如何使用Python实现根据网址采集网页?
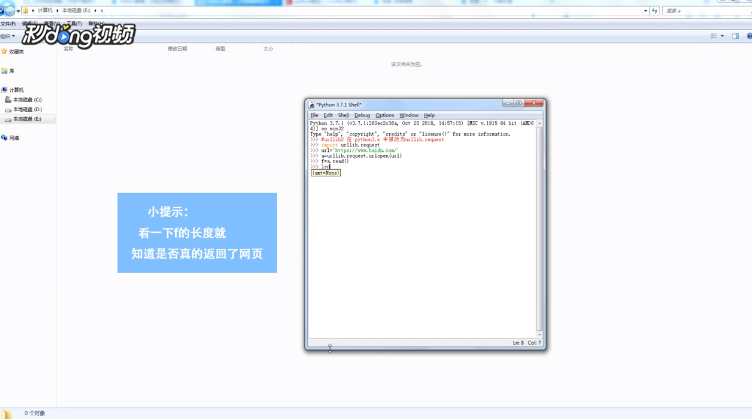
1、引入模块“urllib2”。

2、设置要采集的地址:url=‘http://www.baidu.com/’。

3、使用“urlopen”方法返回网页文件:a=urllib.request.urlopen(url)。

4、只能使用“read”方法获取网页文件的内容:f=a.read()。

5、看一下“f”的长度就知道是否真的返回了网页:len(f)。
声明:本网站引用、摘录或转载内容仅供网站访问者交流或参考,不代表本站立场,如存在版权或非法内容,请联系站长删除,联系邮箱:site.kefu@qq.com。
阅读量:103
阅读量:145
阅读量:143
阅读量:77
阅读量:95