【python】基于sklearn的聚类算法的比较
1、先给定数据:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
x1,_=datasets.make_circles(n_samples=5000,
factor=.6,
noise=0.05)
x2,_=datasets.make_blobs(n_samples=1000,
n_features=2,
centers=[[1.2,1.2]],
cluster_std=[[.1]],
random_state=9)
数据可视化效果如下图,这是一系列散点。

2、我们想让计算机把这些散点分成三类。
先使用K均值算法进行分类:
from sklearn.cluster import KMeans
result=KMeans(n_clusters=3,random_state=9).fit_predict(x)
plt.figure(figsize=(5,5))
plt.scatter(x[:,0],x[:,1],c=result)
分类效果如下图所示。
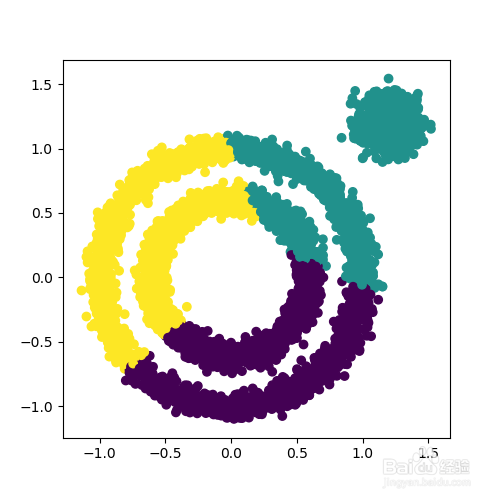
3、再看看小批量K均值算法的分类结果。
from sklearn.cluster import MiniBatchKMeans
result=MiniBatchKMeans(n_clusters=3,random_state=9).fit_predict(x)
这个效果和上面的差不多。

4、使用Birch的层次分类方法:
from sklearn.cluster import Birch
result=Birch(n_clusters=3).fit_predict(x)

5、基于带有噪音干扰的密度分类法:
from sklearn.cluster import DBSCAN
result=DBSCAN(eps=0.1,min_samples=10).fit_predict(x)
这种方法不需要制定分类类别,但是需要制定距离和每一簇的最小样本数。

6、谱分类,需要计算基于rbf距离的相似矩阵:
from sklearn.cluster import SpectralClustering
result=SpectralClustering(n_clusters=3).fit_predict(x)

7、吸引子传播算法,利用样本之间的亲近程度进行分类:
from sklearn.cluster import AffinityPropagation
result=AffinityPropagation().fit_predict(x)
这个算法的特点是计算时间比较长,大约需要3分钟。
