spark开发环境搭建(idea scala maven)
1、scala插件的安装
首先在欢迎界面点击Configure,选择plugins如下图所示:
下面的第三个图是安装后的所以是uninstall 没有安装的话是 install ,安装成功后,点击OK退出


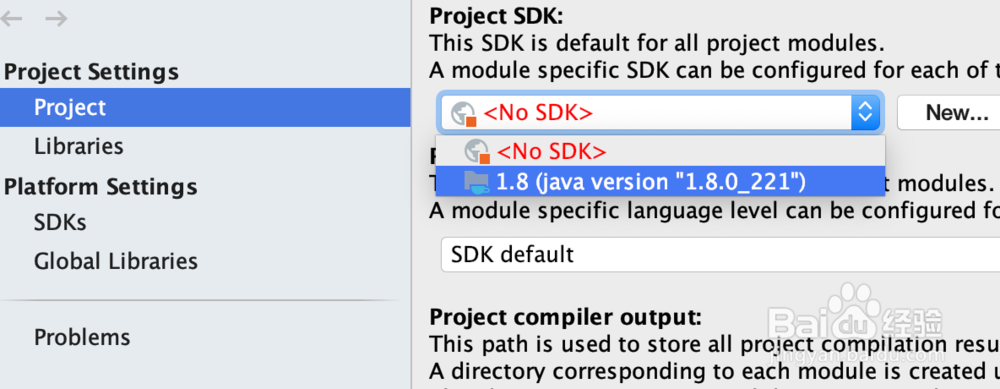
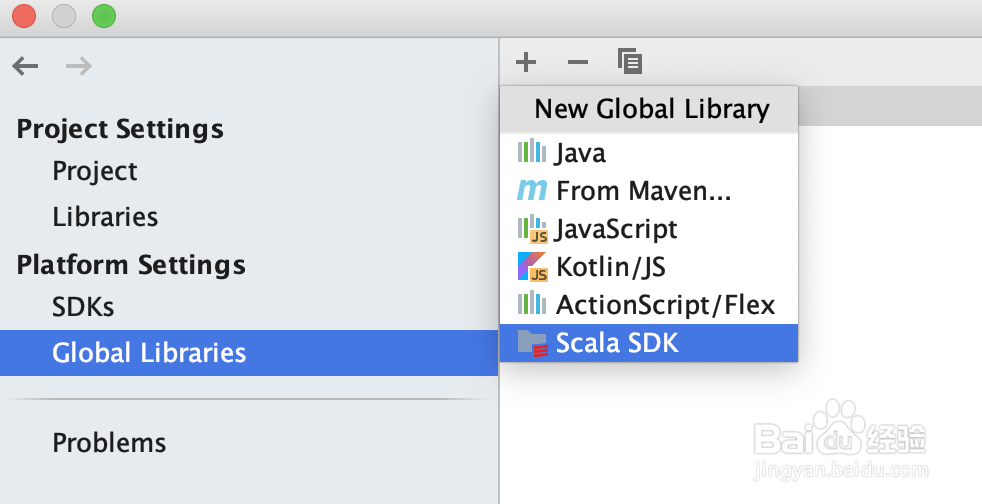
2、全局JDK和Scala SDK的设置如下图所示
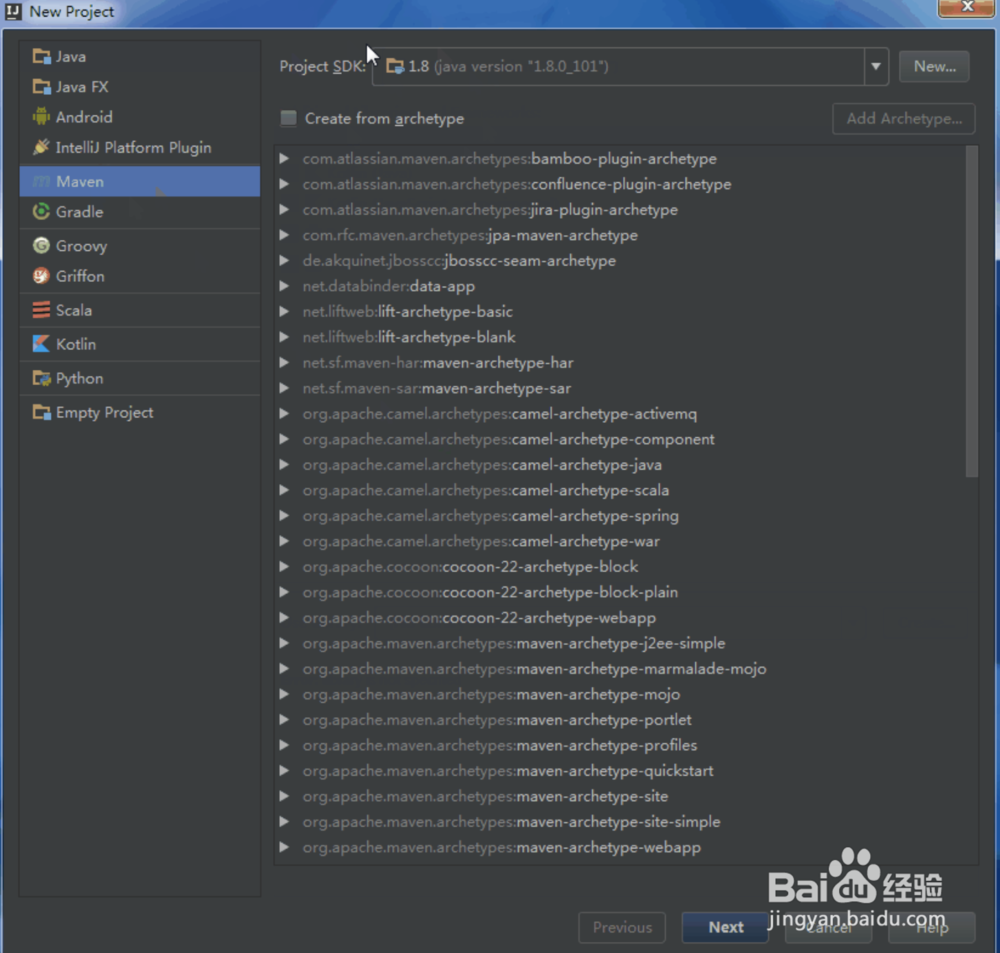
3、新建maven项目:
欢迎界面点击Create New Project,在打开的页面左侧边栏中,选择Maven,然后在右侧的Project SDK一项中,查看是否是正确的JDK配置项正常来说这一栏会自动填充的
4、导入spark依赖:
<properties>
<spark.version>2.4.0</spark.version>
<scala.version>2.12</scala.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.19</version>
<configuration>
<skip>true</skip>
</configuration>
</plugin>
</plugins>
</build>
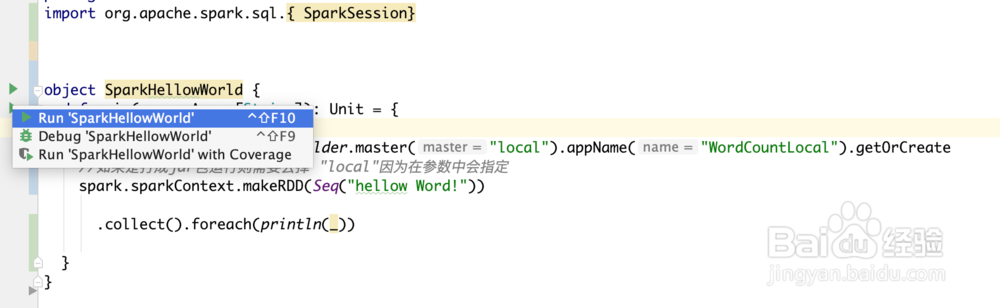
5、编写sprak代码
打印hellow world!
import org.apache.spark.sql.{ SparkSession}
object SparkHellowWorld {
def main(args: Array[String]) {
val spark= SparkSession.builder.master("local").appName("WordCountLocal").getOrCreate
//如果是打成jar包运行则需要去掉 "local"因为在参数中会指定
spark.sparkContext.makeRDD(Seq("hellow Word!"))
.collect().foreach(println(_))
}
}
按如下图在本地运行
声明:本网站引用、摘录或转载内容仅供网站访问者交流或参考,不代表本站立场,如存在版权或非法内容,请联系站长删除,联系邮箱:site.kefu@qq.com。
阅读量:21
阅读量:75
阅读量:37
阅读量:133
阅读量:49