爬虫入门教程
1、打开Python编辑器。
>>> import requests
>>> html = requests.get('百度')
这里以百度为示范,引入requests库,对网页进行请求。
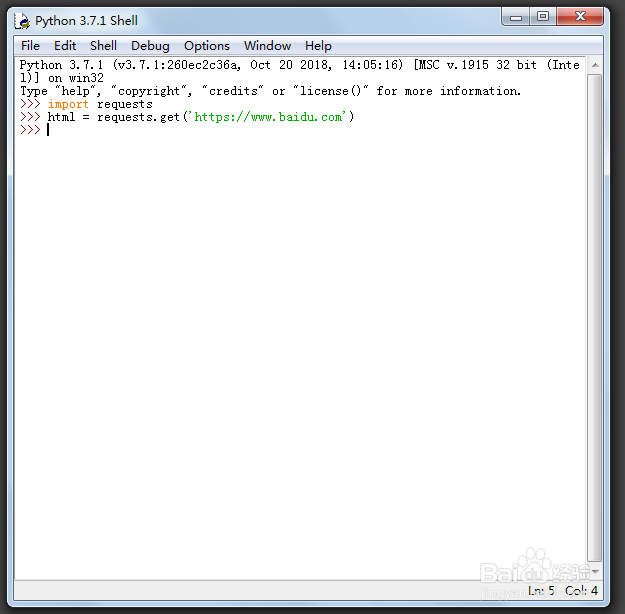
2、>>> html.raise_for_status()
>>> print(html)
<Response [200]>
我们看一下状态是否有问题,200证明打开网页没问题。

3、>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(html.content, 'lxml')
>>> print(soup)
这个时候我们需要借助BeautifulSoup和lxml来解析网页,并且打印一下,看一下有没问题问题。

4、我们到百度网页,右键单击检查元素,查看代码是否和刚刚的一致。

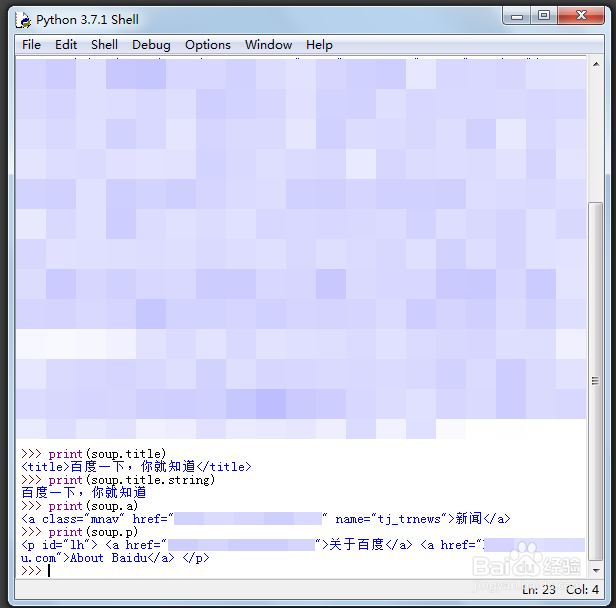
5、>>> print(soup.title)
<title>百度一下,你就知道</title>
>>> print(soup.title.string)
百度一下,你就知道
没问题,我们就开始下一步,最简单的就是爬取网页的名字和标题。

6、>>> print(soup.a)
>>> print(soup.p)
但是我们需求比较多的是要获得便签的内容,比如a和p,但是这里只能返回一个数据。
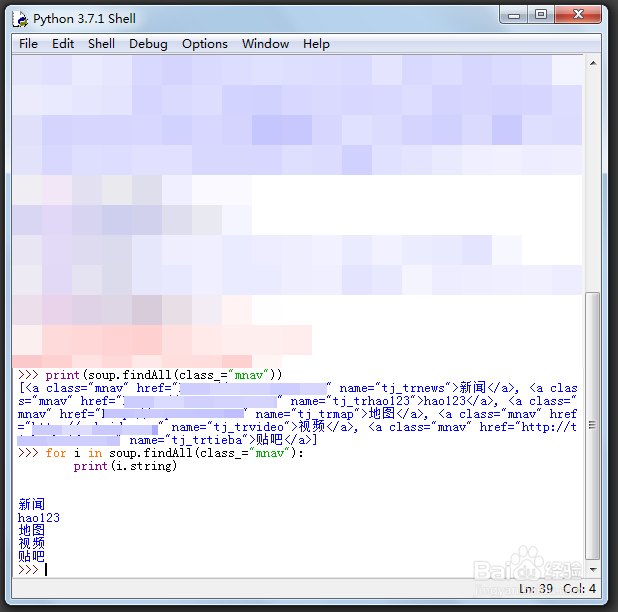
7、>>> print(soup.findAll(class_="mnav"))
>>> for i in soup.findAll(class_="mnav"):
print(i.string)
因此我们可以借助findAll来进行查找全部,class来进行定位。
8、>>> for i in soup.findAll(class_="mnav"):
print(i.get("href"))
还有一个入门必须知道的就是获取里面的链接,一般都是要获取href。
