Python实例讲解XPath语法
1、打开Python开发工具IDLE,新建‘xpath.py’文件,xpath要用lxml包,尝试导入包,写代码如下:
from lxml import etree
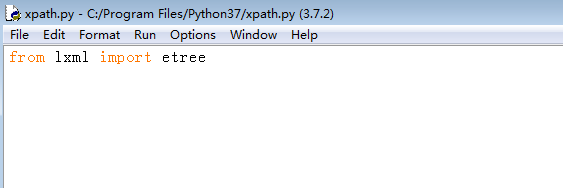
2、F5运行程序,报错,提示没有lxml包

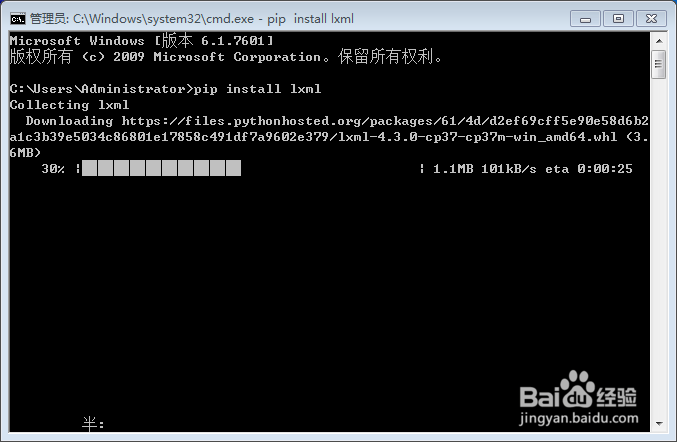
3、使用pip安装lxml包,打开电脑运行,输入‘cmd’进入命令行窗口。输入
pip install lxml
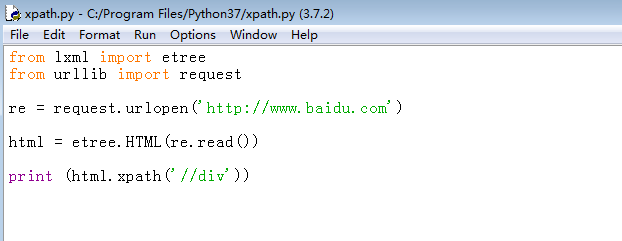
4、再次运行程序,没有报错,lxml包安装成功,下面是用urllib发送请求获取网络,再用xpath进行解析,代码如下:
from lxml import etree
from urllib import request
re = request.urlopen('http://www.baidu.com')
html = etree.HTML(re.read())
print (html.xpath('//div'))
这是通过标签查找,//查找根目录下所有符合条件的
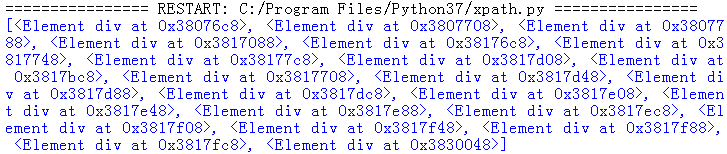
5、F5运行程序,打印根目录下所有div标签
6、xpath定位需要提前直到网页的布局,标签属性等,下面查找
http://www.coder1024.site 的‘python’
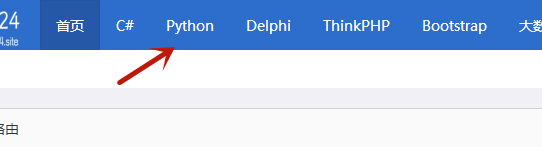

7、简单的xpath定位方法有几下集中
// 根目录下所有
/ 当前路径下一层
text() 标签内文本
[@] 标签属性查找,多个属性值[contains(@class,"")]另外还有starts-with等函数
. 当前节点
..当前节点父节点
知道上面的方法基本就够了
下面写查找http://www.coder1024.site 的‘python’代码如下
from lxml import etree
from urllib import request
re = request.urlopen('http://www.coder1024.site')
html = etree.HTML(re.read())
print (html.xpath('//li[@id="menu-item-7"]/a/text()'))
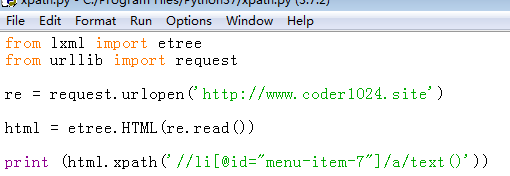
8、F5运行程序,成功查找到python文本
