字符串和字符串编码问题
1、因为全世界有很多编程人员,有很多语言,不同的国家使用不同的语言,如果说没有一套统一的编码规则,这么多语言混在一起,很容易出现乱码现象,本着既方便又节约内存的理念大家基本都是由utf-8码来编写程序。
2、计算机内存中,一般统一使用Unicode编码,当我们需要保存到硬盘的时候,就需要转换成UTF-8编码。我们浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器。我们在网页上也可以看到编码情况。
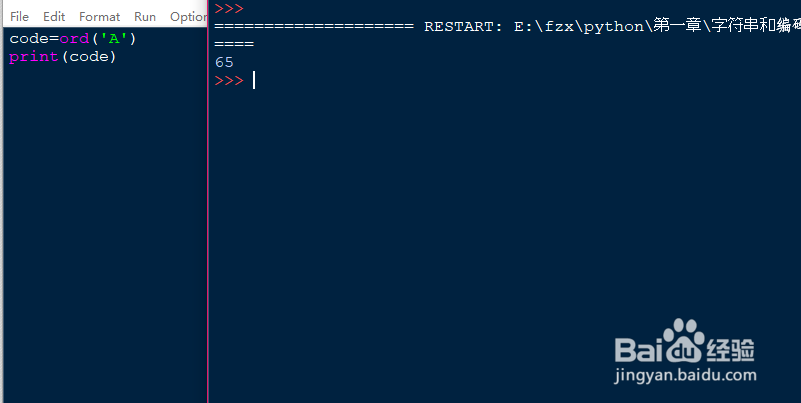
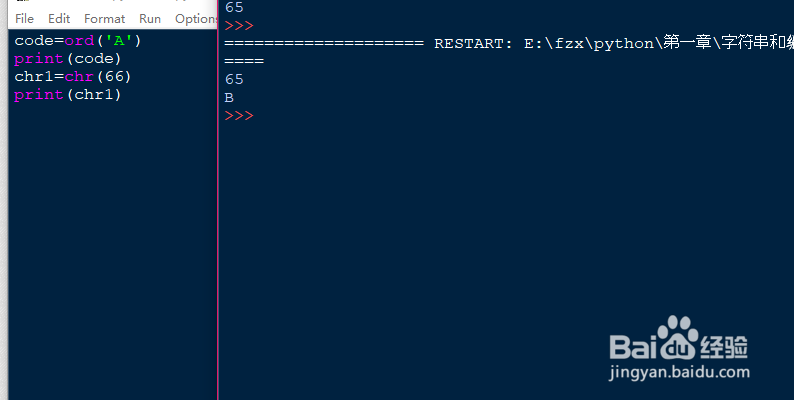
3、想要知道单个字符的编码,可以使用python给出的ord()函数来查看。如果相反的想要知道一个数字的编码对应的字符,需要调用chr()函数来查看,两个函数刚好是反向查询。如图所示,想要知道字符A对应的编码,ord括号中的字符同样需要单引号括起来。得出对应的编码为65,反向的我们可以查看66对应的字符是什么。
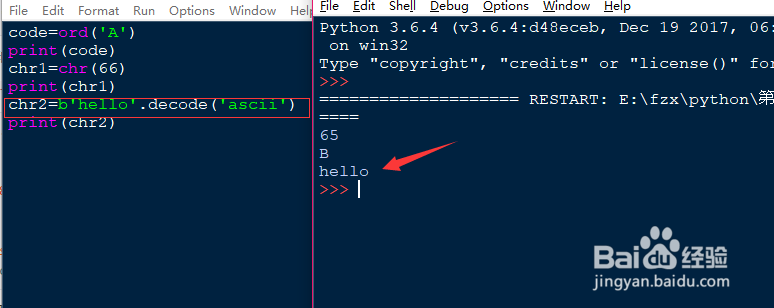
4、当我们读取数据的时候,从网上或者硬盘读到字节流,也就是字节(bytes),我们需要把字节转化为字符串来看内部信息。这时候需要用到decode()函数。纯英文的字符串可以使用ASCII码来编码,含有中文的字符串就不能使用ASCII编码,系统会报错,这时候需要utf-8来编码。
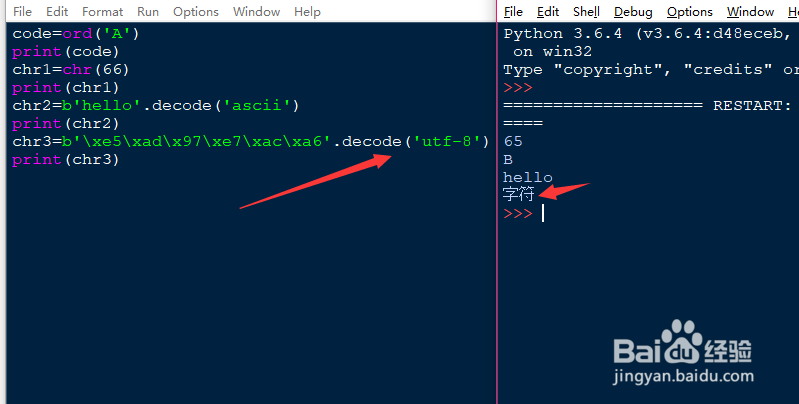
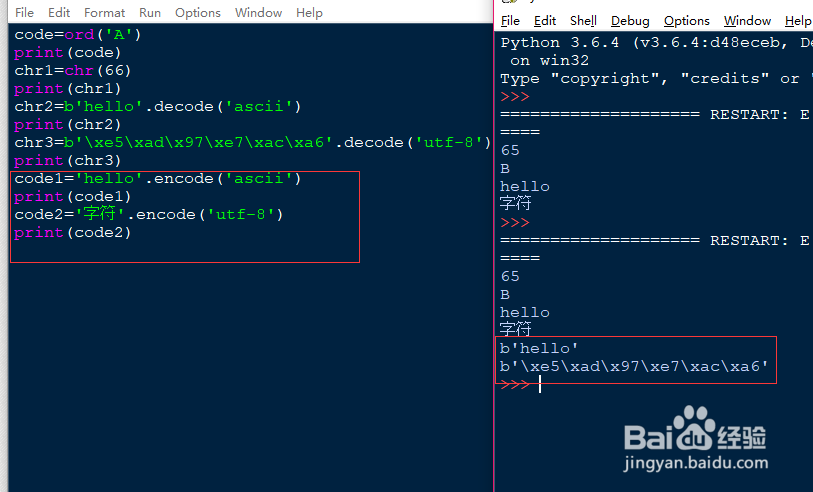
5、相反的如果我们需要知道一个字符串对应的编码,需要使用encode()函数来查询。使用方法是字符串.encode(),括号中填写编码形式,同样需要使用单引号括起来。
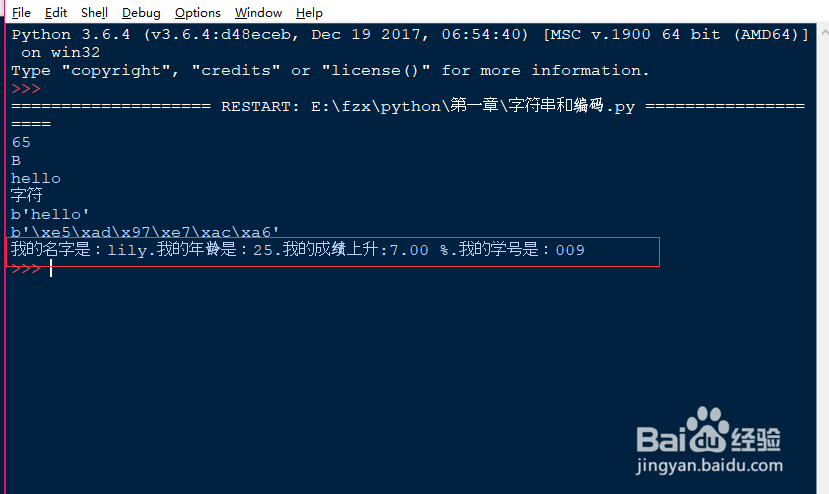
6、关于字符串还需要知道的是如何输出格式化的字符串,输出形式和C语言相同,使用%加上特殊的字母来完成,比如以整数形式输出%d,以浮点数形式输出%f,以字符串形式输出%s。注意符号%的输出方式,以及整数学号的输出,浮点数小数点位数的设置。

声明:本网站引用、摘录或转载内容仅供网站访问者交流或参考,不代表本站立场,如存在版权或非法内容,请联系站长删除,联系邮箱:site.kefu@qq.com。
阅读量:96
阅读量:162
阅读量:52
阅读量:113
阅读量:67