Sqoop如何实现增量导入
1、增量导入在企业当中,一般都是需要经常执行的,如隔一个星期就执行一次增量导入,故增量导入的方式需要多次执行,而每次执行时,又去写相应的执行命令的话,比较麻烦。而sqoop提供了一个很好的工具save job的方式。

2、测试的方式是通过--incremental来执行 lastmodified 模式, --check-column来设置 LASTMODIFIED检查的字段,意思就是当该字段发生更新或者添加操作,则才会执行导入。--last-value来设置初始值 '2014/8/27 13:00:00',该值是用来作为第一次导入的下界,从第二次开始,sqoop会自动更新该值为上一次导入的上界。

3、在上面的job当中,不能指定-m ,因为指定了-m的话,对应的导入会在hdfs上差生相应的中间结果,当你下一次再次执行job时,则会因为output directory is exist 报错。

4、 上面的hivetablename必须是已存在的。在第一次导入的时候,为了使得表存在,可以通过将oracletablename的表结构导入到hive中,执行完后,会在hive中创建一个具有相同名字和相同表结构的表。
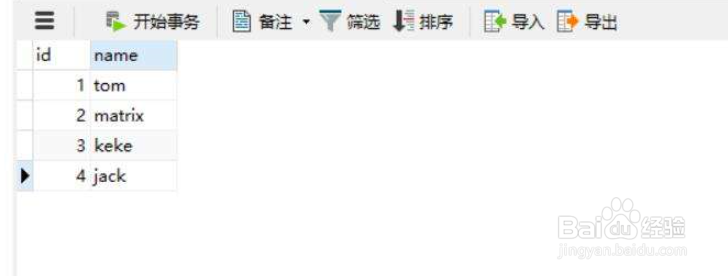
5、查看并执行job上面已经创建了job后,可以通过下面的命令来查看是否已经创建job成功执行完job后,查看hive中的表是否有数据。当然不出意外肯定是有数据的。
6、然后打成JAR包,给sqoop提交给hadoop 的MR来解析Hive表中的数据。那我们可以根据报的错误,找到对应的行,改写该文件,编译,重新打包,sqoop可以通过 -jar-file ,–class-name 组合让我们指定运行自己的jar包中的某个class。来解析该hive表中的每行数据。

声明:本网站引用、摘录或转载内容仅供网站访问者交流或参考,不代表本站立场,如存在版权或非法内容,请联系站长删除,联系邮箱:site.kefu@qq.com。