Hadoop快速入门
1、安装软件
如果你的集群尚未安装所需软件,你得首先安装它们。
以linux系统为例,见下图。

2、运行Hadoop集群的准备工作
解压所下载的Hadoop发行版。编辑 conf/hadoop-env.sh文件,至少需要将JAVA_HOME设置为Java安装根路径。
尝试如下命令:$ bin/hadoop 将会显示hadoop 脚本的使用文档。
现在你可以用以下三种支持的模式中的一种启动Hadoop集群:
单机模式
伪分布式模式
完全分布式模式
单机模式的操作方法
默认情况下,Hadoop被配置成以非分布式模式运行的一个独立Java进程。这对调试非常有帮助。

3、伪分布式模式的操作方法
Hadoop可以在单节点上以所谓的伪分布式模式运行,此时每一个Hadoop守护进程都作为一个独立的Java进程运行。
配置
使用如下的 conf/hadoop-site.xml:
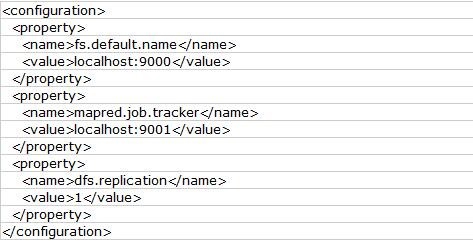
4、免密码ssh设置
如果不输入口令就无法用ssh登陆localhost,执行下图的命令:
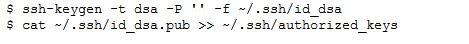
5、执行
格式化一个新的分布式文件系统,如下图命令。

6、启动Hadoop守护进程:$ bin/start-all.sh
Hadoop守护进程的日志写入到 ${HADOOP_LOG_DIR} 目录 (默认是 ${HADOOP_HOME}/logs).
浏览NameNode和JobTracker的网络接口,它们的地址默认为:
NameNode - http://localhost:50070/
JobTracker - http://localhost:50030/
将输入文件拷贝到分布式文件系统:$ bin/hadoop fs -put conf input
运行发行版提供的示例程序:$ bin/hadoop jar hadoop-*-examples.jar grep input output 'dfs[a-z.]+'
查看输出文件:
将输出文件从分布式文件系统拷贝到本地文件系统查看:$ bin/hadoop fs -get output output $ cat output/*
或者
在分布式文件系统上查看输出文件:$ bin/hadoop fs -cat output/*
完成全部操作后,停止守护进程:$ bin/stop-all.sh