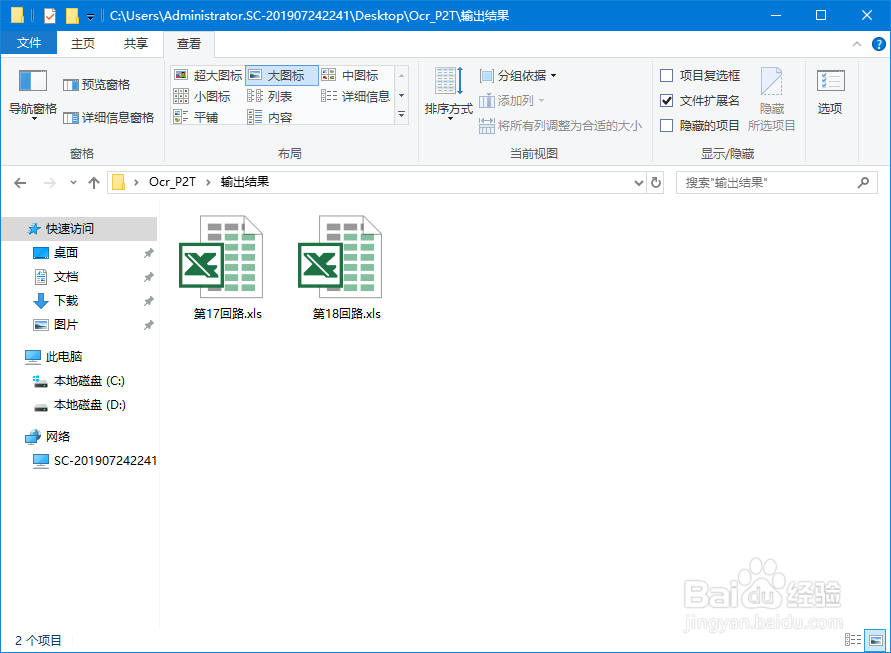
Python环境下百度Ocr表格批量识别
1、安装Python 3。请自行下载安装,记住安装路径,后面需要用。
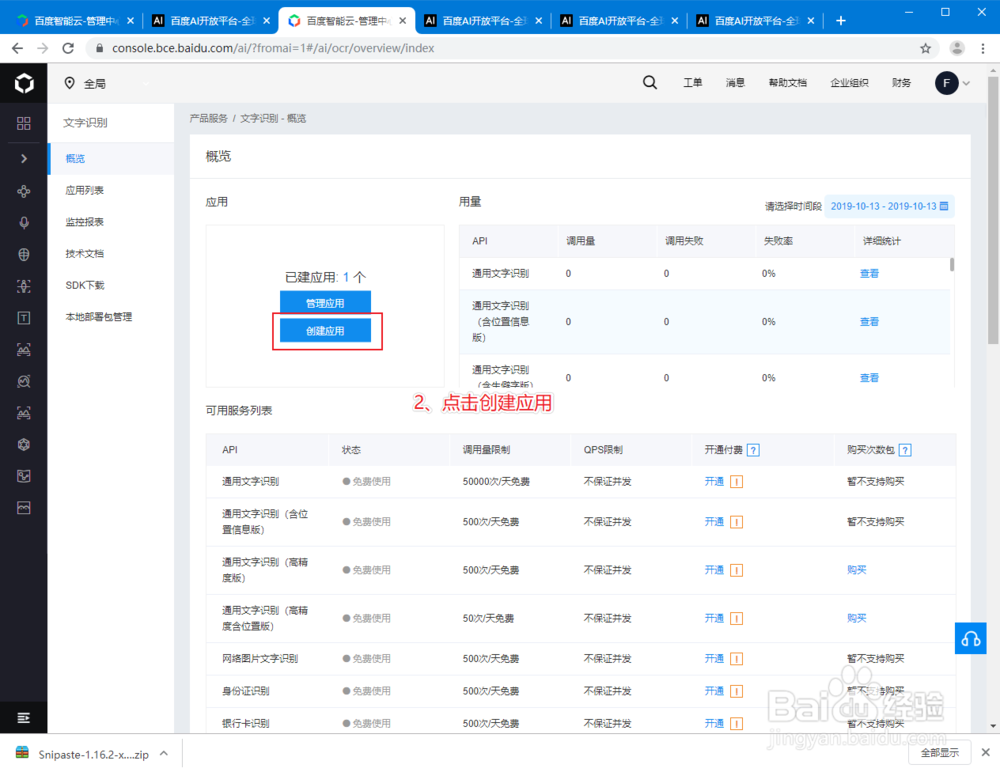
2、注册并登录百度AI开放平台(http://ai.baidu.com/)控制台。

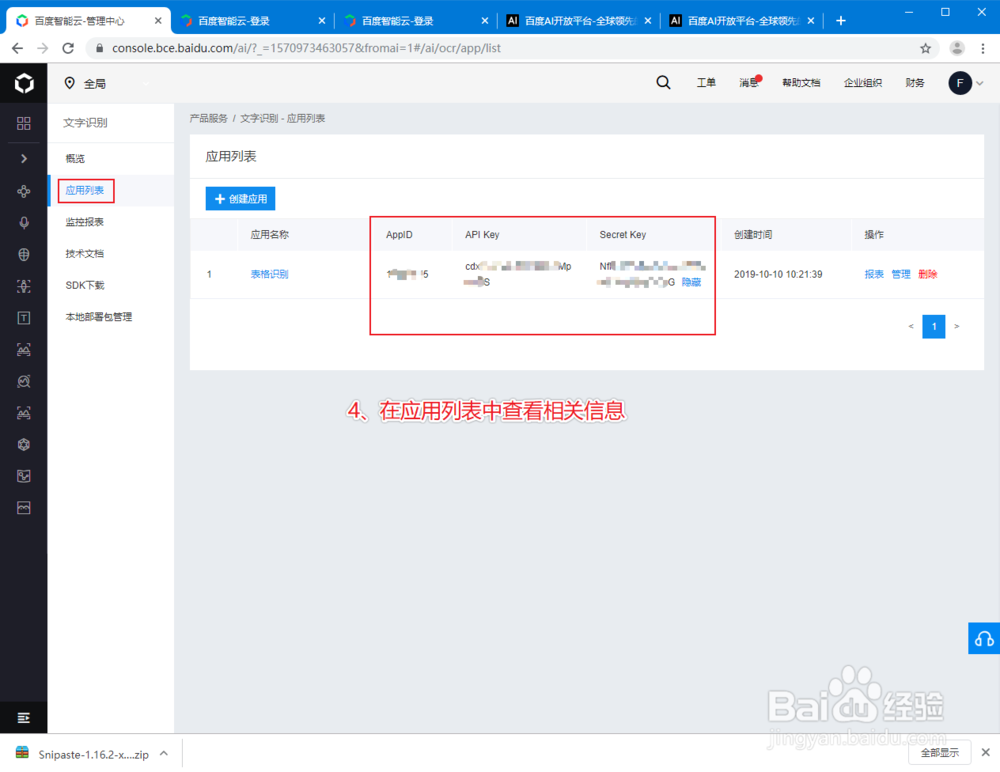
3、创建文字识别应用,并记下该应用的AppID、API Key和Secret Key。


4、安装OCR Python SDK。
1、如果已安装pip,执行pip install baidu-aip即可。
2、如果已安装setuptools,执行python setup.py install即可。
下面我们使用方法1安装SDK。



5、执行pip install baidu-aip安装OCR Python SDK。
1、快捷键win+r,打开运行窗口;输入cmd,并确定,打开MS-DOS;
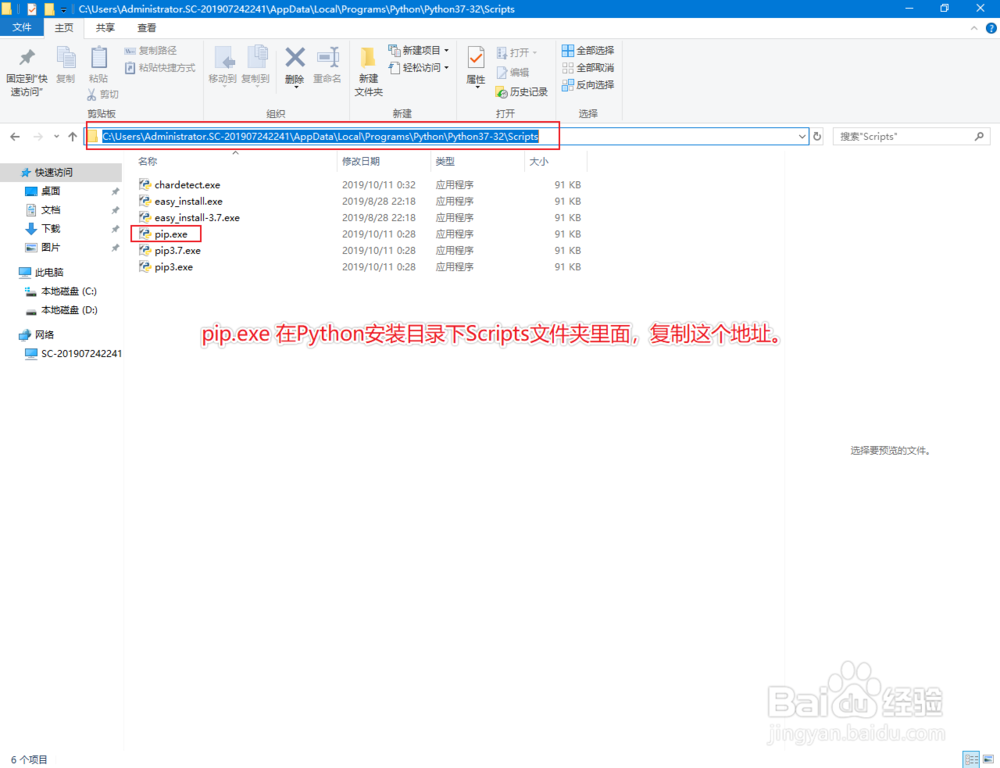
2、使用cd命令,进入Python安装目录下Scripts文件夹(pip.exe在这个文件夹里面);
3、执行pip install baidu-aip等待安装完毕(如因网络问题未成功,多执行几次即可)。

1、打开代码编辑器编写代码,可以用WINDOWS自带的记事本编写,保存后将".txt"后缀改成".py"。这里我们用Python自带的IDLE编写。


2、运行流程:
1、选择图片所在文件夹;
2、选择输出文件夹;
3、调用百度文字识别功能进行分析;
4、查询是否处理完毕,如果处理完毕,获取成功后的".xls"连接地址,并下载。
3、参考代码:(Python对代码行缩进要求比较高,复制下列的代码请注意这一点,参考上图)
# ----------------------------------------
# Python环境下百度Ocr表格批量识别
# Email:fryflying@outlook.com
# ----------------------------------------
import os #加载操作系统模块
from aip import AipOcr #调用百度Ocr模块
import requests #调用反馈模块
import time #调用时间模块
import tkinter as tk #调用GUI图形模块
from tkinter import filedialog
#KEY信息,请输入自己申请的应用信息
APP_ID = '1******5'
API_KEY = 'c****************************S'
SECRET_KEY = 'N**************************************G'
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
#读取文件函数(返回读取结果)
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
#文件下载函数
def file_download(url, file_path):
r = requests.get(url)
with open(file_path, 'wb') as f:
f.write(r.content)
root = tk.Tk()
root.withdraw()
data_dir = filedialog.askdirectory(title='请选择图片文件夹')+'/' #用对话框选择图片存储文件夹
result_dir = filedialog.askdirectory(title='请选择输出文件夹')+'/' #自选输出文件夹
num = 0
for name in os.listdir(data_dir):
print('{0}: {1} 正在处理:'.format(num+1, name.split('.')[0]))
image = get_file_content(os.path.join(data_dir,name)) #调用读取图片子程序
res = client.tableRecognitionAsync(image) #调用表格文字识别
req_id = res['result'][0]['request_id'] #获取识别ID号
for count in range(1,10): #OCR识别也需要一定时间,设定10秒内每隔1秒查询一次
res = client.getTableRecognitionResult(req_id) #通过ID获取表格文件XLS地址
print(res['result']['ret_msg'])
if res['result']['ret_msg'] == '已完成':
break #云端处理完毕,成功获取表格文件下载地址,跳出循环
else:
time.sleep(1)
url = res['result']['result_data']
xls_name = name.split('.')[0] + '.xls'
file_download(url, os.path.join(result_dir, xls_name)) #调用文件下载子程序
num = num + 1
print('{0}: {1} 下载完成。'.format(num, xls_name))
time.sleep(1)
4、运行程序:
方法一:直接双击"***.py"运行文件;
方法二:右键"***.py"使用IDLE打开,按F5执行;(此方法方便调试)

1、准备待测试图片
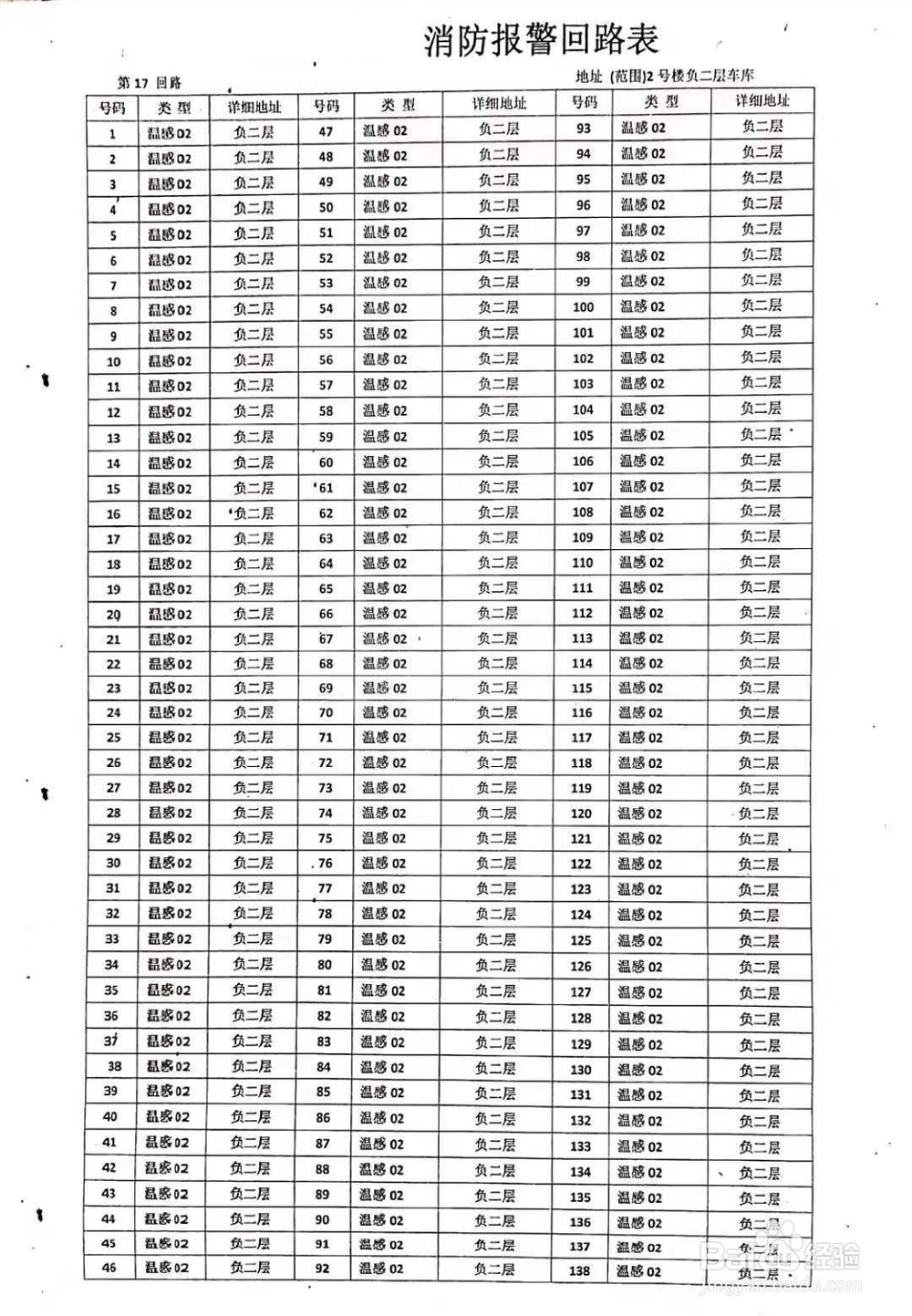

2、执行过程


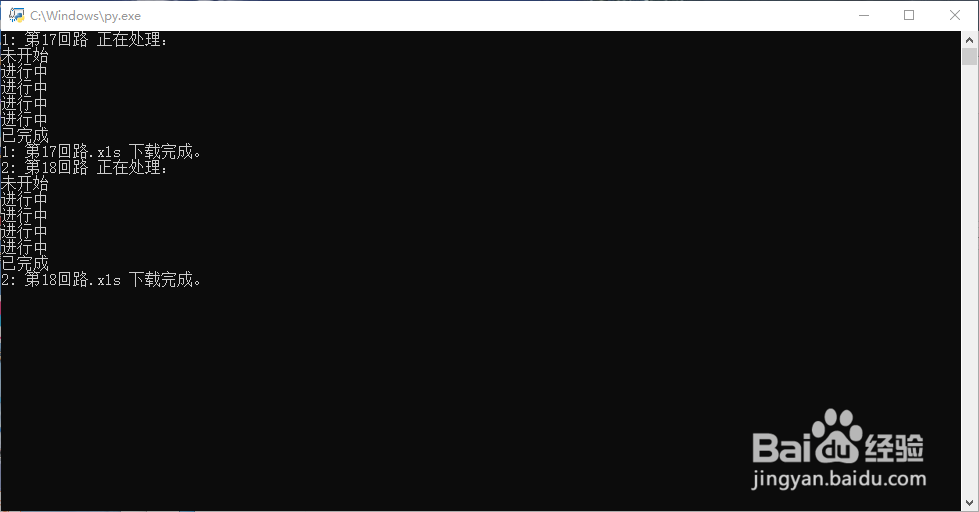
3、执行结果