Pandas | 剔除csv重复数据
1、原来的文件读入代码
df = pd.read_csv('x.csv', index_col='DATE', parse_dates=True)
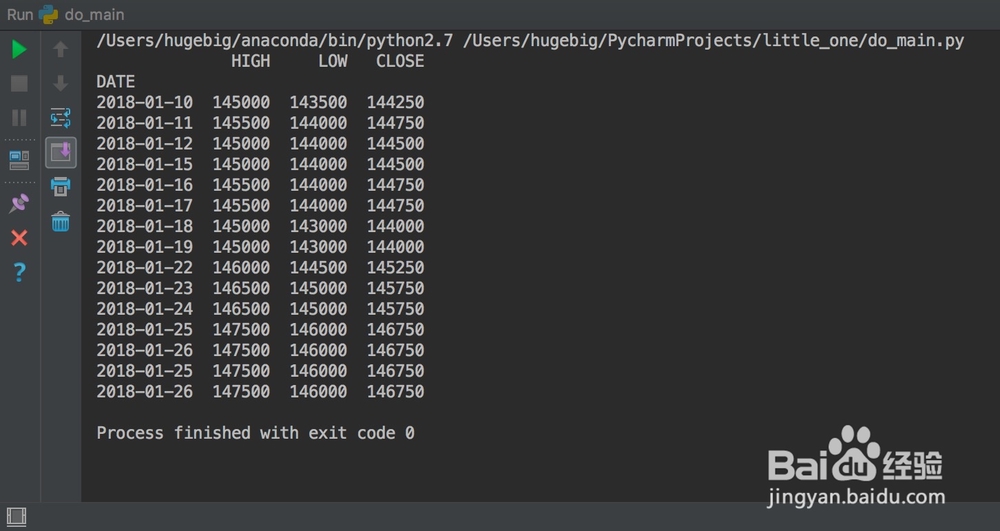
2、上面的代码其实是比较严谨的,只不过暂时跟直接读入文件相比在这件事上好像没有优势
df = pd.read_csv('x.csv')
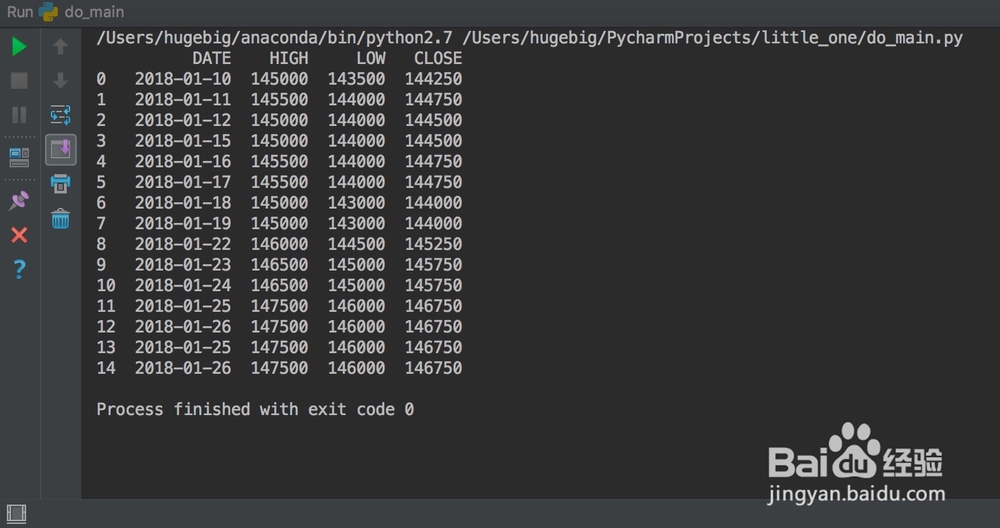
3、在步骤②的基础上,直接就能把重复数据剔除掉
df = pd.read_csv('x.csv')
df = df.drop_duplicates(subset='DATE', keep='last')
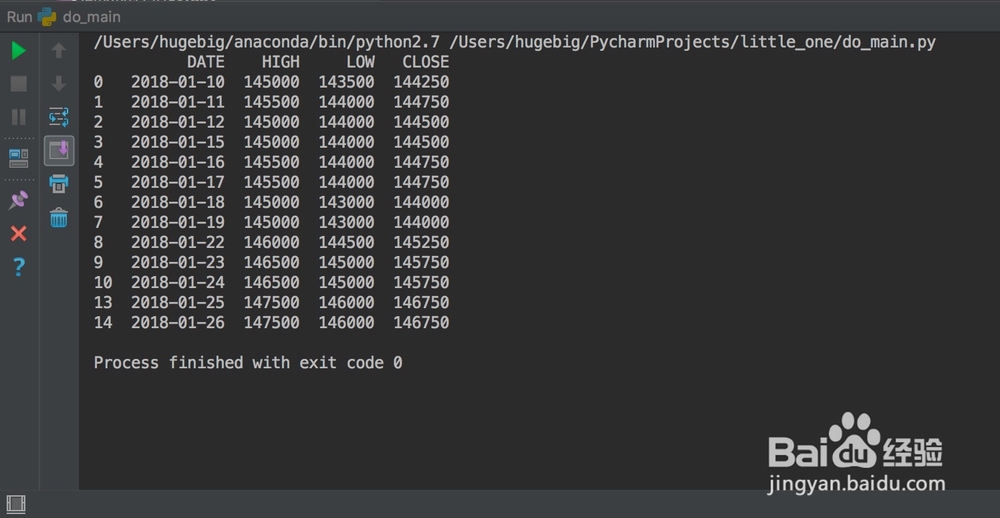
4、而在步骤①代码基础上,则会报错(相信大家都碰到过索引列的特殊)
df = pd.read_csv('x.csv', index_col='DATE', parse_dates=True)
df = df.drop_duplicates(subset='DATE', keep='last')
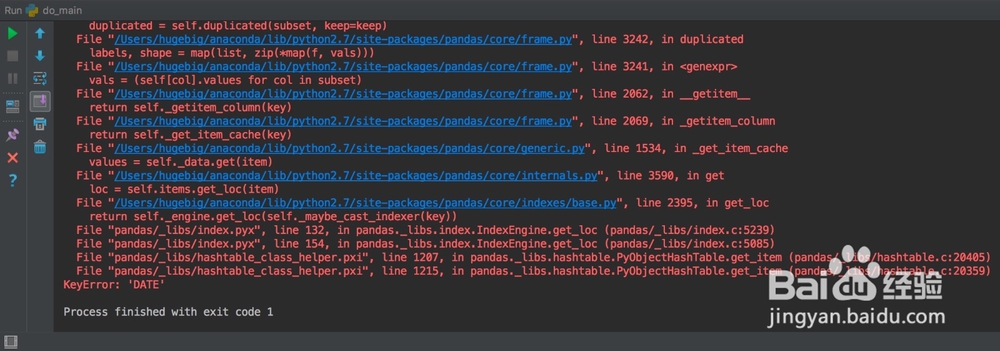
5、我们来说一下步骤①和步骤②的区别。
首先,是否指定索引这个就不说了,太明显了。我们来看两个图。
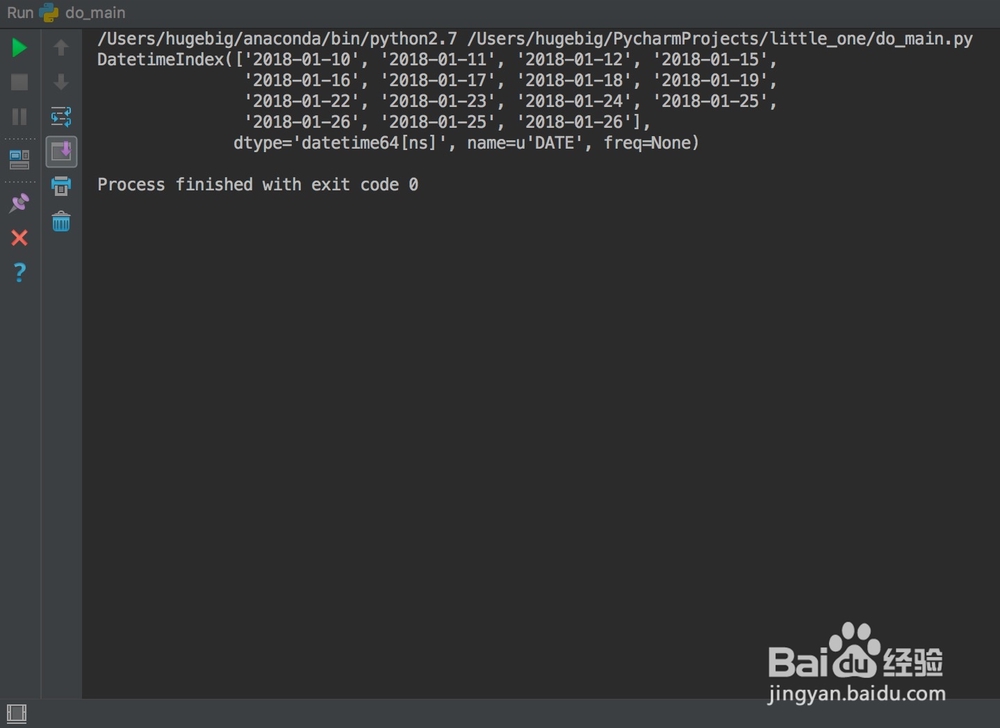

6、上图看出,是否解析时间序列将导致DATE列数据类型的不同,而后续的处理是迫切需要datetime类型的。于是我们这样处理:
df = pd.read_csv('x.csv', parse_dates=['DATE']).dropna().drop_duplicates(subset='DATE', keep='last').set_index('DATE')

7、搞定。
声明:本网站引用、摘录或转载内容仅供网站访问者交流或参考,不代表本站立场,如存在版权或非法内容,请联系站长删除,联系邮箱:site.kefu@qq.com。
阅读量:80
阅读量:125
阅读量:45
阅读量:173
阅读量:23