Python如何进行Arima建模?
1、首先,导入相应auto_arima,没有则要先安装pyramid。
from pyramid import auto_arima
import pandas as pd

2、然后,输入数据,可根据实际情况读取数据文件。
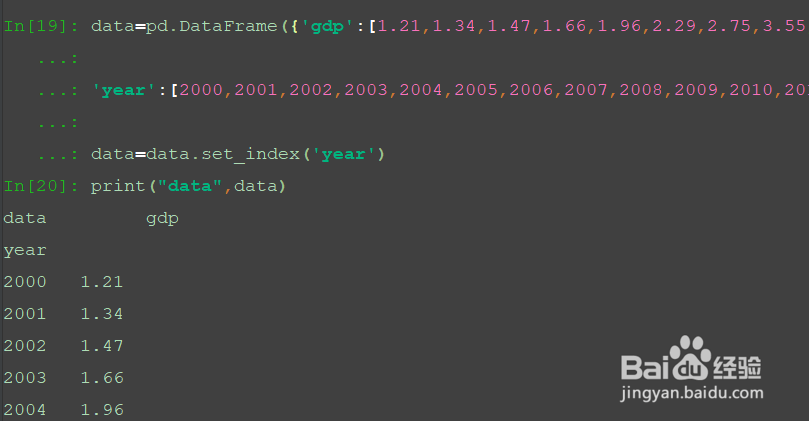
data=pd.DataFrame({'gdp':[1.21,1.34,1.47,1.66,1.96,2.29,2.75,3.55,4.59,5.1,6.09,7.55,8.53,9.57,10.44,11.02,11.14,12.14,13.61],
'year':[2000,2001,2002,2003,2004,2005,2006,2007,2008,2009,2010,2011,2012,2013,2014,2015,2016,2017,2018]})
data=data.set_index('year')
print("data",data)
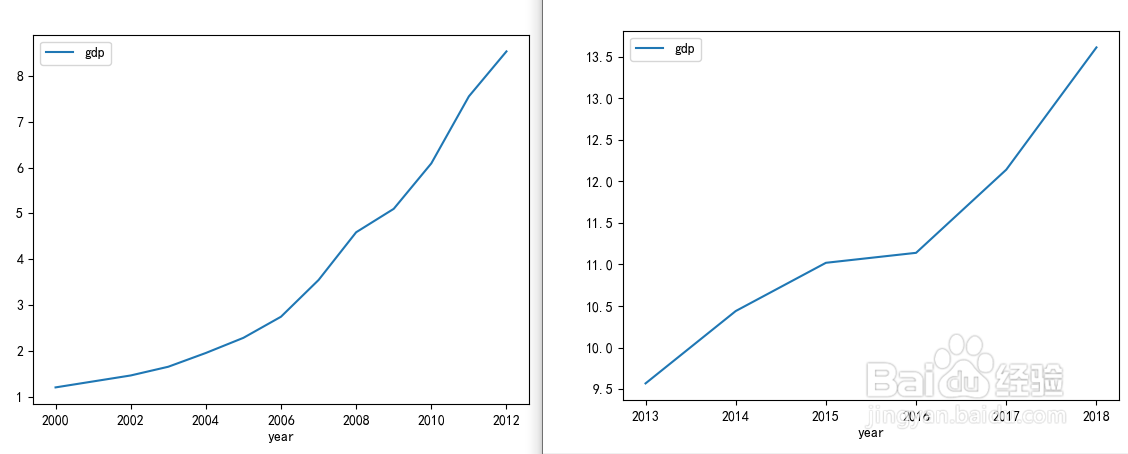
3、对数据进行分割,按照7:3的比例分割训练集和测试集
train=data[:int(0.7*len(data))]
print("训练集",train)
test=data[int(0.7*len(data)):]
print("测试集",test)
# #绘图查看训练集合测试集
import matplotlib.pyplot as plt
train.plot()
test.plot()
plt.show()

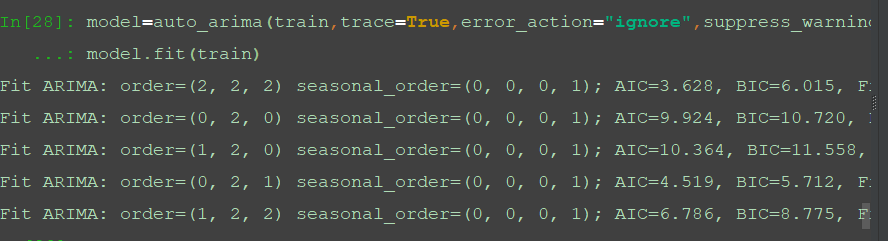
4、对训练集数据进行模型训练。
model=auto_arima(train,trace=True,error_action="ignore",suppress_warnings=True)
model.fit(train)
代码中trace表示是否显示尝试过的模型,这些选择TRUE,可以看到auto_arima的自动定阶过程。
结果中根据自动比较,找到AIC最小时对应的ARIMA(p,d,q)参数值,这里得到的结果是ARIMA(2,2,1)。如图所示。

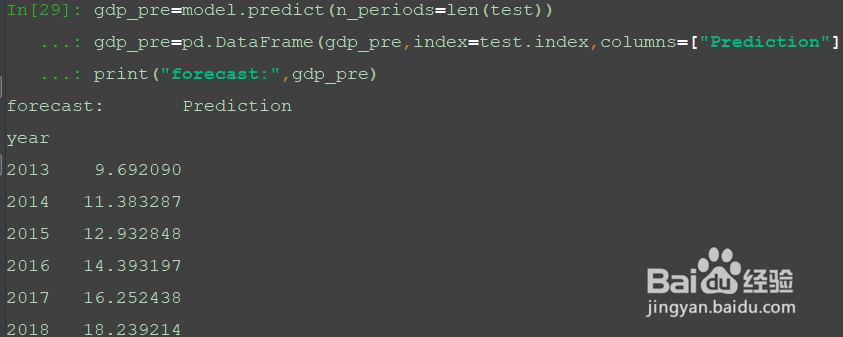
5、利用刚才建立的ARIMA(2,2,1)模型,对测试集数据进行预测。
gdp_pre=model.predict(n_periods=len(test))
gdp_pre=pd.DataFrame(gdp_pre,index=test.index,columns=["Prediction"])
print("forecast:",gdp_pre)
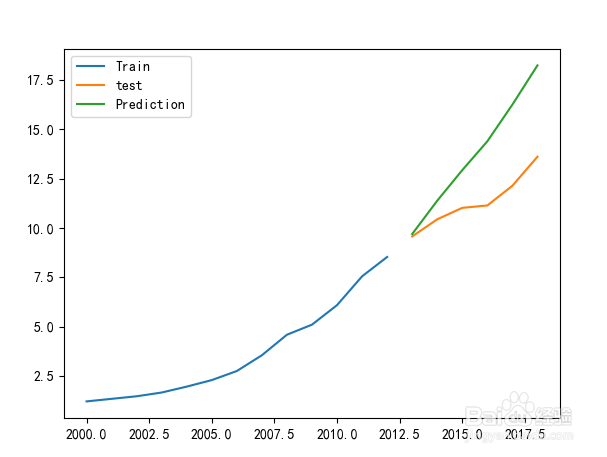
#绘制拟合曲线
plt.plot(train,label="Train")
plt.plot(test,label="test")
plt.plot(gdp_pre,label="Prediction")
plt.legend()
plt.show()
从拟合图可以看出,Arima模型对短期的预测能力较好,但是在较远的时期则具有一定偏差。
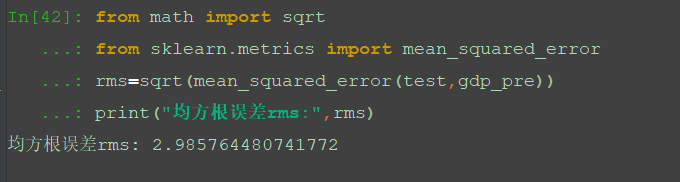
6、评价模型,计算均方根误差。
from math import sqrt
from sklearn.metrics import mean_squared_error
rms=sqrt(mean_squared_error(test,gdp_pre))
print("均方根误差rms:",rms)
根据结果可知,本次建模的均方根误差为3。