android学习札记第6章之集合二(List、Map、Set)
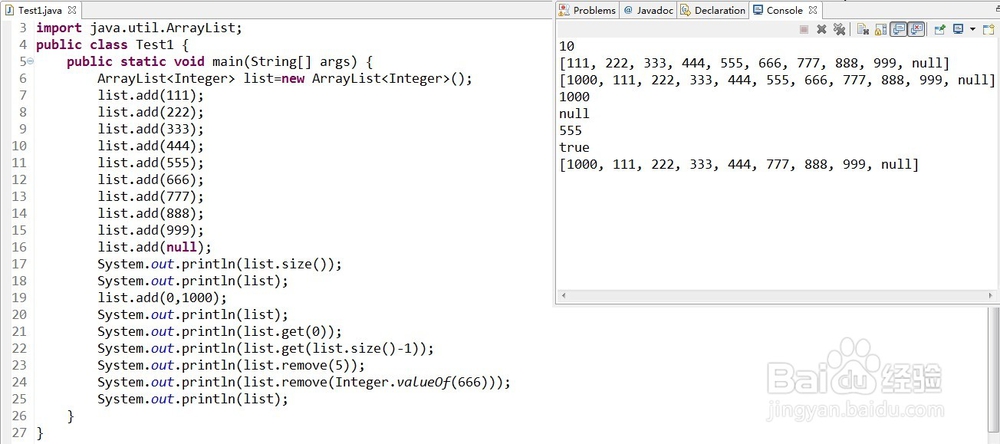
1、①ArrayList内部用数组来存放数据,数据放满后会创建新数组存放,原数组将不存在。
访问任意位置效率高,添加、删除数据时,效率可能降低。
②创建对象:
ArrayList list=new ArrayList();//默认内部的数组最大长度是10,list.size()==0
ArrayList list=new ArrayList(100);//内部的数组最大长度是100,list.size()==0

2、①ArrayList的方法:
与LinkedList相同,但是ArrayList没有两端操作数据的方法。
ArrayList中如果有空位置插入效率高,如果没有空位置插入效率低。
②ArrayList和LinkedList抉择:
只在两端操作数据,选择LinkedList,否则选择ArrayList。ArrayList查询时根据下标查询,所以要比LinkedList查询快。
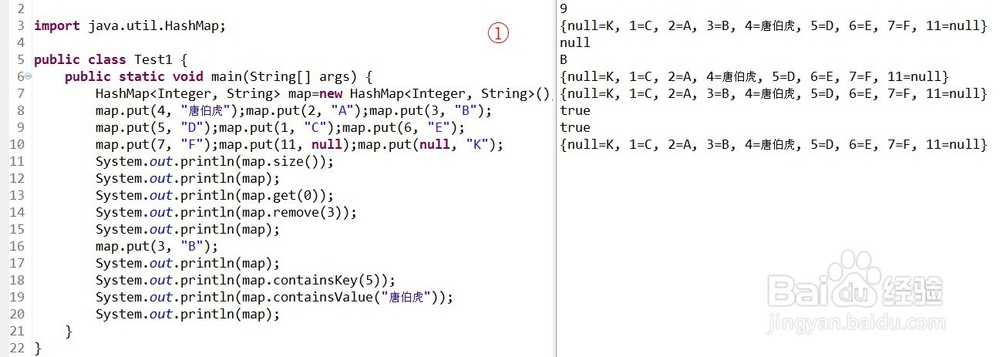
1、①哈希表(算法),散列表(算法),无序(但如果hashcode不变,位置不变)。存放“键值对”数据,作用:用“键”快速查找数据,键值对不能重复,重复将会覆盖。
②创建对象:
HashMap<Integer, String> hashmap=new HashMap<Integer, String>();
③HashMap的方法:
put(key,value):添加数据
get(int index):获取指定键的值
remove(int index):移除数据,返回数据
containsKey(key):判断时候包含key
containsValue(value):判断时候包含value
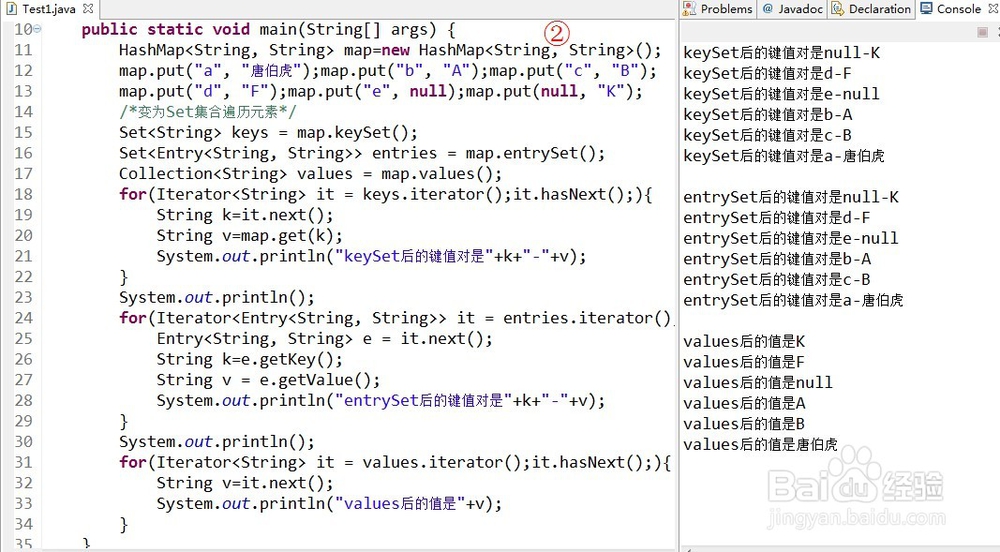
keySet():将键取出,返回Set。
entrySet():将键和值的封装对象取出,返回Set。
values():将值取出,返回Collection。
2、HashMap练习:
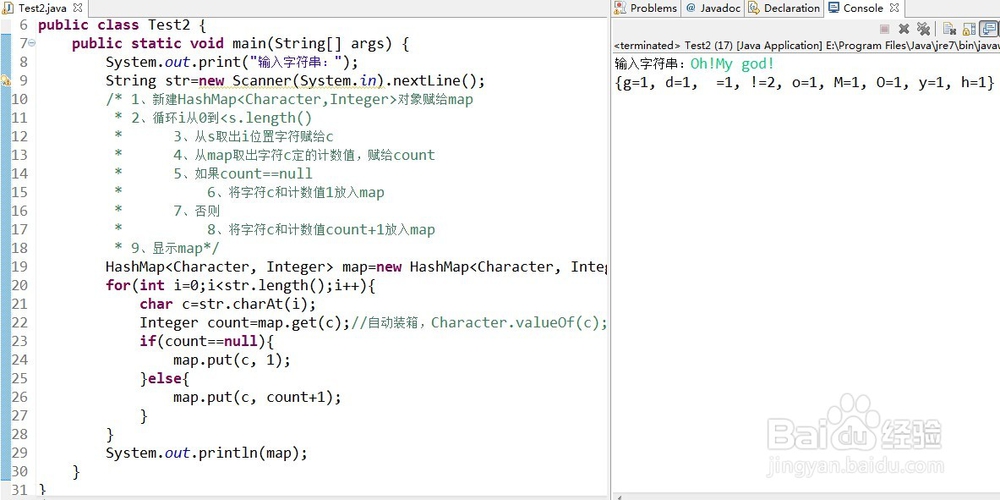
输入字符串,计算每种字符出现的个数。
思路:先把循环字符串,然后判断map中的key有没有值,如果没有就value=1,如果有就把value+1。
(其中map的key是字符串中的字符,value是字符的数量。)
3、哈希算法:
Ⅰ、存放:
A、取得键的哈希值key.hasCode()
B、用哈希值计算下标index
C、key和value封装成Entry对象
D、将Entry对象放入index位置
D1、如果index是空位置,直接放入
D2、如果index位置已经有数据,用equals依次比较每个键是否相等
如果找到相等的键就覆盖值
D3、如果index位置已经有数据,用equals依次比较每个键是否相等
如果没有找到相等的键就作为链表连在一起,2个Entry对象形成链表。
形成链表越来越多,会影响效率。
如果达到一定的负载率(75%),容量会翻倍。
Ⅱ、查找数据:
A、取得键的哈希值key.hasCode()
B、用哈希值计算下标index
C、如果index位置是空位置,返回null
D、如果index位置有数据,依次和每一个键用equals()比较是否相等
D1:找到相等的,返回值
D2:找不到相等的,返回null
Ⅲ、hashCode():
获得一个对象的哈希值,参与哈希运算
Obuect的实现是用内存地址值作为哈希值
如果对象作为哈希表的键存放,必须重写hashCode()。
equals()相同,hashCode()必须相同;hashCode()相同,equals()可以不同。
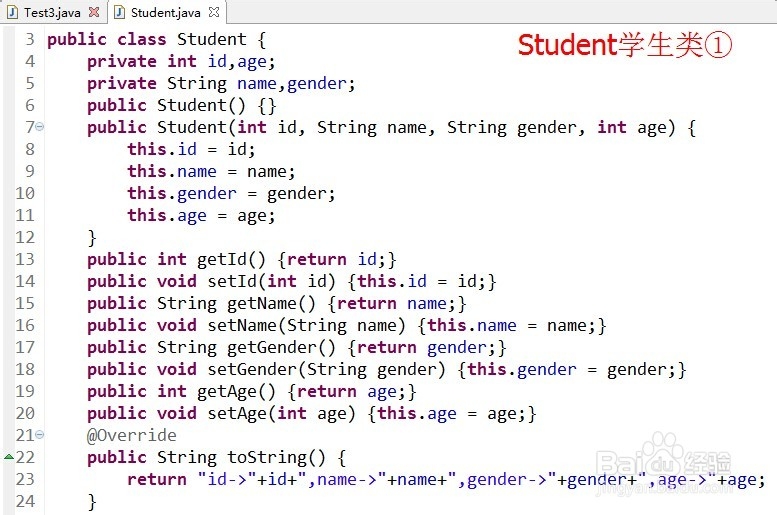
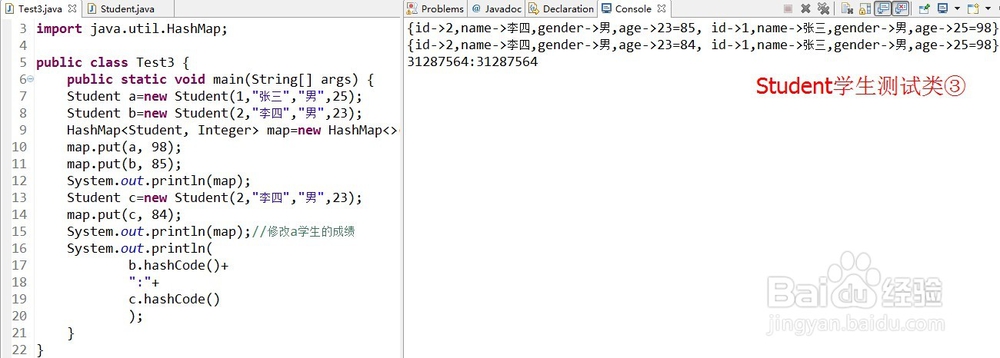
Ⅳ、下面以学生类为例,验证Map集合中是通过hashCode作为内存地址,并参与对象之间的运算,需要重写才能使对象之间相等的。


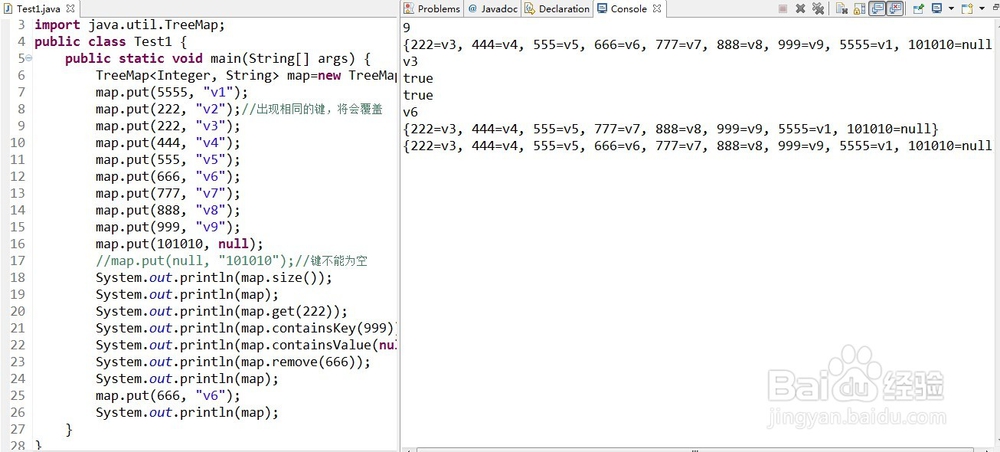
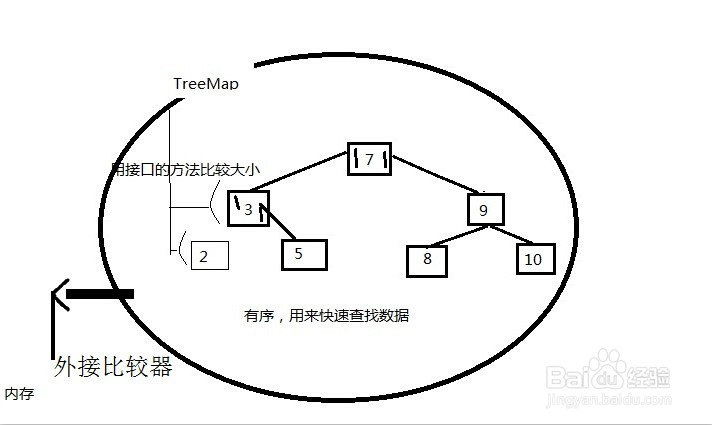
1、①TreeMap又叫二叉树、红黑树,用来快速查找数据,有序,键从小到大排列。
②创建对象:
TreeMap map=new TreeMap();
TreeMap map=new TreeMap(比较器对象);//外接一个比较器对象Comparator。
2、①TreeMap的方法:
和HashMap相同,除了有序。
keySet():将键取出,返回Set。
entrySet():将键和值的封装对象取出,返回Set。
values():将值取出,返回Collection。
比较2个对象的大小、排序方法:
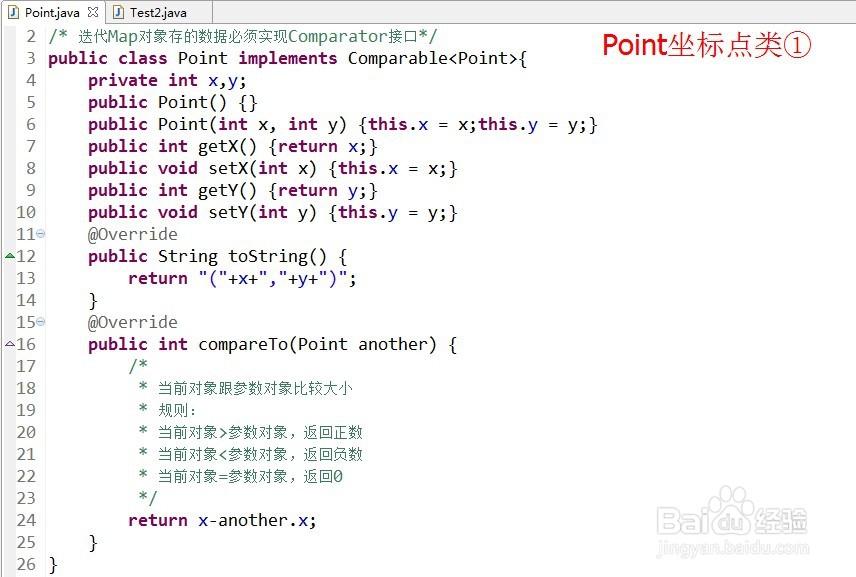
A:需要实现Comparable接口,并重写compareTo方法。
执行阶段:在TreeMap的put方法中,当把对象以参数传进去,就已经比较大小了。
B:需要外接比较器Comparator对象,并把被比较的对象传参传进去。(回调模式Callback)
②练习:
把点对象Point和销售额作为键值对存入TreeMap。

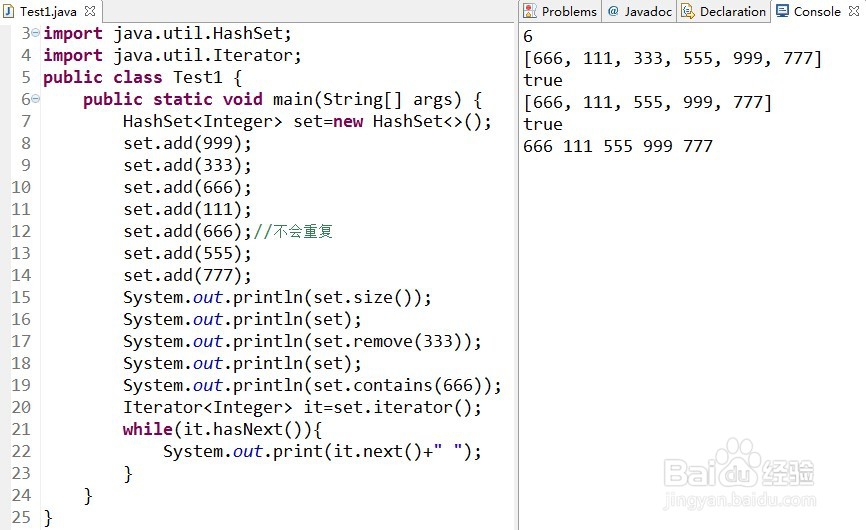
1、①用哈希算法,存放单个数据。
内部使用HashMap的“键”来存放数据。不重复,无序。
②创建对象:
HashSet<Integer> set=new HashSet<>();

2、HashSet的方法:
add():添加元素,不会重复。
remove():删除某元素,返回boolean值。
size():集合的大小。
iterator():迭代集合的元素。
contains():判断是否含有某元素。
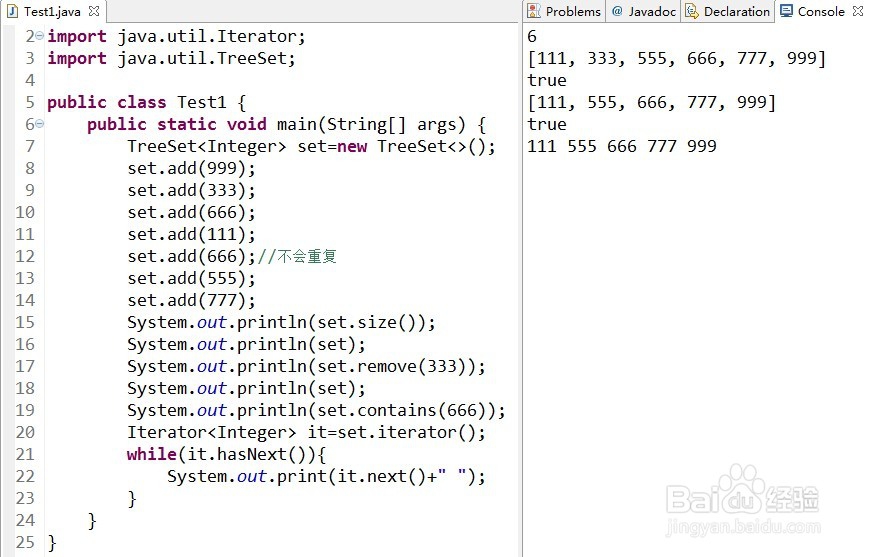
1、①内部使用TreeMap的“键”存放数据。不会重复,有序。
②创建对象:
TreeSet<Integer> set=new TreeSet<>();
TreeSet<Integer> set=new TreeSet<>(比较器对象);
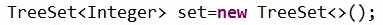
2、TreeSet的方法:
add():添加元素,不会重复。
remove():删除某元素,返回boolean值。
size():集合的大小。
iterator():迭代集合的元素。
contains():判断是否含有某元素。