NCBI批量下载基因序列
1、我们需要通过这一下三步到达页面,获取信息。在Gene数据库中搜索fabG,然后进入基因界面,再点击基因进入序列界面。这三部构成了方法的基础。
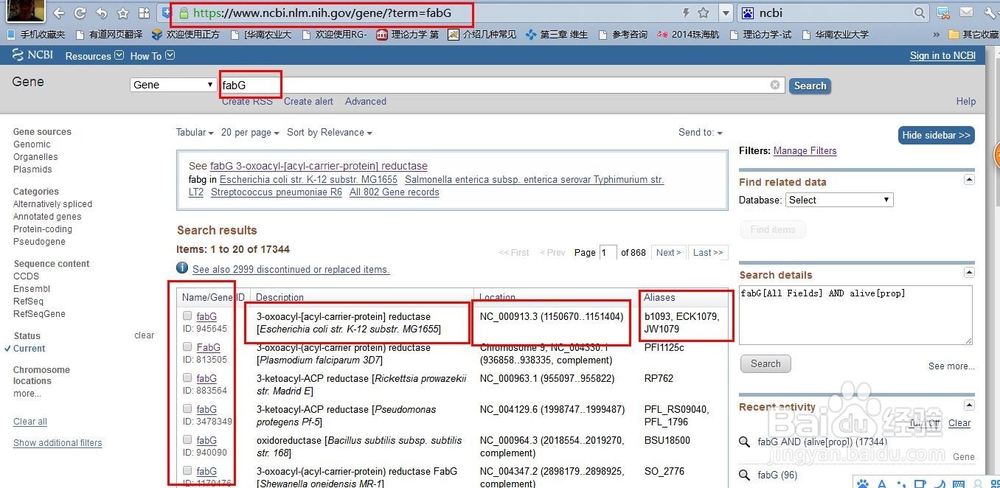

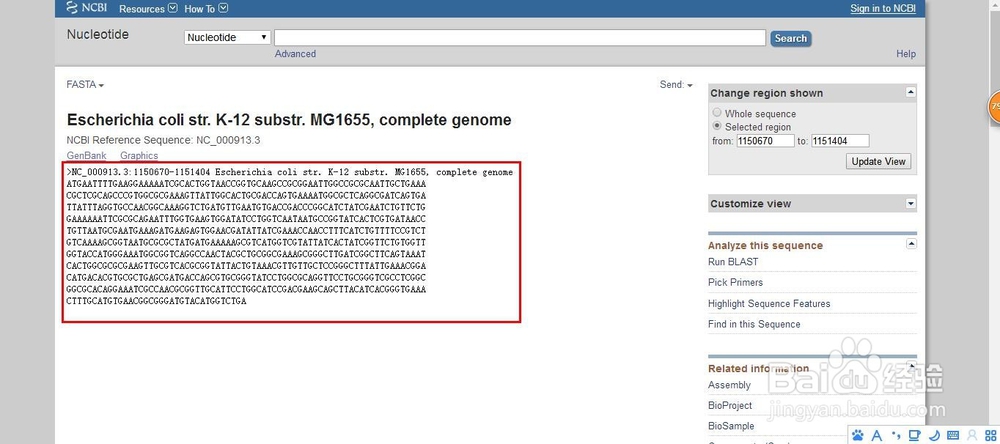
2、通过源码分析,我们可以知道,先获取基因页面链接,再获取fasta页面链接,之后再获取序列。
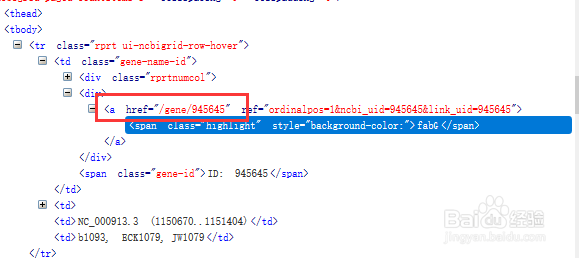

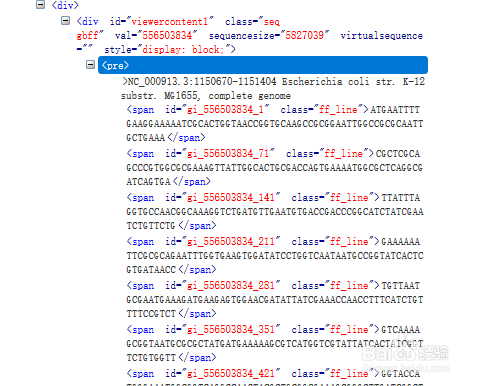
3、构造此方法用于获取基因的链接列表。
从而可以进入基因的信息页面。
import urllib
import urllib.request
from urllib.error import HTTPError
from bs4 import BeautifulSoup
import re
import time
from selenium import webdriver
file=open('C:\\Users\\jyjh\\Desktop\\fabG\\allfabG.txt','w')
url='https://www.ncbi.nlm.nih.gov/gene/?term=fabG'
geneurl='https://www.ncbi.nlm.nih.gov/'
data=[]
html=urllib.request.urlopen(url)
bsObj=BeautifulSoup(html)
geneurllist=[]
for i in bsObj.find('tbody').findAll('tr'):
geneurllist.append(geneurl+i.find('a')['href'])

4、for i in geneurllist:
html1=urllib.request.urlopen(i)
bsObj1=BeautifulSoup(html1)
print(bsObj1.findAll('h1')[1].get_text().replace('[','').replace(']','').strip())
temp=bsObj1.findAll('a')
fastaurl=''
for i in temp:
if i.get_text()=='FASTA':
if '菌毙report' in i['href']:
追光 fastaurl=i['href']
break
driver=webdriver.PhantomJS(executable_path='C:\\Users\\jyjh\\Desktop\\phantomjs-2.1.1-windows\\bin\\phantomjs')
driver.get(geneurl+fastaurl)
time.sleep(3)
data.append(driver.find_element_by_id('viewercontent1').text)
driver.close()
此方法用用于进胳川良入基因序列页面并获取数据

5、for i in data:
file.write(i+"\n")
file.close()
写入数据到txt 文档中。并保存关闭。

6、其中最后的基因序列,只有在浏览器中才能看到,因为使用js和jq的方式生成的数据,在源代码中是不出现的。
运行结果如下图:

