如何设计和编写网络爬虫
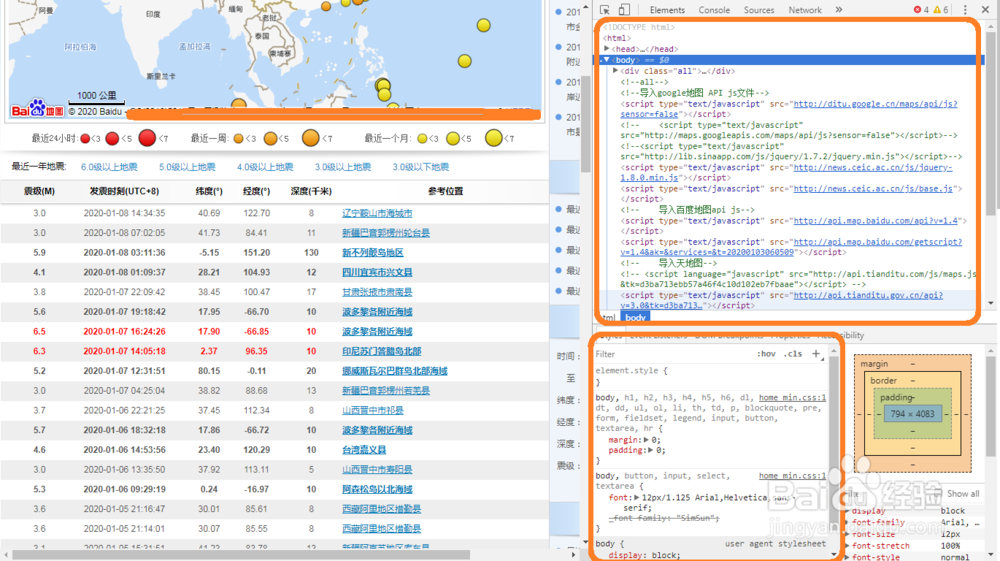
1、掌握必要的HTML基础知识,Chrome浏览器打开一个网页,按F12获取网页源代码(F11进入或者退出全屏模式)
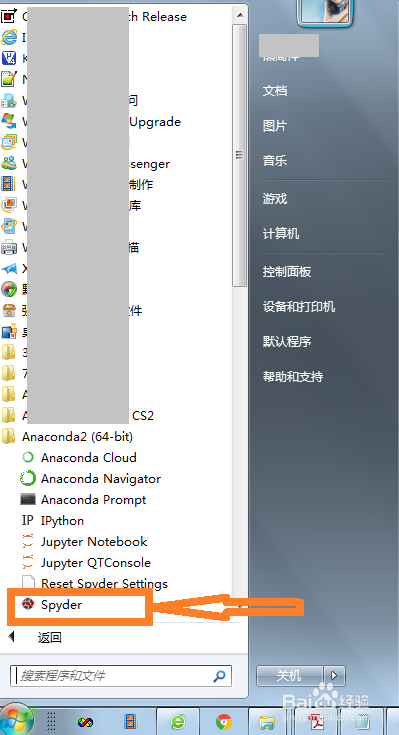
2、打开电脑,启动spyder
3、引入所用库,建立头标集合

4、利用python语句访问源代码,获取源代码,保存源代码

5、创建 dataframe 对象,直接将获取的数据存放进 dataframe 对象中,保存为 csv文件。

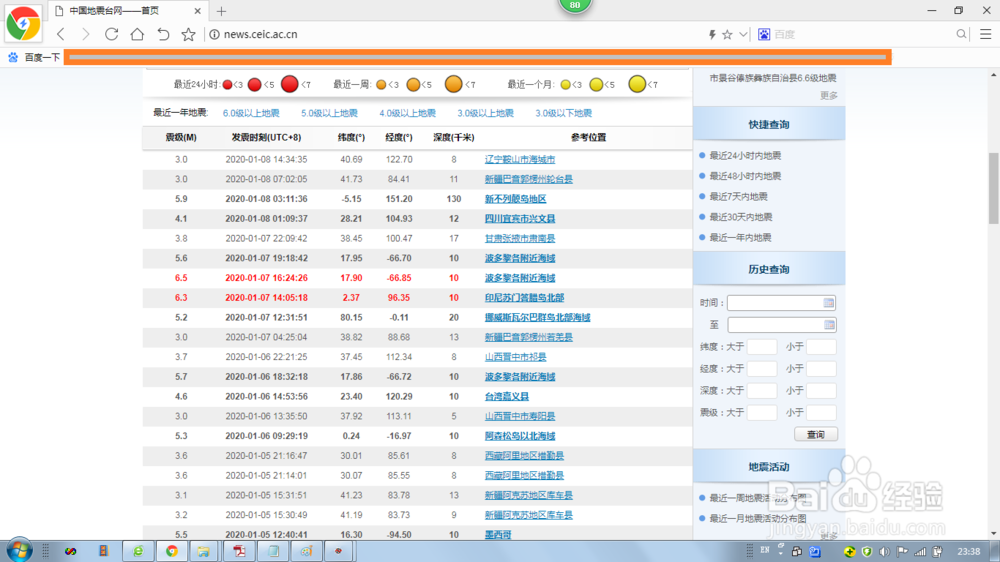
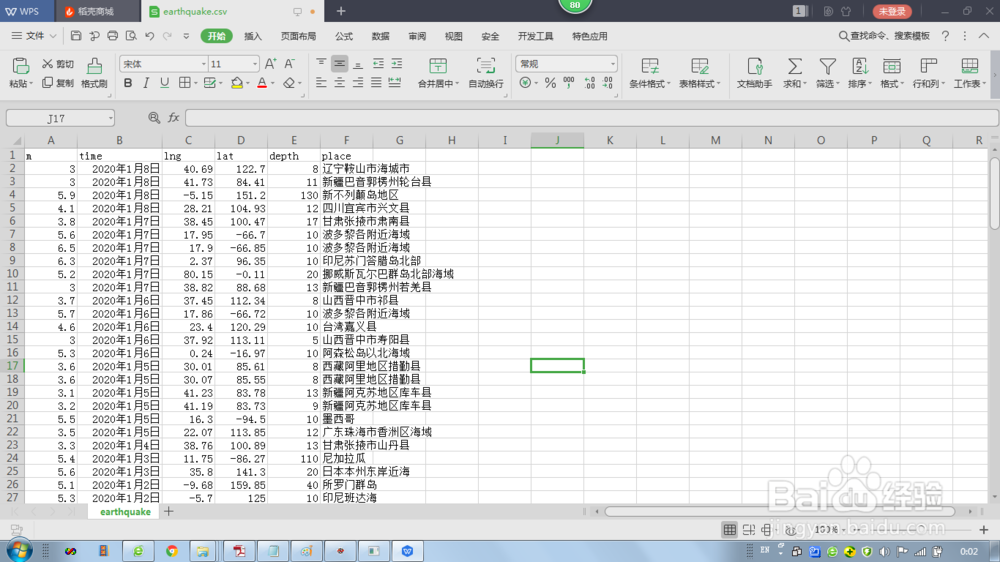
6、整个爬虫成果如图:

7、附程序代码:
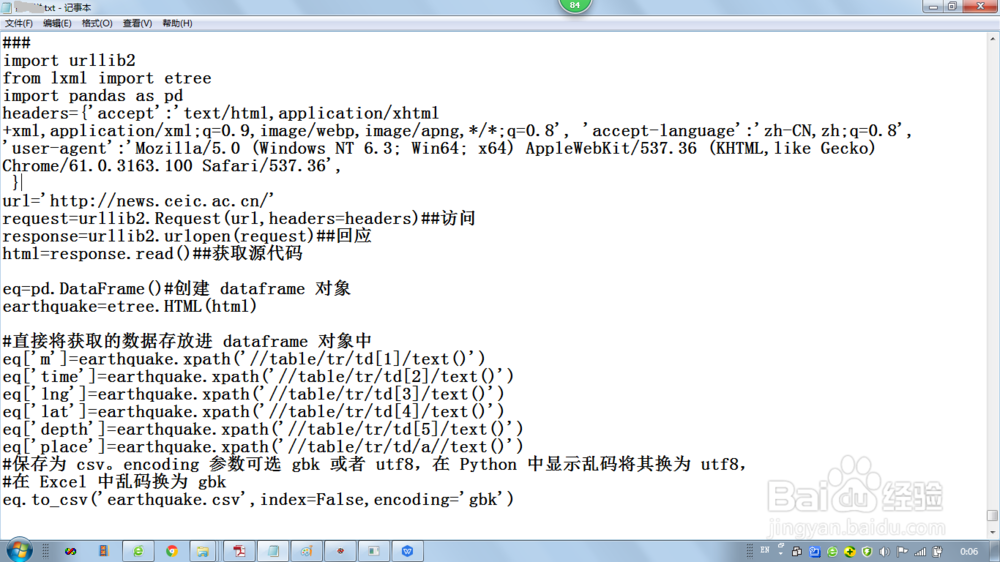
import urllib2
from lxml import etree
import pandas as pd
headers={'accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8', 'accept-language':'zh-CN,zh;q=0.8',
'user-agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML,like Gecko) Chrome/61.0.3163.100 Safari/537.36',
}
url='http://news.ceic.ac.cn/'
request=urllib2.Request(url,headers=headers)##访问
response=urllib2.urlopen(request)##回应
html=response.read()##获取源代码
eq=pd.DataFrame()#创建 dataframe 对象
earthquake=etree.HTML(html)
#直接将获取的数据存放进 dataframe 对象中
eq['m']=earthquake.xpath('//table/tr/td[1]/text()')
eq['time']=earthquake.xpath('//table/tr/td[2]/text()')
eq['lng']=earthquake.xpath('//table/tr/td[3]/text()')
eq['lat']=earthquake.xpath('//table/tr/td[4]/text()')
eq['depth']=earthquake.xpath('//table/tr/td[5]/text()')
eq['place']=earthquake.xpath('//table/tr/td/a//text()')
#保存为 csv。encoding 参数可选 gbk 或者 utf8,在 Python 中显示乱码将其换为 utf8,
#在 Excel 中乱码换为 gbk
eq.to_csv('earthquake.csv',index=False,encoding='gbk')