如何使用scrapy shell 爬取数据
1、第一步:我们首先切到命令行窗口,找到我们scrapy项目目录。
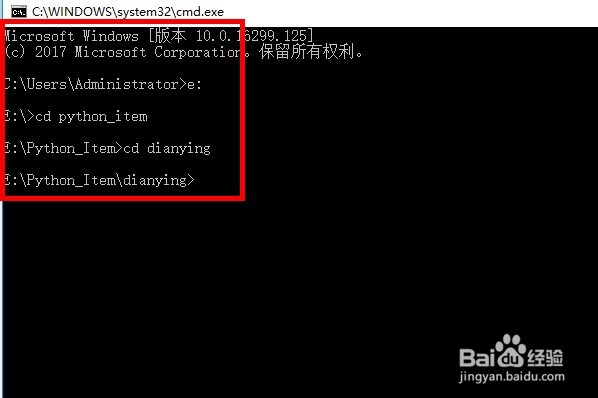
2、第二步:我们直接在项目目录中输入scrapy shell 加上访问地址。
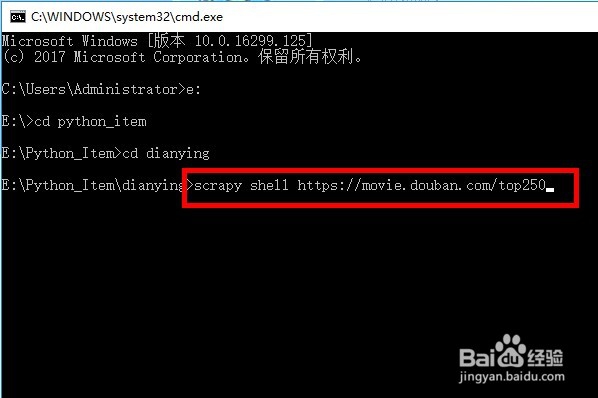
3、第三步:我们可以看到,我们访问的网址成功了,并且给我们提示命令内容。
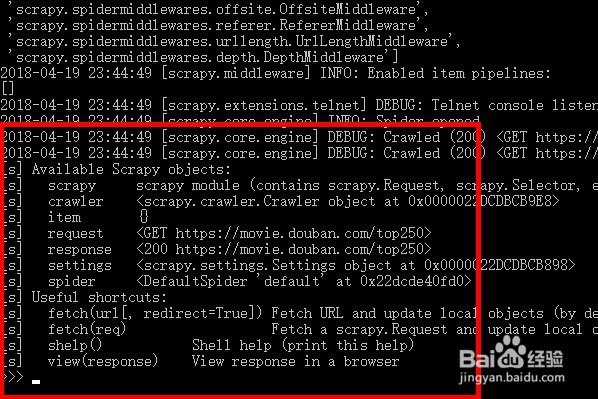
4、第四步:我们使用xpath将需要的内容进行提取。
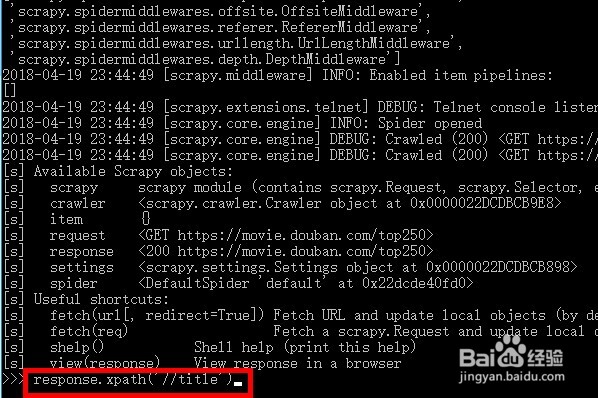
5、第五步:我们可以看到,爬虫已经成功将标题返回了。快来实践一下吧。

声明:本网站引用、摘录或转载内容仅供网站访问者交流或参考,不代表本站立场,如存在版权或非法内容,请联系站长删除,联系邮箱:site.kefu@qq.com。
阅读量:51
阅读量:172
阅读量:58
阅读量:138
阅读量:191