如何使用python的urllib包抓取并保存网页
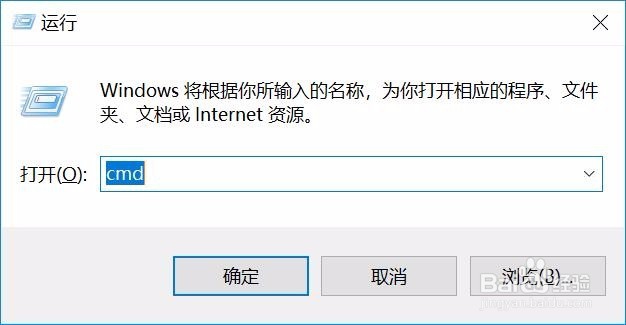
1、第一,打开cmd命令窗口,并输入python,进入python软件命令窗口。

2、第二,引入urllib包中的request模块,引入os模块。urllib是一个包,其中的request是一个模块,这个模块包含了对服务器的发出、跳转、代理和安全等方面。

3、第三,使用os模块的getcwd()函数,获取当前工作目录,并在该目录下创建001.txt文档。

4、第四,使用urllib.request的urlopen()函数访问网页,并设置编码格式为"utf8",注意此处每一个网站的格式编码不同,要根据网站的编码格式,来设置编码格式。
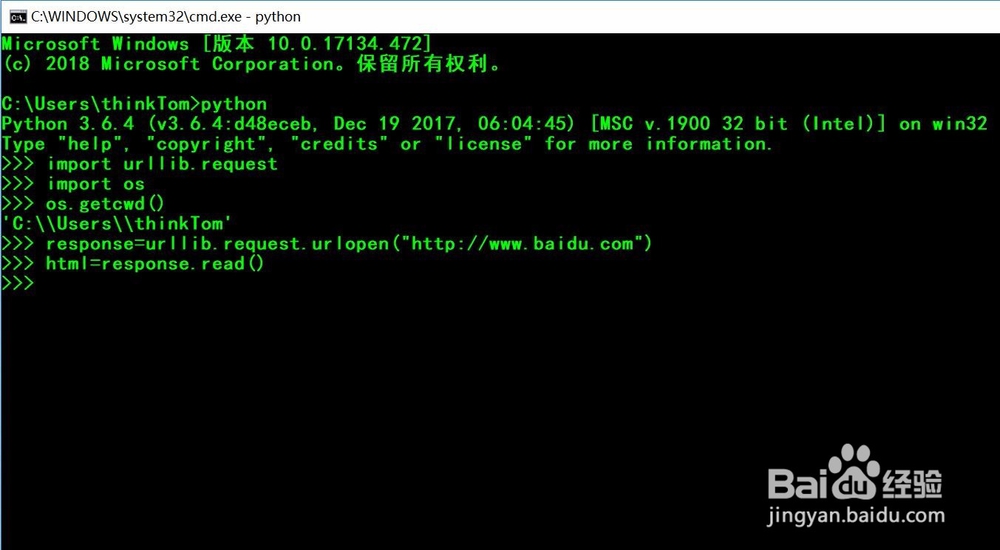
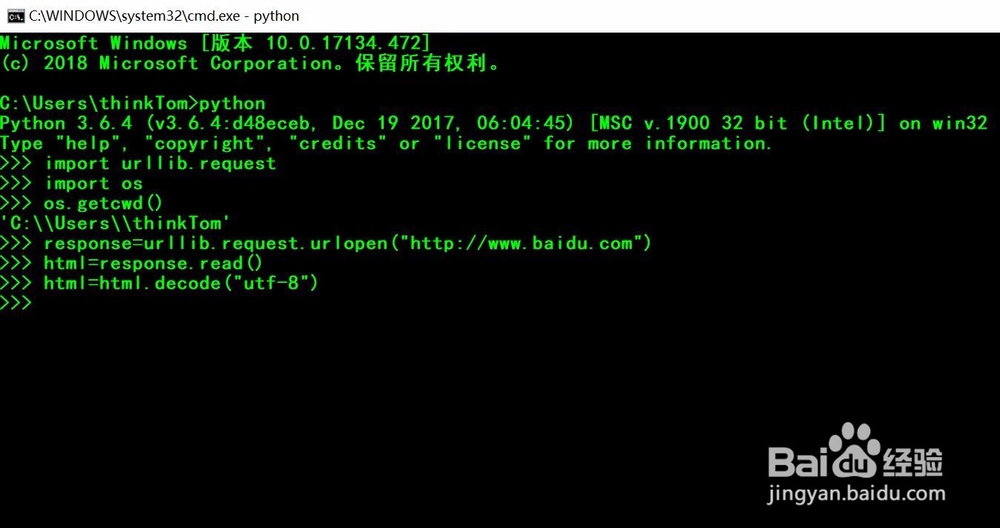
5、第五,使用函数len()获取网页文档的字符串长度,并打印出前300个字符。
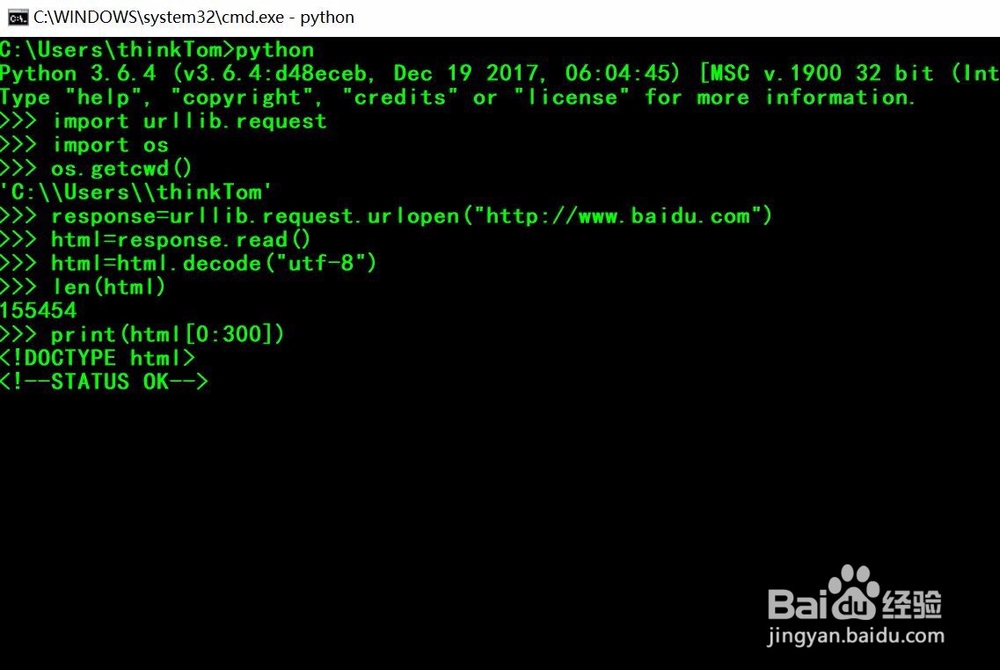
6、第六,使用函数open打开当前工作目录下的001.txt,并写入模式。
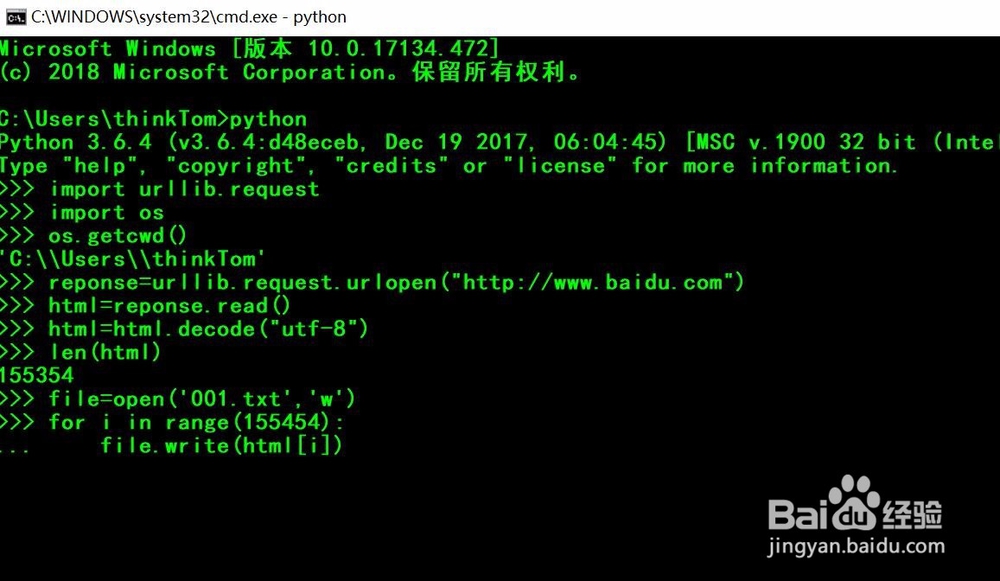
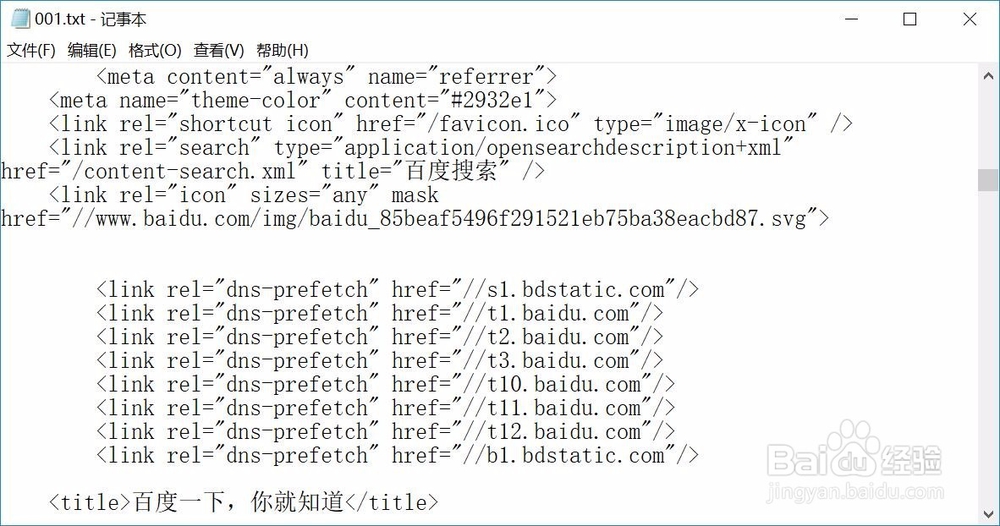
7、第七,使用一个循环语句,将要网页的内容写入001.txt,这主要使用了file对象的write()方法。写入完成后,关闭文档,打开文档001.txt查看内容。
声明:本网站引用、摘录或转载内容仅供网站访问者交流或参考,不代表本站立场,如存在版权或非法内容,请联系站长删除,联系邮箱:site.kefu@qq.com。
阅读量:143
阅读量:125
阅读量:24
阅读量:164
阅读量:118