在linux下使用NLPIR(ICTCLAS2015)进行中文分词
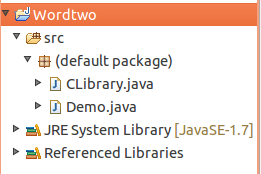
1、Linux下建立一个空项目命名为WordTwo,在src文件夹中添加两个代码,视图如下
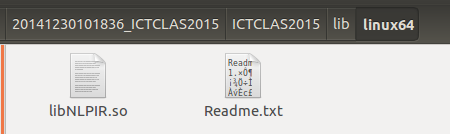
2、将下载的NLPIR打开至lib目录下,将符合要求的so文件拷入到WordTwo的bin文件夹下。注意linux的版本不同则选择不同的so文件,名字不要修改。
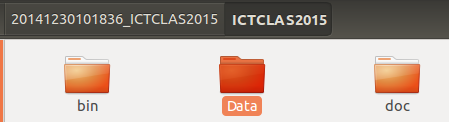
3、将下载的NLPIR目录下的Data文件夹整个复制到项目WordTwo中,放在根目录下。
4、CLibrary为实现中文分词的接口声明,具体内容如图所示
import com.sun.jna.Library;
public interface CLibrary extends Library{
//初始化
public int NLPIR_Init(String sDataPath, int encoding, String sLicenceCode);
//对字符串进行分词
public String NLPIR_ParagraphProcess(String sSrc, int bPOSTagged);
//对TXT文件内容进行分词
public double NLPIR_FileProcess(String sSourceFilename,String sResultFilename, int bPOStagged);
//从字符串中提取关键词
public String NLPIR_GetKeyWords(String sLine, int nMaxKeyLimit,boolean bWeightOut);
//从TXT文件中提取关键词
public String NLPIR_GetFileKeyWords(String sLine, int nMaxKeyLimit,boolean bWeightOut);
//添加单条用户词典
public int NLPIR_AddUserWord(String sWord);
//删除单条用户词典
public int NLPIR_DelUsrWord(String sWord);
//从TXT文件中导入用户词典
public int NLPIR_ImportUserDict(String sFilename);
//将用户词典保存至硬盘
public int NLPIR_SaveTheUsrDic();
//从字符串中获取新词
public String NLPIR_GetNewWords(String sLine, int nMaxKeyLimit, boolean bWeightOut);
//从TXT文件中获取新词
public String NLPIR_GetFileNewWords(String sTextFile,int nMaxKeyLimit, boolean bWeightOut);
//获取一个字符串的指纹值
public long NLPIR_FingerPrint(String sLine);
//设置要使用的POS map
public int NLPIR_SetPOSmap(int nPOSmap);
//获取报错日志
public String NLPIR_GetLastErrorMsg();
//退出
public void NLPIR_Exit();
}

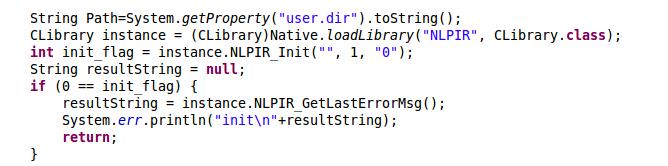
5、添加Demo代码,进行测试:
声明部分如图所示:
String Path=System.getProperty("user.dir").toString();
CLibrary instance = (CLibrary)Native.loadLibrary("NLPIR", CLibrary.class);
int init_flag = instance.NLPIR_Init("", 1, "0");
String resultString = null;
if (0 == init_flag) {
resultString = instance.NLPIR_GetLastErrorMsg();
System.err.println("init\n"+resultString);
return;
}
String sInput ="哎~那个金刚圈尺寸太差,前重后轻,左宽右窄,他戴上去很不舒服,"
+ "整晚失眠会连累我嘛,他虽然是只猴子,但你也不能这样对他啊,官府知道会说我虐待动物的,"
+ "说起那个金刚圈,啊~去年我在陈家村认识了一个铁匠,他手工精美,价钱又公道,童叟无欺,"
+ "干脆我介绍你再定做一个吧!";
resultString = instance.NLPIR_ParagraphProcess(sInput, 1);
6、添加一句代码使用文件
Double d = instance.NLPIR_FileProcess(Path+"/resource/1",Path+"/resource/2",1);
1和2分别为文本文件,1的路径和内容截图如下:

7、运行以下代码
resultString = instance.NLPIR_GetFileKeyWords(Path+"/resource/3", 10,false);
2文件内容截图如下:
表明可以成功运行分词库。
