:提供文本文件。
(2)准备数据:使用Python解析文本文件。
(3)分析数据:使用Matplotlib画二维扩散图。
(4)训练算法:此步骤不适用于k-近邻算法。
(5)测试算法:使用海伦提供的部分数据作为测试样本。测试样本和非测试样本的区别在于:测试样本是已经完成分类的数据,如果预测分类与实际类别不同,则标记为一个错误。
(6)使用算法:产生简单的命令行程序,然后海伦可以输入一些特征数据以判断对方是否为自己喜欢的类型。
3、(1)从文本文件中解析数据
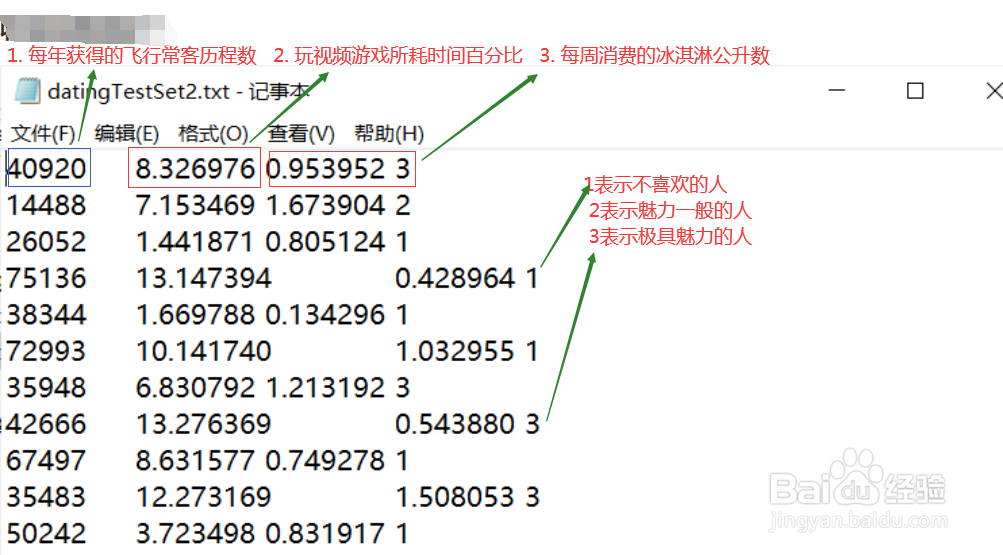
将海伦收集的约会数据,存放在文本文件datingTestSet.txt中,每个样本数据占据一行,总共有1000行。样本主要包含以下3种特征:
(a)每年获得的飞行常客里程数
(b)玩视频游戏所耗时间百分比
(c)每周消费的冰淇淋公升数
在将上述特征数据输入到分类器之前,必须将待处理数据的格式改变为分类器可以接受的格式。
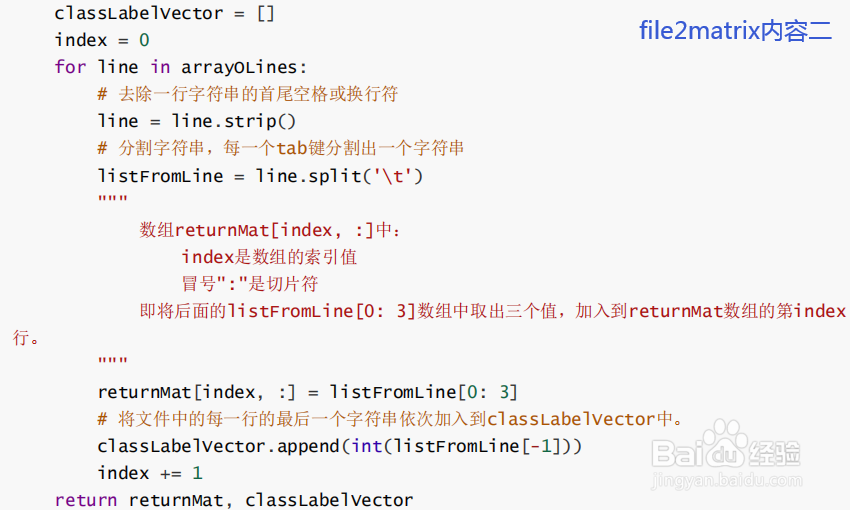
1)使用函数file2matrix读取文件数据
在kNN.py中创建名为file2matrix的函数,以此来处理输入格式问题。该函数的输入为文件名字符串,输出为训练样本矩阵和类标签向量。
将下面的代码增加到kNN.py中。

4、读取文件数据,进行格式化处理,并存贮在相应的数组中。

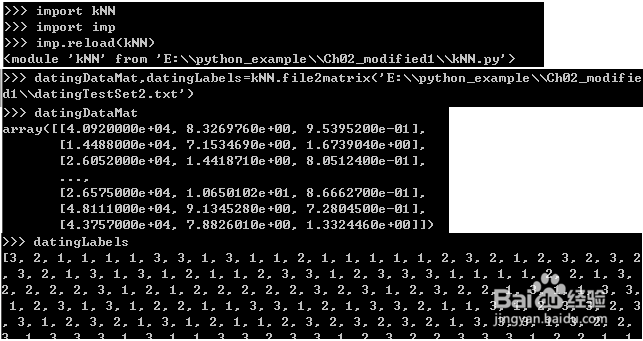
5、2)在python命令行输入下面代码:
>>>import kNN
>>>import imp
>>>imp.reload(kNN)
>>>datingDataMat,datingLabels=kNN.file2matrix('D:\\mymodule\datingTestSet2.txt')%后面是当前目录,每个用户目录是变化的
>>>datingDataMat
>>>datingLabels
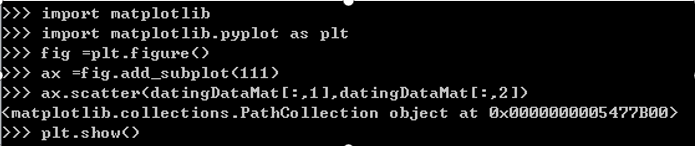
6、(2)分析数据: 使用Matplotlib 创建散点图
在Python命令 行环境中,输入下列命令:
>>> import matplotlib
>>> import matplotlib. pyplot as plt
>>> fig = plt. figure ()
>>> ax = fig. add_ subplot (111)
>>> ax. scatter (datingDataMat[:,1],dat ingDataMat[:,2])
>>> plt . show()
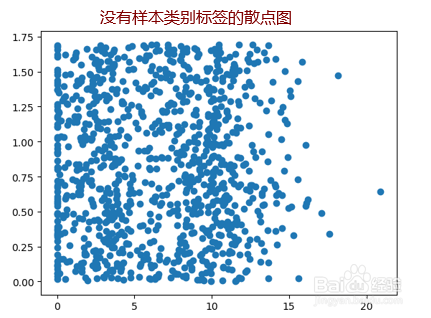
7、散点图使用datingDataMat矩阵的第二、第三列数据,分别表示特征值“玩视频游戏所耗时间百分比”和“每周所消费的冰淇淋公升数
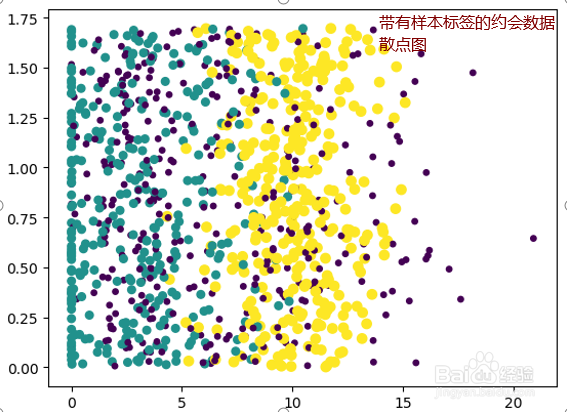
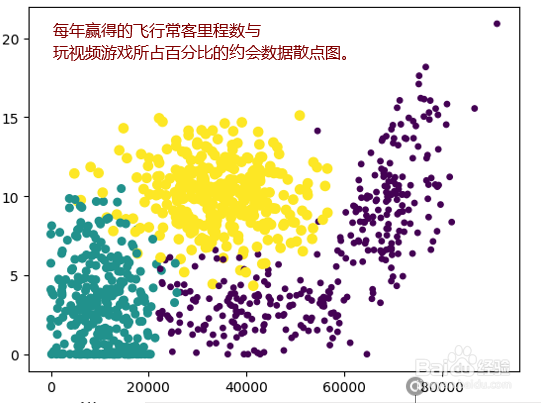
8、(3)准备数据:归一化数值
为避免数字差值最大的属性对计算结果的影响,需要对各种因素进行归一化。
>>>import imp
>>>imp.reload(kNN)
>>>normMat,ranges,minVals = kNN.autoNorm(datingDataMat)
>>>normMat
>>>ranges

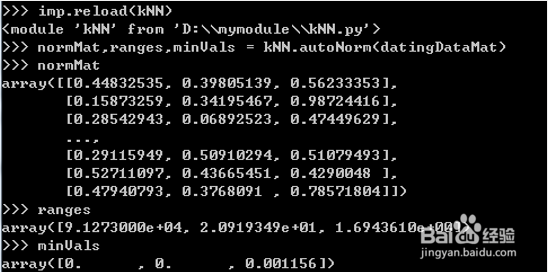
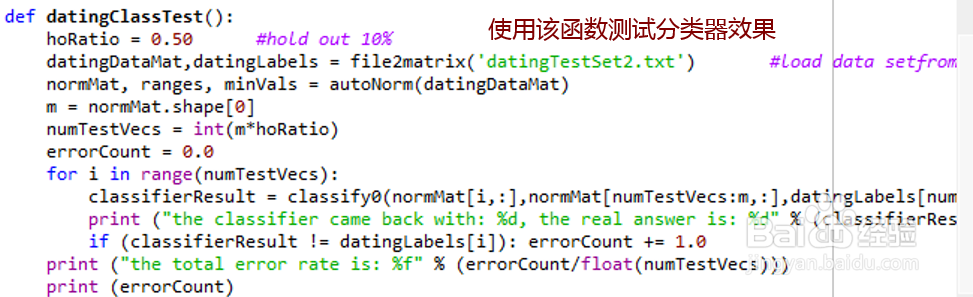
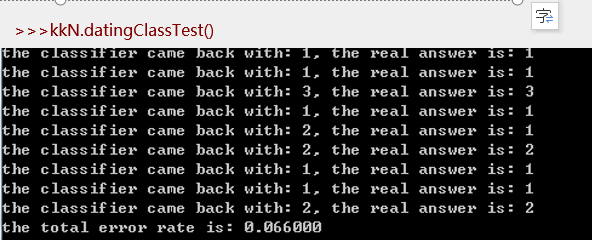
9、(4)测试算法:作为完整程序验证分类器
为了测试分类器效果,在kNN.py文件中创建函数datingClassTest,该函数是自包含的,你可以在任何时候在Python运行环境中使用该函数测试分类器效果。在kNN.py文件中输入下面的程序代码。