Python爬取gb2312编码的网页,并存储中文字符
1、这是第一次写的代码,没有做任何的编码转化,最后得到的json文件中所有的中文都以Unicode编码的方式呈现,这样很不直观。
2、代码运行后的json文件中的内容如图片中所示,可以看到box_title后面的是Unicode,并且该编码转化为中文后还是一个乱码,所以就需要下面的处理了。

3、在python中,当遇到中文的时候就需要进行转码,中文的编码有多种,所以需要指明一种编码方式,这里使用sys.setdefaultencoding进行指明(当我们没有指明解码方式,python 就会使用 sys.defaultencoding 指明的方式来解码。很多情况下 sys.defaultencoding为ANSCII,如果 s 不是这个类型就会出错)

4、指明解码方式之后,需要将gb2312编码的网页进行转码,将编码转化为utf-8编码。

5、最后将josn.dump的参数中设置 ensure_ascii=False(设置之后就能正常的将中文存储在json文件中),完成之后,最终的代码如下
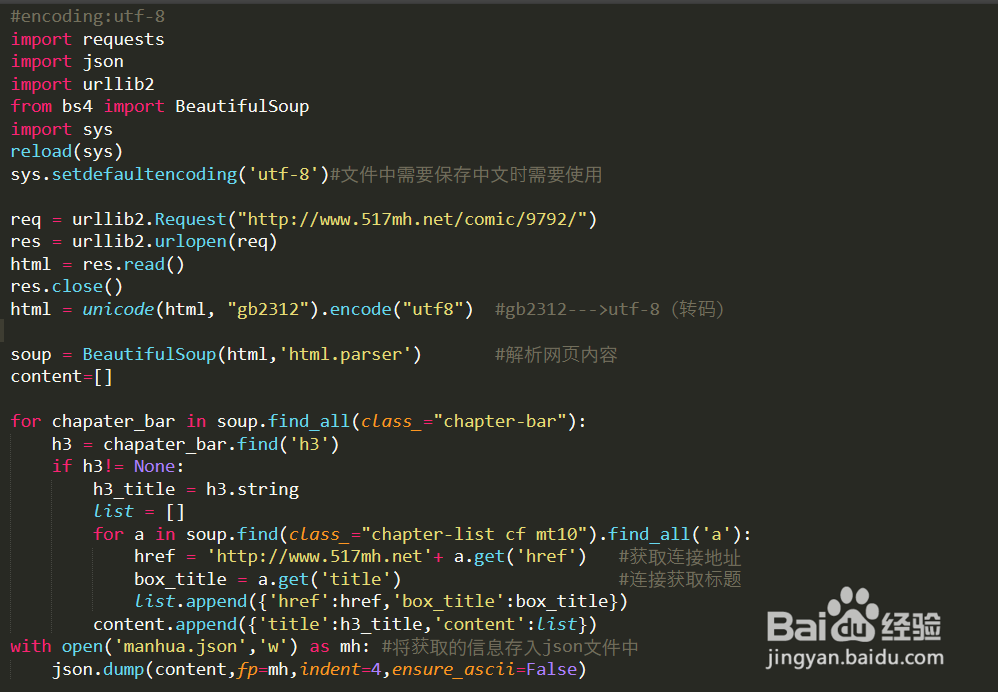
6、现在再看一下运行之后生成的json文件,文件中中文已经正常显示了

声明:本网站引用、摘录或转载内容仅供网站访问者交流或参考,不代表本站立场,如存在版权或非法内容,请联系站长删除,联系邮箱:site.kefu@qq.com。
阅读量:26
阅读量:95
阅读量:162
阅读量:27
阅读量:48