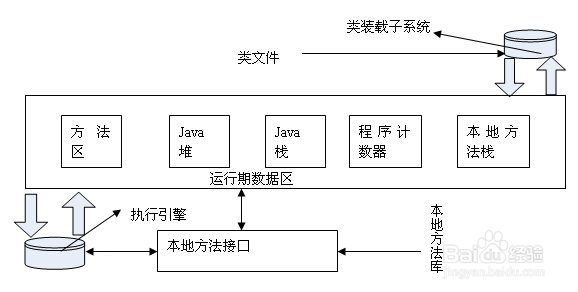
jvm栈和堆之间的区别是什么?
1、栈(stack)是存储任何基本数据值、对对象的引用和方法的位置。栈(stack)上变量的生存期由代码的范围决定。作用域通常由大括号中的代码区域 (如方法调用) 或 for 或 while 循环定义。一旦执行离开该作用域, 在作用域中声明的那些变量将从栈(stack)中删除。

2、调用方法时, 这些声明的变量将放置在栈(stack)的顶部。调用该栈(stack)中的另一个方法会将新方法的变量推送到栈(stack)上。

3、递归方法是一种直接或间接调用自身的方法。如果一个方法调用自己太多次, 栈内存就会填满, 最终任何更多的方法调用都将无法分配其必要的变量。这将导致栈溢出错误。来自生成异常的栈跟踪通常对同一方法有几十个调用。如果您正在编写递归方法, 则在称为基本大小写的方法中具有一种状态非常重要, 在该方法中, 不会再进行递归调用。
4、递归方法通常比迭代方法使用更多的栈空间, 因此也因此使用更多的内存。尽管递归方法看起来整洁优雅, 但请注意栈溢出可能导致的内存不足错误。下图显示了以递归和迭代风格编写的相同算法。

5、比较用于反转数组的两种算法。每个算法需要多少空间?对于递归定义, 每次递归调用该方法时, 都会创建一个新列表。每个方法调用中的这些列表必须保存在内存中, 直到列表完全被反转。尽管实际列表将保存在堆上 (因为这是存储对象的位置), 但每个方法调用都需要堆栈空间。
6、对于迭代版本, 唯一需要的空间是一个变量, 以便在与列表另一端的对应方交换时保存一个值。没有递归调用, 因此堆栈不会变得非常深。不分配新对象, 因此不会占用堆上的额外空间。
7、尝试使用列表中的元素数。是否可以使递归方法引发堆栈溢出错误?
声明:本网站引用、摘录或转载内容仅供网站访问者交流或参考,不代表本站立场,如存在版权或非法内容,请联系站长删除,联系邮箱:site.kefu@qq.com。