scratch框架的crawspider类
1、爬行蜘蛛类您可以使用以下命令快速创建CrawlSpider模板的代码:

2、Crawspider是spider的一个派生类。spider类的设计原则是只抓取启动,crawler类定义了一些规则,为后续的链接提供了一个方便的机制。更适合从已爬网的网页获取链接并继续爬网。crawspider源代码详细分析

3、相关推荐:Python视频教程Crawlspider继承自spider类,以及继承的属性(名称、allow_udomains),并提供新的属性和方法:LinkExtractor公司链接提取器的目的很简单:提取链接每个linkextractor都有一个惟一的公共方法extract_ulinks(),它接收一个响应对象并返回一个刮擦链接链接对象。链接提取器应该实例化一次,extract_uLinks方法会根据不同的响应调用多次提取链接
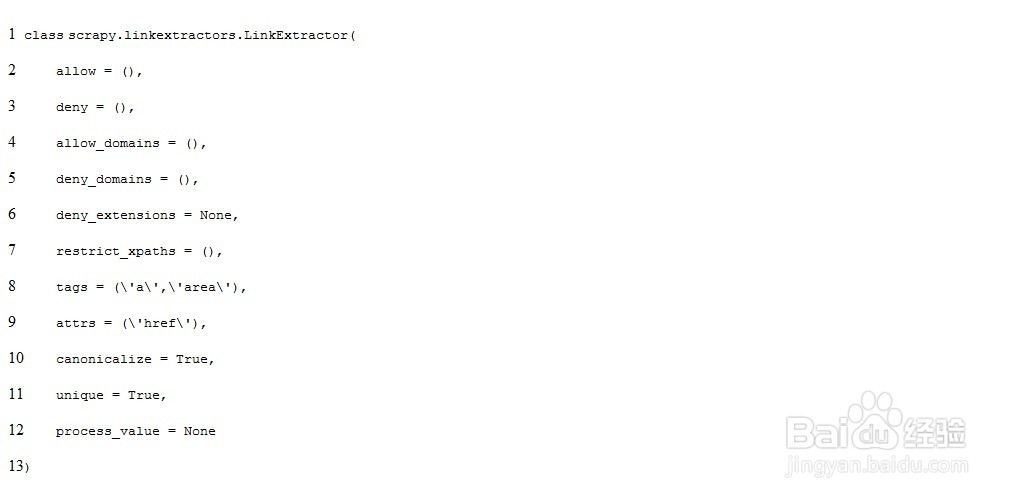
4、主要参数:Allow:将提取满足括号中“正则表达式”的值。如果为空,则所有值都将匹配。拒绝:不能提取与此正则表达式(或正则表达式列表)不匹配的URL。允许域:要提取的链接的域。拒绝域:不能提取的域。限制路径:使用XPath表达式与allow一起过滤链接规则规则包含一个或多个规则对象。每个规则都定义了对网站进行爬网的特定操作。如果多个规则匹配同一个链接,则将按照规则在此集合中定义的顺序使用第一个规则。

5、主要参数:链接提取器:是一个链接提取器对象,定义要提取的链接。Callback:from link_u在提取器中获取链接时,将参数指定的值用作回调函数,回调函数接受响应作为其第一个参数。注意:编写爬虫规则时,请避免将Parse用作回调函数。由于crawlspider使用parse方法实现其逻辑,因此如果parse方法被重写,crawler spider将失败。Follow:是一个布尔值,指定是否需要跟踪根据此规则从响应中提取的链接。如果callback为none,则follow默认设置为true,否则默认为false。process_uLinks:指定将调用spider中的哪个函数。当在extractor中获取链接列表时,将调用此函数。这种方法主要用于滤波。进程请求:指定将调用spider中的哪个函数。将规则提取到每个请求时,将调用此函数。