Python爬虫之文件下载
1、怎样在网上找资源:
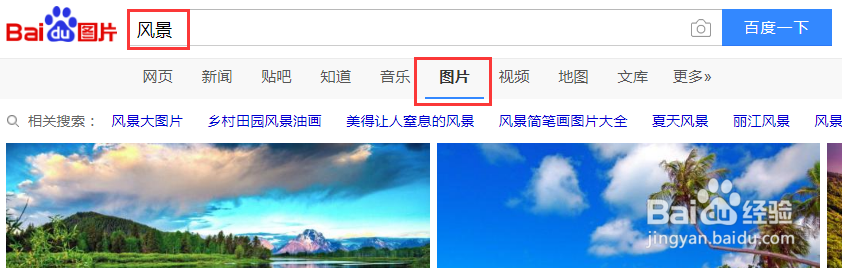
就是百度图片为例,当你如下图在百度图片里搜索一个主题时,会为你跳出一大堆相关的图片。
还有如果你想学英语,找到一个网站有很多mp3的听力资源,这些可能都是你想获取的内容。
现在是一个互联网的时代,只要你去找,基本上能找到你想要的任何资源。
2、怎样识别网页中的资源:
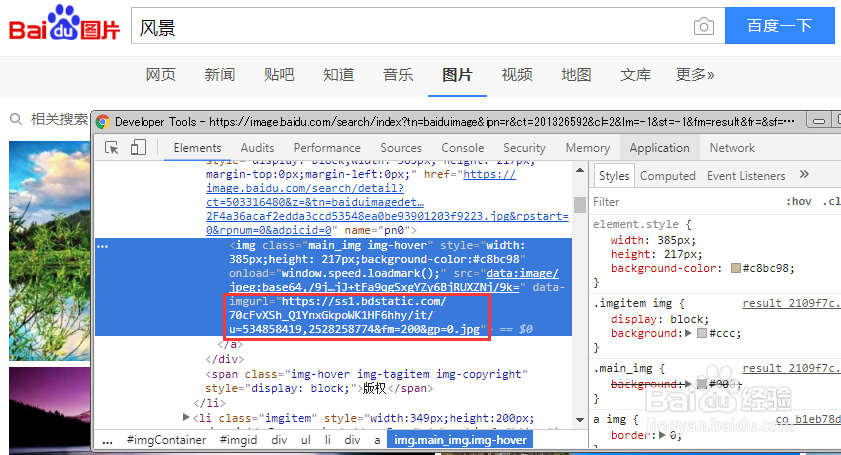
以上面搜索到的百度图片为例。找到了这么多的内容,当然你可以通过手动一张张的去保存,但这样做既费力又费事。你当然更希望通过程序自动去下载所找到的资源。要想代码识别这些资源,就要告诉代码这些资源有哪些特征,怎样在网页中找到它们。
打开浏览器的调试功能(不同浏览器可能有差别,不知道的百度一下吧)。找出网页中你想要下载资源的路径,如下图所示。如果有许多类似资源需要下载,则要找到识别这些资源地址的规律,然后告诉代码。
如果不清楚规律怎么找的读者,可以看看《BeautifulSoup解析HTML》这篇文章。
3、资源下载方法一:
代码很简单,直接上代码:
from urllib.request import urlretrieve
urlretrieve("图片URL", "./image.jpg")
直接通过urlretrieve函数就把URL对应的图片给下载到当前文件夹(./)中了,并把图片命名为image.jpg。

4、资源下载方法二:
还是直接看代码:
import requests
resource = requests.get("图片URL")
with open("./image.jpg", mode="wb") as fh:
fh.write(resource.content)
此下载方法要安装python的requests库。从功能上来说与下载方法一是一样的。python库的安装方法用pip就好。很简单,这里都不啰嗦了。

5、资源下载方法三:
看代码:
import requests
resource = requests.get("图片URL", stream=True)
with open("./image.jpg", mode="wb") as fh:
for chunk in resource.iter_content(chunk_size=100):
fh.write(chunk)
此方法与下载方法二的不同之处在于在get方法调用时使用了参数【stream=True】。而在写入的文件的时候是分块写入的。
什么意思呢:
前两种方法是把一个文件全部下载到内存后,再一起写入到硬盘文件中。
方法三是下载一定的量(这里指的是100字节)后,就写入到硬盘文件中,直到全部写完。
第三种方法的好处是,如果在下载大容量文件时,不会造成内存的过度使用。

6、资源下载说明一:
上述的代码都是通过下载图片资源为例子的,但所有其它资源,如文档,电影等的下载方式是一样的。关键是要正确的识别出网页中资源所对应的URL地址才能够正确的下载(因为有些资源是用的相对路径或加密后的路径)。

7、资源下载说明二:
上面例子中的代码都是下载单一资源的。如果要在同一网页中下载多个资源的思路如下:
1. 找出要下载资源的URL,并形成一个资源集合;
2. 把下载函数中的资源URL与保存路径参数化;
3. 遍历资源集合,依靠循环调用下载函数来达到多个资源下载的目的。
