Prolog的数据结构
1、Prolog提供了一种在谓词中建立结构的方法,即允许谓词的变元具有变元,从而达到使谓词变元具有结构的目的。用这种方法可以使谓词中具有的信息反映现实生活中数据的实际关系。例如,考虑下面简单事实:
吉恩的头发是红色的。
显然,这个事实在Prolog中可以表示为:
has(jean, red_hair).
还有其他一系列关于人以及他们的头发、眼睛颜色和其它表征他们属性的事实,知识库可能如图所示。

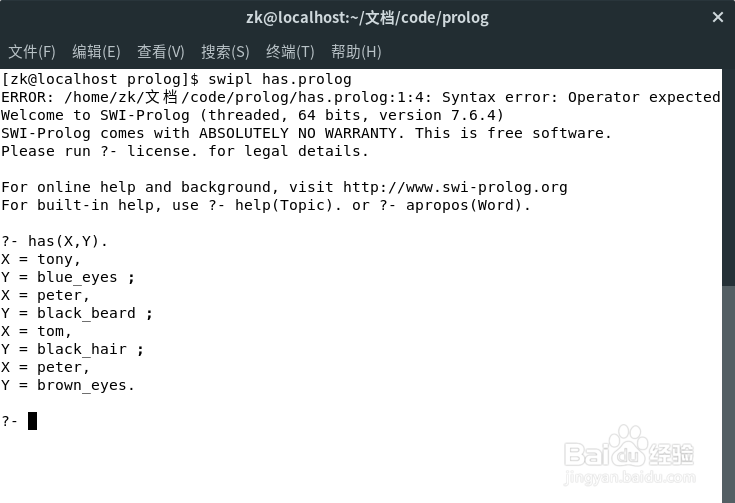
2、现在如果打算询问知识库中每个人的头发颜色,我们不得不这样提问:
?- has(X,Y).
并不断在提示符“?”后键入“;”,迫使回溯。会话过程如图所示。
正如读者所看到的,这样将导致大量不必要的信息输出。这是因为数据是非结构化的,因而无法较为明确地询问。
3、一种非常有用的,可确切地表达上述事实信息的方法如下:
has(jean, hair(red)).

4、现在为了了解知识库里每个人头发的颜色,我们可以简单地提出询问:
?- has(X, hair(Y)).
然后再要求Prolog在每个回答之后进行回溯,会话过程如图所示。
这些信息不多不少正是我们想要的。

1、表是基本的数据结构,许多实用的Prolog程序都是建立在表的基础之上的,表是许多元素的简单集合。比如:
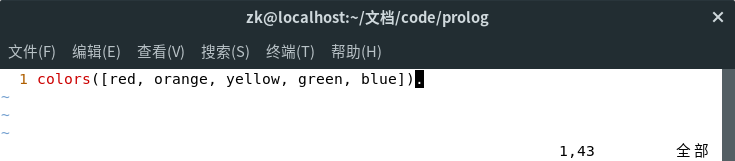
[red, yellow, green]
[1, 5, 68]
没有元素的表叫作空表,表示为:
[ ]
下图是一行列表的代码。
2、表头和表尾的概念是理解Prolog中表处理的基础。表头是一个元素,而表尾本身是一个表。表具有递归的数据结构,因为它是由表头和另一个表(表尾)组成的。正像其递归结构那样,表也可以递归定义。比如:
考虑到[a, b, c],该表表头=a,表尾=[b, c];表尾也是一个表,表头 = b,表尾=[c];而表尾[c],也是一个表,表头=c,表尾=[ ]。
由于[ ]是个空表,所以递归过程到此为止。空表可视为停止条件。
若用H表示表头,T表示表尾,则表记作:
[H|T]
其中竖线“|”是Prolog中用于分隔表头和表尾的符号。
下图是对上一个例子询问的结果,注意观察匹配模式。其中“_”为空变量,表示不关心该位置上的元素。

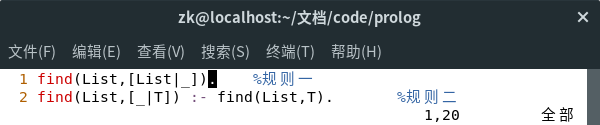
1、确定一个对象是否为某个表的成员。例如,我们有一个表List,内容是一些编程语言的名字。查找程序如下:
find(List,[List|_]).
find(List,[_|T]) :- find(List,T).
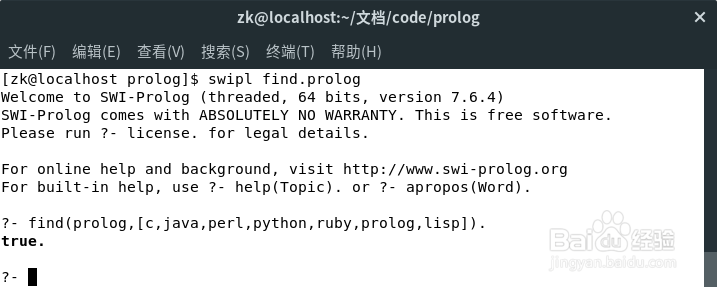
2、这是它的运行结果。Prolog对答案搜索的过程如下:
进入知识库,试图与规则一匹配,因为目标与表头不同,故失败;
继续搜索,试图与规则二匹配,目标和表尾作为参数,重新回到规则一,直到成功。
3、两个表的追加。有时需要把两个表合并成一起形成新表,这个过程叫做并置或追加。下面这段代码可实现表的追加,concatenate(A,B,C).后就可以将表B追加到表A后形成表C。
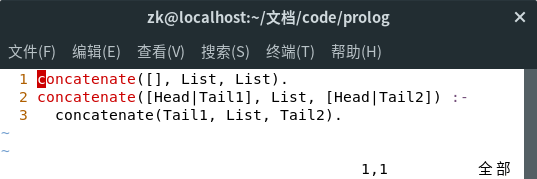
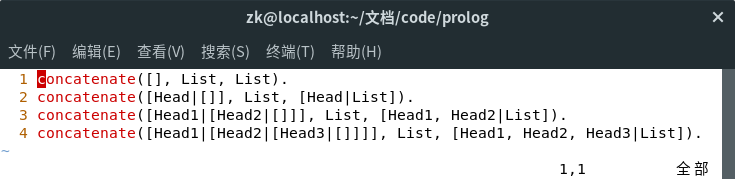
4、对于它的工作机制,不妨先从特殊到一般的规则来了解。
❶编写一个规则concatenate(List1, List2, List3). ,它可以将一个空列表与List1连接在一起。这一点很容易,concatenate([ ], List, List).就可以做到,当执行addto时,List3会和要追加的List2相同;
❷添加一个规则,它可以将List1中的一个元素与List2连接在一起:concatenate([Head|[]], List, [Head|List]).;
❸添加一个规则,它可以将List1中的两个元素或三个元素与List2连接在一起;
❹泛化这些规则,转化递归形式,最终形成上图中的代码。
5、表的反序。将表中元素的次序颠倒过来也是常用的一种处理过程。这个程序需要结合上一个例子中的追加列表的程序。其Prolog程序如下:
re([],[]).re([H|T],L) :- re(T,M), concatenate(M,[H],L).

6、以上规则是基于这样的思想,即可以通过把一个表头追加到该表的表尾的反序表上,达到反序的目的。谓词reverse的第一个变元缩减到空表时,满足停止条件,停止条件还可以表述为空表的反序仍为空表本身。下图是程序的运行结果。在导入程序时要注意文件的顺序。

7、表处理的一般形式。任何用于完成表处理的规则都是自身的递归。表处理规则具有以下一般形式:
manipulate(具有表头H和表尾T的表) :-
完成表头H的处理,
递归处理表尾T.
除此之外,还需要一个停止条件。被处理的表不断缩小,当成为空表时,整个表被处理完了,因此完整的表处理规则具有如下形式:
manipulate([ ]).
manipulate([H|T]) :-
process(H),
manipulate(T).
此外,具体应用时可能还有其他更好的表示形式,因此不必一味强求。

8、SWI-Prolog内置了丰富的处理列表的库,比如member就是用于查看元素是否属于列表,append用于追加列表,reverse用于倒序列表。你可以在SWI-Prolog的网站上的library(lists): List Manipulation页面上查找更多。
