python判断网页下载是否结束
1、关于要导入的包
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
详解:
1、selenium:web自动化测试工具集,包括IDE、Grid、RC(selenium 1.0)、WebDriver(selenium 2.0)等。
①webdriver:提供了web自动化的各种语言调用接口库
②By:进行元素定位的包
③WebDriverWait:web driver等待的包
④expected_conditions:判断页面元素的包
2、time:python自带时间包,可对时间相关的事务进行控制和操作。
2、关于打开网页的介绍
browser = webdriver.Chrome()
browser.get("https://www.baidu.com")
详解:
webdriver.Chrome自动打开chrome浏览器
browser.get打开指定网页
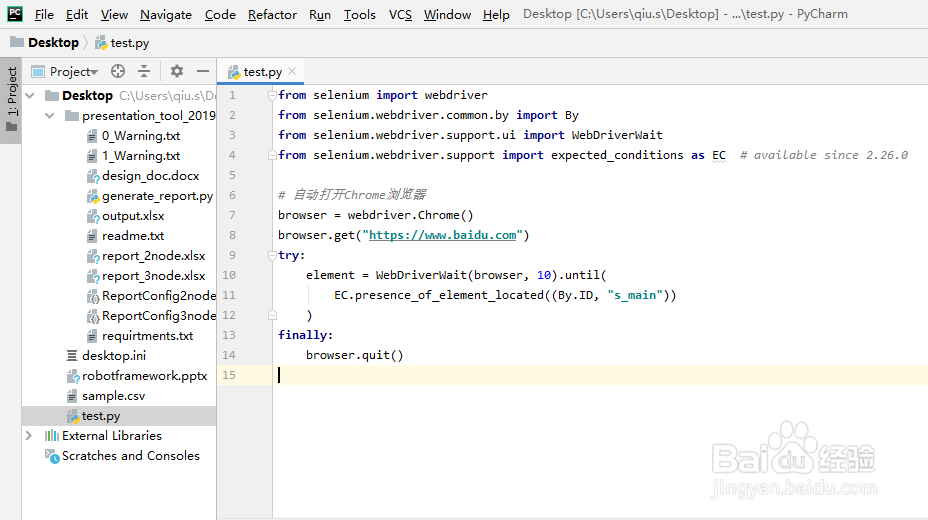
1、try:
element = WebDriverWait(browser, 10).until(
EC.presence_of_element_located((By.ID, "s_main"))
)
finally:
browser.quit()
详解:
WebDriverWait等待浏览器10s,直到指定id的元素(id为"s_main")刷新成功
注意WebDriverWait在设置的时间内,默认每隔一段时间检测一次当前页面元素是否存在,默认间隔时间为0.5s。
1、browser = webdriver.Chrome()
browser.implicitly_wait(10) # seconds
browser.get("https://www.baidu.com")
详解:
打开chrome浏览器后,设定隐式等待时间(单位是秒),打开指定网页。
如果指定网页打不开,则隐式等待一段时间(例子里是10秒),再次发起打开指定网址。如果还是打不开,则抛出异常。
implicitly_wait需要先设定等待时间,在指定要等待的网页。

1、time.sleep(10)
设置固定休眠时间(单位是秒)。
python 的 time 包提供了休眠方法 sleep(),导入time包后就可以使用sleep(),使脚本进入休眠。休眠时间结束后,不管刷新是否成功,继续执行脚本。

声明:本网站引用、摘录或转载内容仅供网站访问者交流或参考,不代表本站立场,如存在版权或非法内容,请联系站长删除,联系邮箱:site.kefu@qq.com。
阅读量:58
阅读量:147
阅读量:30
阅读量:39
阅读量:33