Flink复杂事件处理 (CEP)教程
1、CEP语法
SELECT [ ALL | DISTINCT ]
{ * | variable [,variable ]* }
FROM tableExpression
MATCH_RECOGNIZE (
[PARTITION BY { variable [,variable ]*}]
ORDER BY {orderItem [, orderItem]*}
MEASURES {measureItem AS col [,variable AS col]*}
ONE ROW PER MATCH
[AFTER MATCH SKIP]
PATTERN (patternVariable[quantifier] [ patternVariable[quantifier]]*)
[WITHIN intervalExpression]
DEFINE {patternVariable AS patternDefinationExpression [, patternVar iable AS patternDefinationExpression]*} )];
2、SQL语义

3、CEP语句详解
(1)Partitioning(分区)
可以在分区数据中查找模式,例如,单个股票或特定用户的趋势。 这可以使用PARTITION BY子句表示。 该子句类似于使用GROUP BY进行聚合。
注意:强烈建议对传入数据进行分区,否则MATCH_RECOGNIZE子句将被转换为非并行operator以确保全局排序。且只支持字段,不支持函数。
(2)Order of Events(事件排序)
允许根据时间搜索模式; 处理时间或事件时间。
事件时间的情况下,事件会被排序,在传入内部匹配状态机之前。因此,无论行追加到表的顺序如何,生成的输出都是正确的。按照每行中包含的时间指定的顺序的评估模式。
MATCH_RECOGNIZE子句假定时间属性具有升序排序作为ORDER BY子句的第一个参数。
(3)Defining a Pattern(定义模式)
MATCH_RECOGNIZE子句允许用户使用功能强大且富有表现力的语法搜索事件流中的模式,该语法与广泛使用的正则表达式语法类似。
每个模式都是由基本构建块构建的,称为模式变量,可以应用运算符(量词和其他修饰符)。整个模式必须括在括号中。
示例模式可能如下所示:
PATTERN (A B+ C* D)
可以使用以下运算符:
连接 - 像(A B)这样的模式意味着A和B之间的连续性是严格的。因此,不存在未映射到A或B之间的行。
(4)Greedy & Reluctant Quantifiers(贪婪量词和非贪婪量词)
每个量词可以是贪婪的(默认行为)或非贪婪的。贪婪量词试图匹配尽可能多的行,而非贪婪的量词试图尽可能少地匹配。
量词:⽤于指定符合pattern中定义的事件的出现次数。
(5)Time constraint(时间限制)
特别是对于流式使用情况,通常要求模式在给定的时间段内完成。这允许限制Flink必须在内部维护的整体状态大小,即使在贪婪量词的情况下也是如此。
因此,Flink SQL支持WITHIN用于定义模式的时间约束的附加(非标准SQL)子句。该子句可以在该PATTERN子句之后定义,并采用毫秒分辨率的间隔。
如果潜在匹配的第一个和最后一个事件之间的时间长于给定值,则此匹配不会附加到结果表。
注意:通常鼓励使用该WITHIN子句,因为它有助于Flink进行有效的内存管理。(6)Aggregations(聚合)
聚合可以用在DEFINE和MEASURES子句中。支持内置和自定义用户定义的功能。
(7)After Match Strategy(跳过策略)
AFTER MATCH SKIP子句指定在找到完整匹配后开始新匹配过程的位置。
有四种不同的策略:
若不写默认模式是: SKIP TO NEXT ROW
SKIP PAST LAST ROW -匹配成功之后,从匹配成功的事件序列中的最后⼀个事件的下⼀个事件开始进⾏下⼀次匹配。.
SKIP TO NEXT ROW -匹配成功之后,从匹配成功的事件序列中的第⼀个事件的下⼀个事件开始进⾏下⼀次匹配。(默认模式).
SKIP TO LAST variable -匹配成功之后,从匹配成功的事件序列中最后⼀个对应于变量的事件开始进行下⼀次匹 配。
SKIP TO FIRST variable -匹配成功之后,从匹配成功的事件序列中第⼀个对应于变量的事件开始进行下⼀次匹配。
4、案例描述:
当相同的card_id在⼗分钟内,从两个不同的location发⽣刷卡现象,就会触发报警机制,以便于监测信⽤卡盗刷等现象。
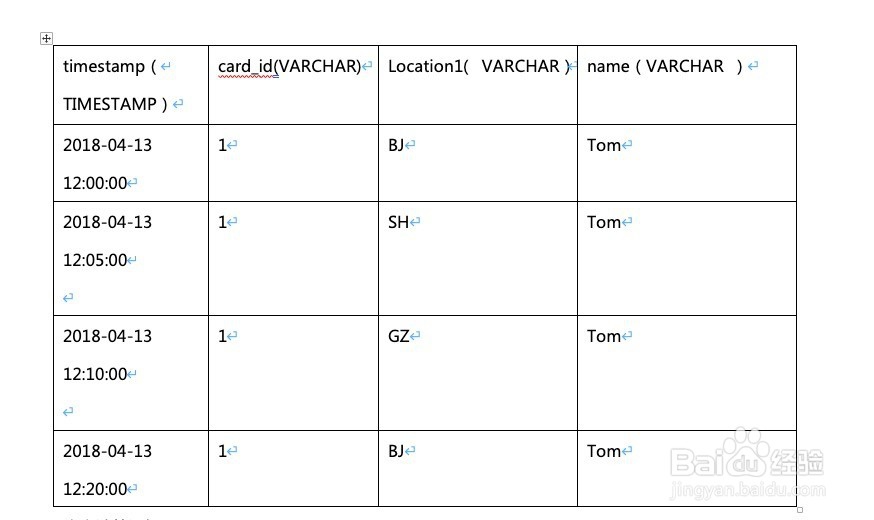
数据源如下图:
定义计算逻辑:
select
start_timestamp,
end_timestamp,
card_id,
event
from stream_CEP_pyy01
MATCH_RECOGNIZE (
PARTITION BY card_id -- 按card_id分区,将相同卡号的数据分到同⼀个计算节点上。
ORDER BY timestamp -- 在窗口内,对事件时间进⾏排序。
MEASURES --定义如何根据匹配成功的输⼊事件构造输出事件。
e2.name as e2name, --事件e2的name称作event
e1.timestamp as start_timestamp,
LAST(e2.timestamp) as end_timestamp --最新的事件时间为 end_timestamp。
ONE ROW PER MATCH --匹配成功输出⼀条。
AFTER MATCH SKIP TO NEXT ROW --匹配后跳转到下⼀⾏。
PATTERN (e1 e2+?) WITHIN INTERVAL '10' MINUTE -- 定义两个事件e1和e2。
DEFINE --定义在PATTERN中出现的变量的具体含义。
e1 as e1. name = 'Tom', --事件⼀的name标记为Tom。
e2 as e2. name = 'Tom' and e2.location1 <> e1.location1 --事件⼆的name标记为Tom,且事件⼀和事件⼆的位置不⼀样。
);
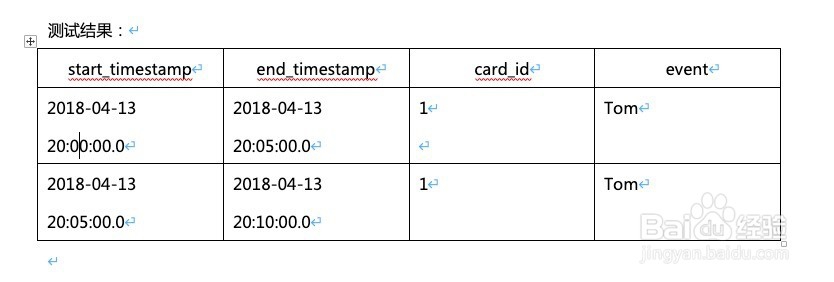
测试结果如图所示: