Python如何实现批量下载网页功能
1、用import代码导入urllib模块,具体代码如下:
import urllib.request
import urllib.parse
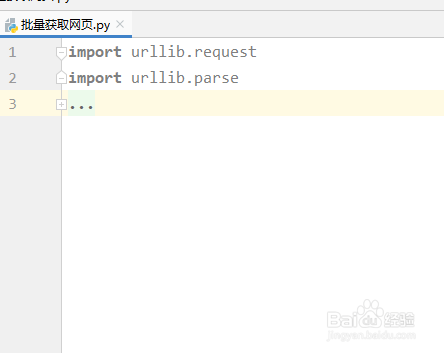
2、创建一个类,名字为PiLiangXia,具体代码如下:
class PiLiangXia():

3、接下来在类下面写入相关功能代码,首先确定一个初始的url,具体代码如下:
def __init__(self):
self.url = "https://sou.autohome.com.cn/zonghe?"
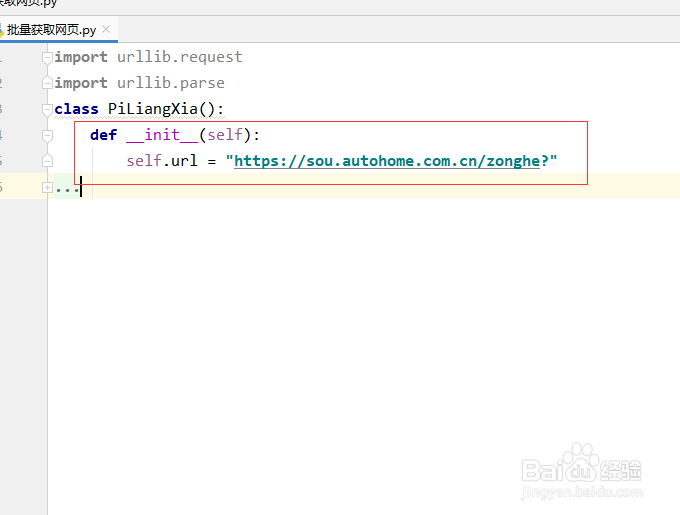
4、接下来写发送请求的功能,具体代码如下:
def send_request(self,url,page):
response = urllib.request.urlopen(url)
self.write_file(response.read(),page)
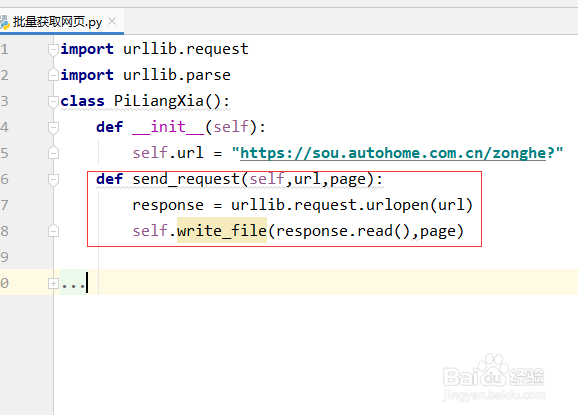
5、由于我们是需要把网页下载到本地,所以我们需要写入文件的功能,具体代码如下:
def write_file(self,content,page):
print("正在保存页数{}".format(page))
with open("car_{}.html".format(page),"wb") as f:
f.write(content)
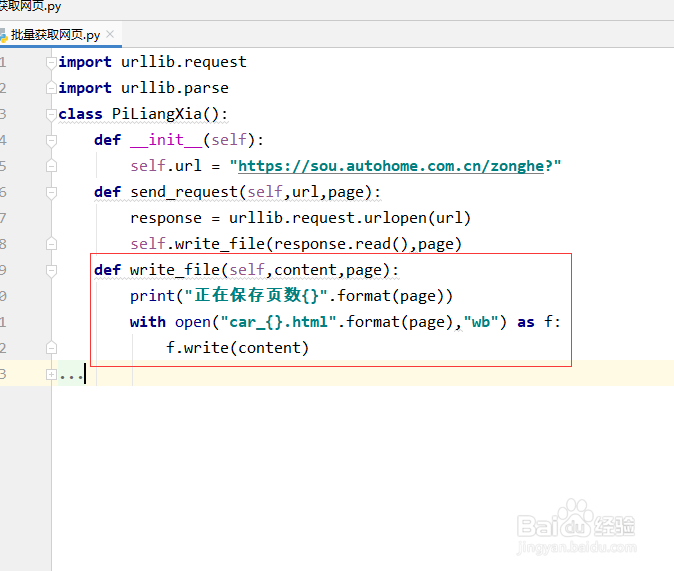
6、接下来我们完成让用户输入页面,并且构造好url地址的功能,由于是多个页面
这里我们需要分析网页的url地址。具体代码如下:
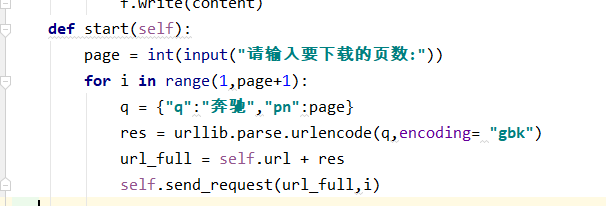
def start(self):
page = int(input("请输入要下载的页数:"))
for i in range(1,page+1):
q = {"q":"奔驰","pn":page}
res = urllib.parse.urlencode(q,encoding= "gbk")
url_full = self.url + res
self.send_request(url_full,i)
这里的 q = {"q":"奔驰","pn":page} 是构造网页的整体url,提前分析,具体的不同网站会有不同的算法。
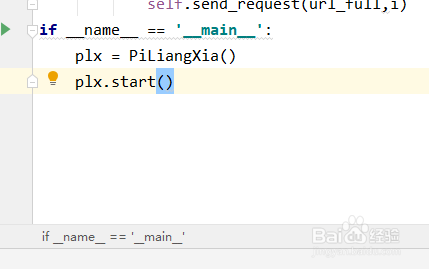
7、接下来我们用main函数执行刚刚的代码块功能,具体代码如下:
if __name__ == '__main__':
plx = PiLiangXia()
plx.start()
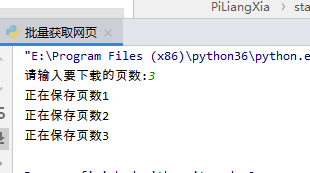
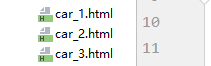
8、整体代码总结和运行效果:
import urllib.request
import urllib.parse
class PiLiangXia():
def __init__(self):
self.url = "https://sou.autohome.com.cn/zonghe?"
def send_request(self,url,page):
response = urllib.request.urlopen(url)
self.write_file(response.read(),page)
def write_file(self,content,page):
print("正在保存页数{}".format(page))
with open("car_{}.html".format(page),"wb") as f:
f.write(content)
def start(self):
page = int(input("请输入要下载的页数:"))
for i in range(1,page+1):
q = {"q":"奔驰","pn":page}
res = urllib.parse.urlencode(q,encoding= "gbk")
url_full = self.url + res
self.send_request(url_full,i)
if __name__ == '__main__':
plx = PiLiangXia()
plx.start()
声明:本网站引用、摘录或转载内容仅供网站访问者交流或参考,不代表本站立场,如存在版权或非法内容,请联系站长删除,联系邮箱:site.kefu@qq.com。
阅读量:98
阅读量:186
阅读量:147
阅读量:33
阅读量:53