Python提取网站源码的方法
1、首先安装requests模块,按键盘上的ctrl+R打开运行窗口-输入cmd,打开命令提示符。


2、在命令提示符上面输入命令 pip install requests,回车后会自动安装好模块

3、打开Python开发工具,用import代码引入模块:import requests

4、用def 建立一个函数,名称为 get_content,参数为url,在函数功能部分用requests模块中的get方法提取指定url的页面源码。
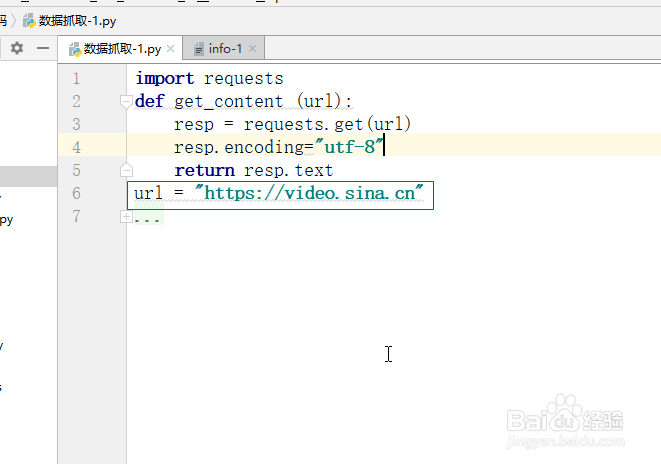
def get_content (url):
resp = requests.get(url)
resp.encoding="utf-8"
return resp.text
这里提取出来的编码为utf-8

5、接下来我们建立一个变量url,里面写上一个网址。代码如下:
url = "https://video.sina.cn"
这里的网址可以自己规定
6、接下来我们调用函数get_content,并且打印出部分内容,具体代码如下:
content = get_content(url)
print(content[0:100])


7、我们也可以用文件操作方法,把提取到的内容保存到我们创建的一个文件当中,具体代码如下:
f = open("info-1",mode="w",encoding="utf-8")
f.write(content)
f.flush()
f.close()
这里我们把提取到的源码保存到了info-1 这个文档当中

8、整体代码总结:
import requests
def get_content (url):
resp = requests.get(url)
resp.encoding="utf-8"
return resp.text
url = "https://video.sina.cn"
content = get_content(url)
print(content[0:100])
f = open("info-1",mode="w",encoding="utf-8")
f.write(content)
f.flush()
f.close()
声明:本网站引用、摘录或转载内容仅供网站访问者交流或参考,不代表本站立场,如存在版权或非法内容,请联系站长删除,联系邮箱:site.kefu@qq.com。
阅读量:152
阅读量:55
阅读量:27
阅读量:159
阅读量:32