TypeError: expected string or bytes-like..
1、代码,如下所示:
import refrom crawling import downloadimport urllib.parsedef link_crawler(seed_url,link_regex): """Crawl from the given seed URL following links matched b link_regex """ crawl_queue = [seed_url] while crawl_queue: url = crawl_queue.pop() html = download(url) #filter for links matching our regular expressiong for link in get_links(html): if re.match(link_regex,link): crawl_queue.append(link)def get_links(html): """Return a list of links from html""" # a regular expression to extract all links from the webpage webpage_regex = re.compile('<a[^>]+href=["\'](.*?)["\']', re.IGNORECASE) #List of all links from the webpage return webpage_regex.findall(html)link_crawler('http://example.webscraping.com','/(index|view)')
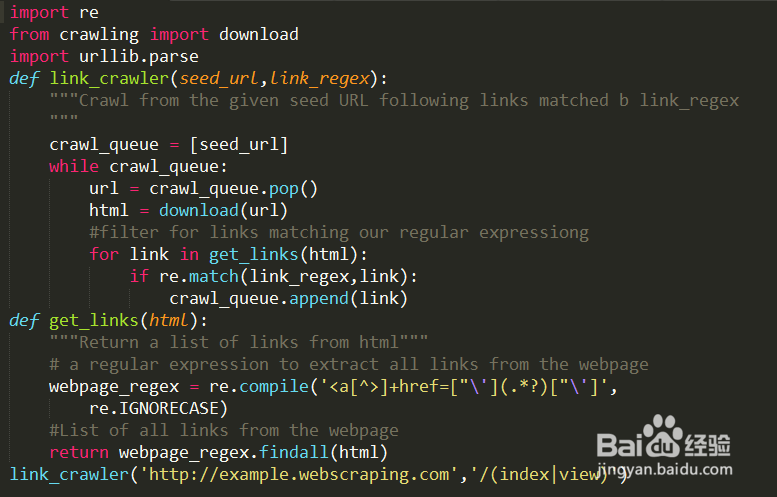
2、运行之后报错:
TypeError: expected string or bytes-like object
3、分析可得是:字符串相关问题
这里看一下findall:
re.findall(pattern, string[, flags]):
解释为:搜索string,以列表形式返回全部能匹配的子串。


4、所以我们要将 return webpage_regex.findall(html)中的html 改为str(html)

5、运行后,成功。
如果您觉得有帮助的话,帮我投个票吧。
