如何在stata中生成虚拟变量(各种情况)?
1、双类别虚拟变量,顾明思议就是将变量分成两类进行虚拟变量的生成。如性别等等。
我们还是打开我们的老朋友auto.dta
sysuse auto
gen d=(length>200)
聪明的大家一看就知道,这样就可以生成一个双分类虚拟变量,也就是>200的是一个小于等于200的是一个。
图片是原始数据和生成的虚拟变量的截图


1、什么是多类别虚拟变量?就是把一个变量的每一个数都分成一类类,我们在生成分类变量时也就是做这一种最容易出现问题。
通常需要分类的变量时,季度变量还有不同的厂商,等等。

2、观察步骤1中的图片,我们现在相对不同厂商进行分类,这就很难受了。如果,我们想对每一个厂商都进行分类,我们需要使用上面教的gen命令很多次。这个样本的数量级别还好,如果数量级别更大,我们将很难处理这类问题。
这时我们可以使用:tab命令
help tab
我们查看tabulate命令的help,可以发现有一个生成虚拟变量的方法。

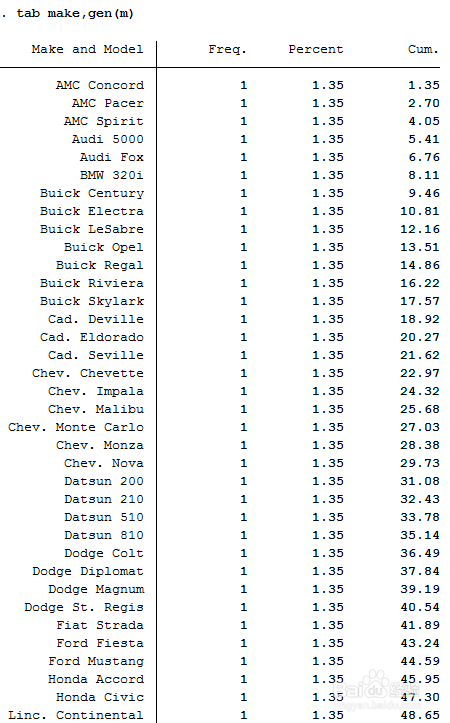
3、使用
tab make,gen(m)
即可生成按照make不同生成虚拟变量
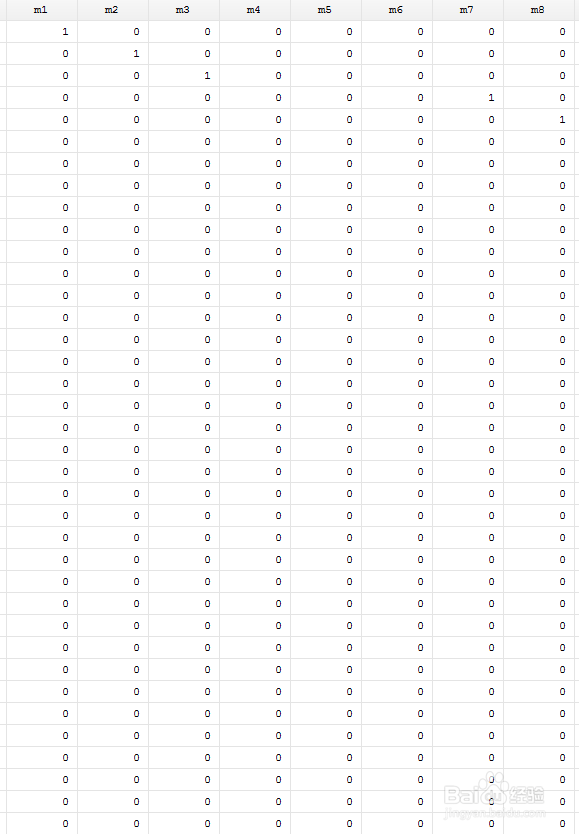
1、什么意思呢?就是对单一变量进行划分,将多个不同的数据划分成一类。这其实是非常常用的掌握了对大家都很有好处。
其实,生成虚拟变量,如果你是个愣头青,你直接看着数据挨个输入就好。
但是,还是希望大家都能灵活掌握stata的技巧,快人一大步。
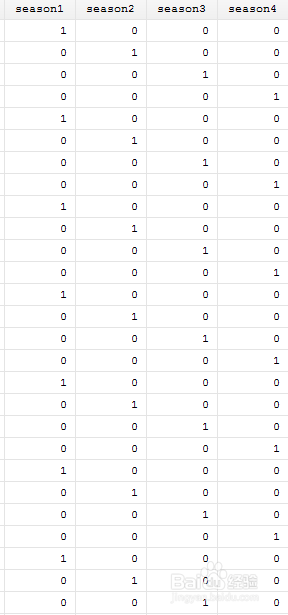
观察下面的数据表,是笔者我自己下载的数据,这个是一个时间的数据。这种数据是非常非常常用的,你从数据库下载的季度数据都是这个格式的数据。
有时候你会遇到这样的问题。如果我想按季节分类怎么办呢?
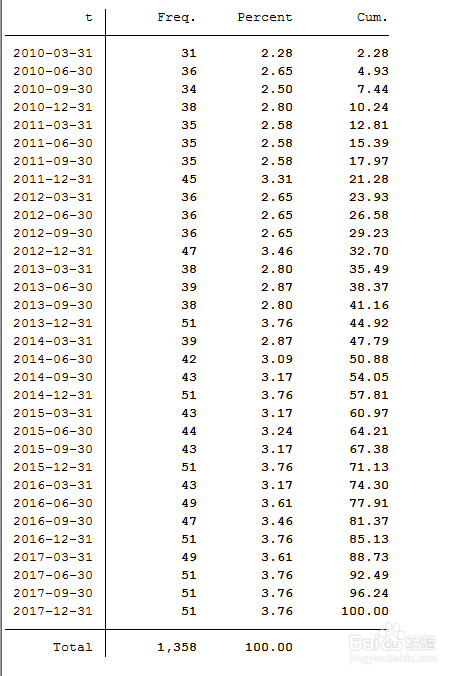
2、我在这里教大家一种我用的办法,是我自己在实践中总结,可能有更简单的命令,如果你知道可以和我联系,我会加一补充。
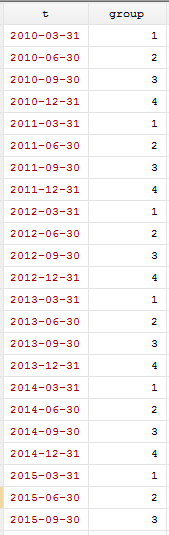
第一步 生成分类变量:
gen group=0
replace group=1 if regexm(t,"-03-")
replace group=2 if regexm(t,"-06-")
replace group=3 if regexm(t,"-09-")
replace group=4 if regexm(t,"-12-")
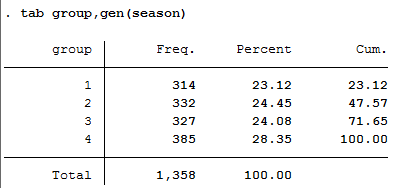
3、tab group,gen(season)