Python机器学习开发入门案例
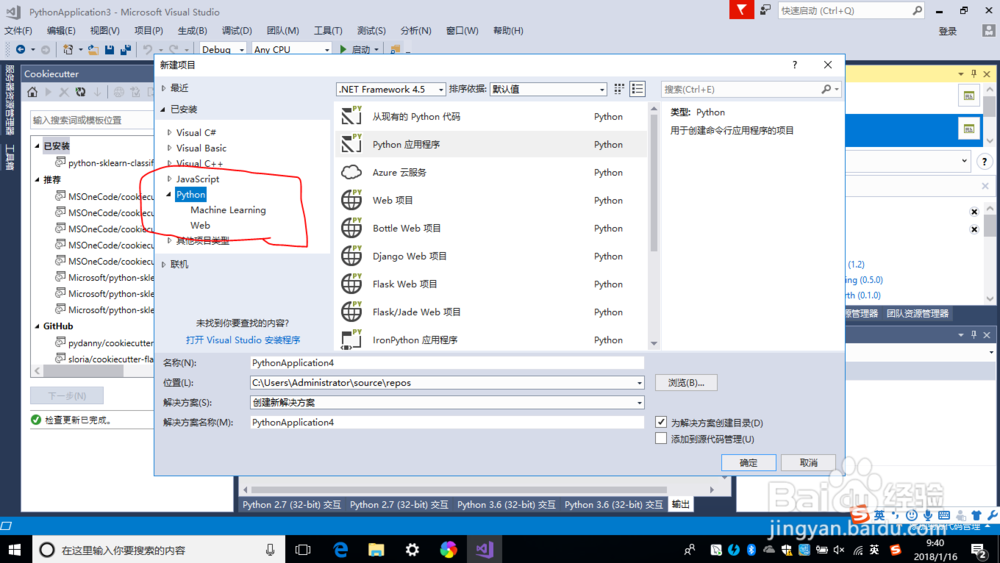
1、开发环境准备,这里我选用Visual Studio 2017作为Python的开发工具,要求在Visual Studio中安装Python环境支持
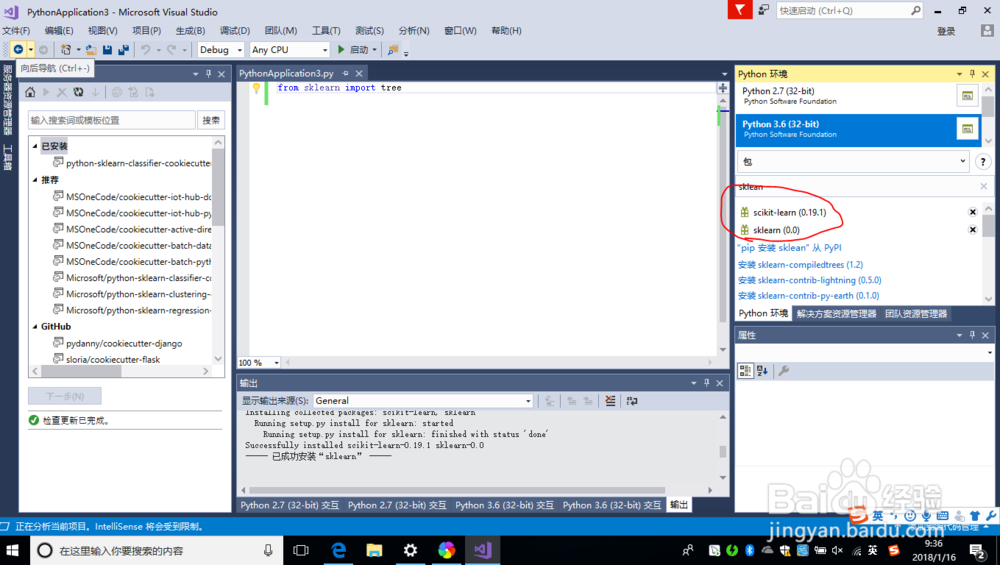
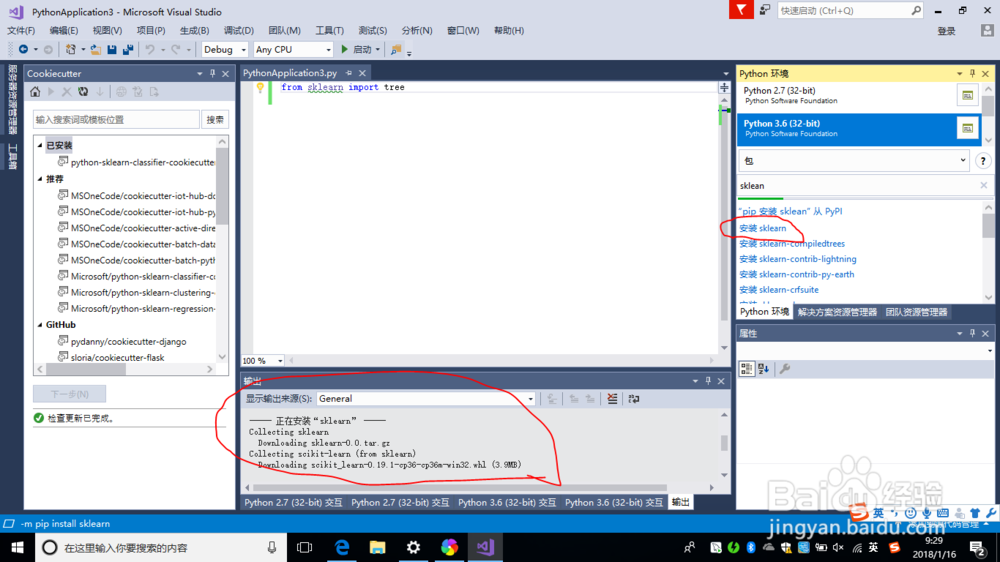
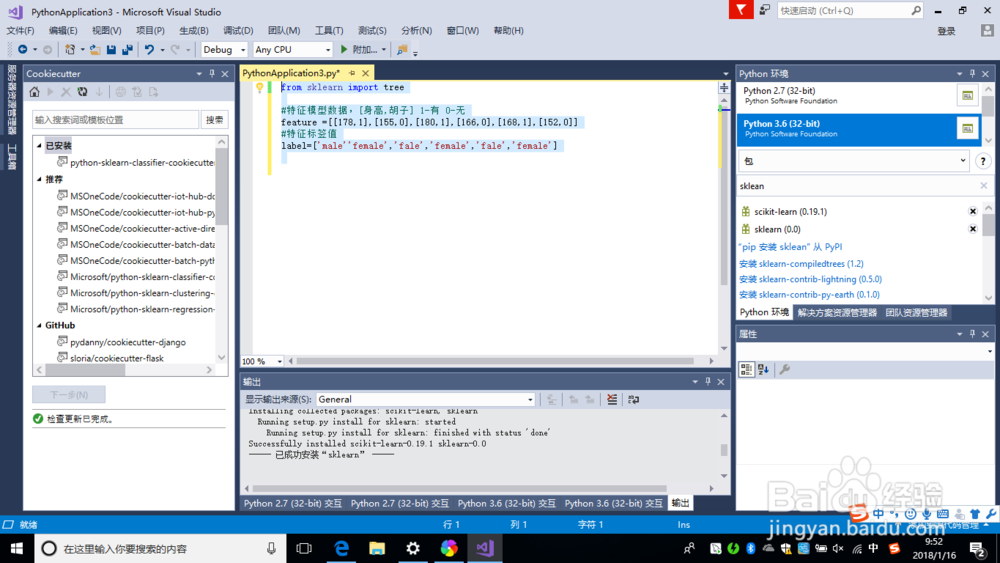
2、在进行机器学习开发时我们需要给python环境安装所需要的外部依赖包
sklearn,numpy,spicy
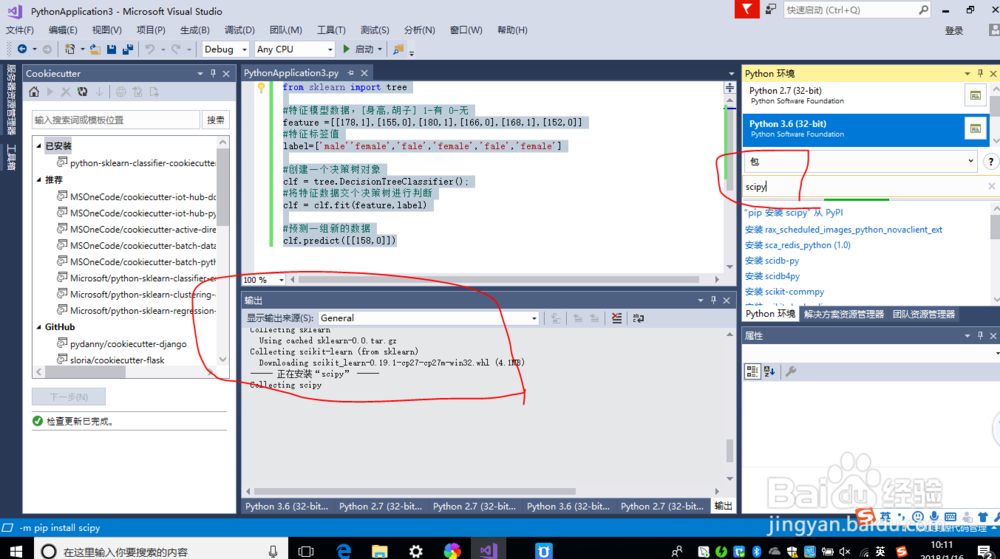
3、引入sklearn包,创建数据特征模型
from sklearn import tree
#特征模型数据,[身高,胡子] 1-有 0-无
feature =[[178,1],[155,0],[180,1],[166,0],[168,1],[152,0]]
#特征标签值
label=['male''female','fale','female','fale','female']
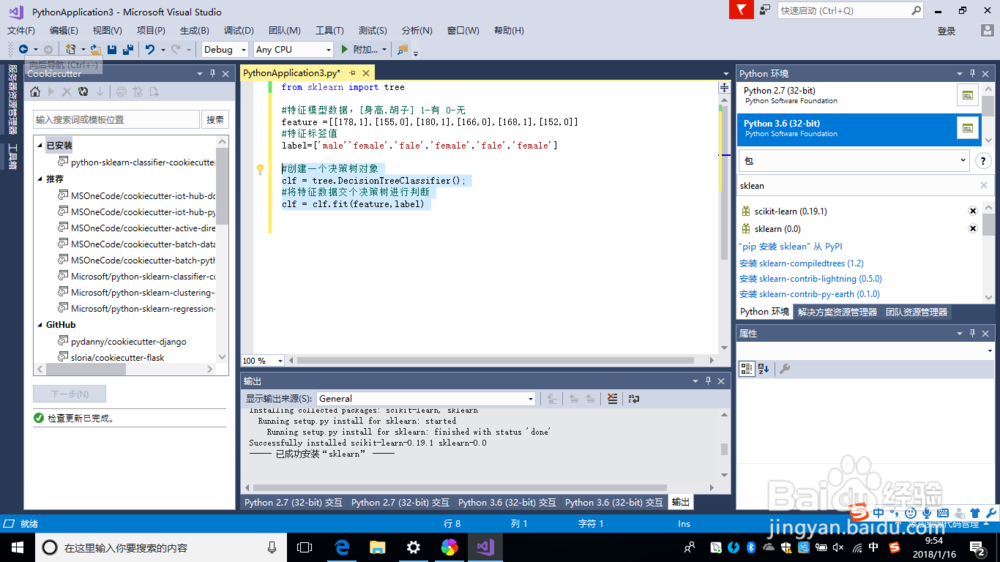
4、我们采用决策树进行分类预测
#创建一个决策树对象
clf = tree.DecisionTreeClassifier();
#将特征数据交个决策树进行判断
clf = clf.fit(feature,label)
5、进行新的数据预测
#预测一组新的数据
clf.predict([[158,0]])
clf.predict([[190,1]])
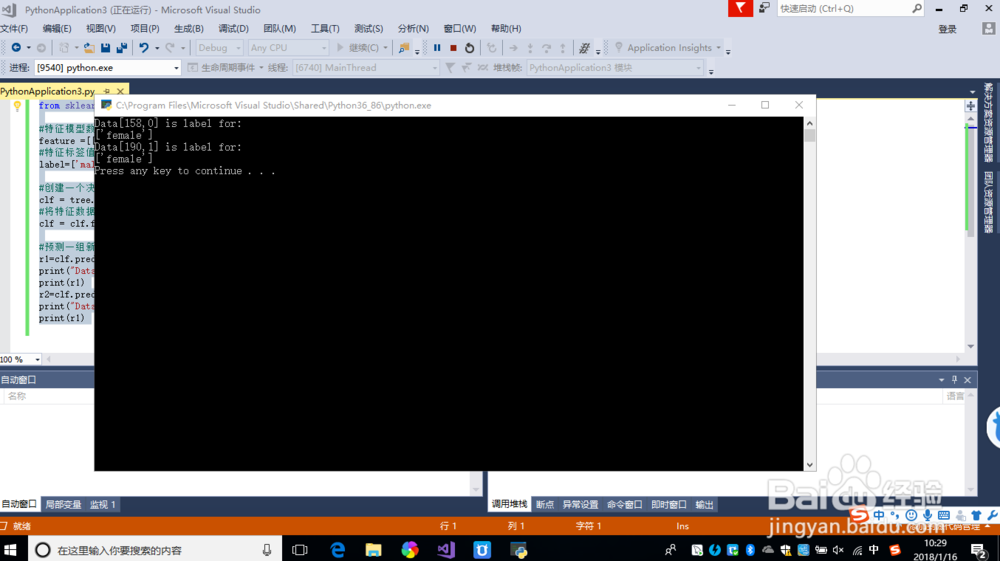
6、完成的Python的代码如下:
from sklearn import tree
#特征模型数据,[身高,胡子] 1-有 0-无
feature =[[178,1],[155,0],[180,1],[166,0],[168,1],[152,0]]
#特征标签值
label=['male','female','fale','female','fale','female']
#创建一个决策树对象
clf = tree.DecisionTreeClassifier();
#将特征数据交个决策树进行判断
clf = clf.fit(feature,label)
#预测一组新的数据
r1=clf.predict([[158,0]])
print("Data[158,0] is label for:")
print(r1)
r2=clf.predict([[190,1]])
print("Data[190,1] is label for:")
print(r1)