中文分词库FNLP与jieba的安装
1、本篇讲述FNLP自然语言处理库和jieba中文分词库的安装与使用,FNLP自然语言处理库适合Java开发者学习中文分词处理,jieba中文分词库适合Python开发者学习中文分词处理。通过本篇的学习,可以掌握如下内容。
● FNLP分词库的安装与使用
● jieba分词库的安装与使用
注意:
本篇如无特殊说明,所涉软件均在Windows操作系统下操作。
Java和Python均使用eclipse集成开发工具。
1、FNLP分词库的安装与使用
FNLP是由复旦大学开发的一个基于机器学习的中文自然语言处理开发工具包,也包含为实现这些任务的机器学习算法和数据集,中文分词功能是FNLP库的核心功能之一。
FNLP分词库的安装
(1)FNLP库在github托管源代码,通过github下载整个项目代码压缩包。下载地址:
github.com/FudanNLP/fnlp
(2)从github下载3个模型文件,分别是seg.m(分词模型)、pos.m(词性标注模型)、dep.m(依存句法分析模型),将下载的这3个模型文件复制到fnlp项目models目录下。模型文件下载地址:
github.com/FudanNLP/fnlp/releases
(3)由于从github下载的是FNLP的源代码,需要通过Maven构建项目。下载Maven并安装,Maven下载地址:
maven.apache.org/download.cgi
在下载列表中,选择Binary zip archive类别的ZIP压缩包下载。
① 将下载的zip压缩包解压至任意目录(目录名称不要包含中文)。
② 添加bin目录的路径到Path系统环境变量。
③ 验证是否配置成功,在Windows命令行窗口输入mvn -v命令,显示信息如下图所示。
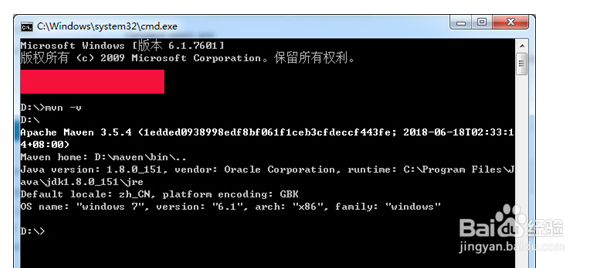
2、如果没有显示上述内容,请检查JDK是否安装、JDK的版本及环境变量是否配置正确。
(4)在Windows命令行窗口,进入FNLP源码目录(即“README.md”文件所在的目录),输入命令:
mvn install -Dmaven.test.skip=true
win10系统如果进入的是powershell,则使用命令:
mvn install '-Dmaven.test.skip=true'
执行命令后,Maven开始构建项目,Maven会构建4个Jar包文件,分别位于源码目录的target目录。例如,fnlp-core的软件包位于: fnlp-core/target/fnlp-core-2.0-SNAPSHOT.jar。
注意:如果构建过程中出现Could not resolve dependencies for project错误,问题原因是缺少构建FNLP所需要的依赖包,从FNLP的镜像网盘下载Trove和Commons-cli两个Jar包到项目源码目录。
使用FNLP库的分词功能
FNLP的中文分词、词性标注、实体名识别等功能已经封装在工厂类CNFactory之中。使用eclipse新建Java项目WordSegment,导入FNLP的Jar包:
fnlp-core-2.1-SNAPSHOT.jar
trove4j-3.0.3.jar
commons-cli-1.2.jar
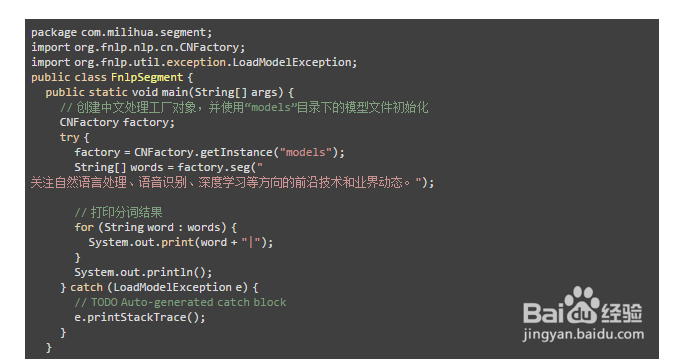
将FNLP的models目录拷贝到项目目录下,在src目录下新建com.milihua.segment包,并在该包下创建FnlpSegment类文件,代码如下:
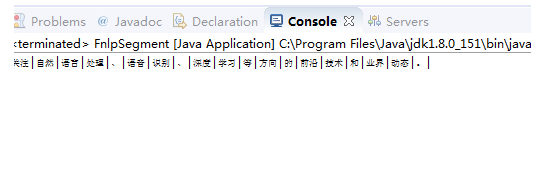
3、执行FnlpSegment.class文件,输出结果如下图所示。
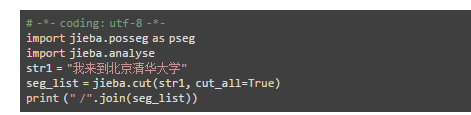
4、jieba中文分词库的安装及使用
Jieba是基于Python技术的中文分词库,jieba提供了三种精确模式、全模式、搜索引擎模式三种分词模式,应用到不同场景。
jieba分词库的安装
jieba分词库的安装非常简单,在Windows命令行窗口,输入命令:
pip install jieba
执行命令后,pip工具将从网上自动下载jieba安装包进行安装。安装完成后如下图所示。
5、使用jieba库的分词功能
使用eclipse新建Python项目JiebaSegment,新建src包,在该包下面新建WordSegment模块。WordSegment模块代码如下: