pandas的基础知识(2)
1、加载numpy和pandas,pandas中的 DataFrame,Series。
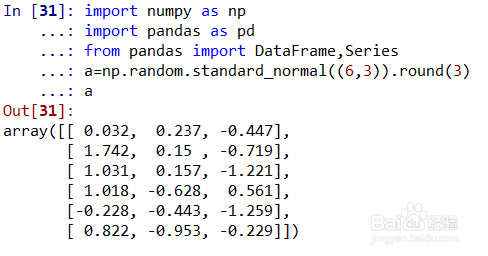
a=np.random.standard_normal((6,3)).round(3)表示随机生成一个6*3的标准正态分布数据,然后保留3位有效数字,赋值给a,如图所示
2、生成DataFrame。
df1=DataFrame(a)表示使用ndarray对象a生成一个DataFrame,赋值给df1,如图所示

3、修改df1的列名。
df1.columns=[['a','b','c']]表示分别给df1的列命名为'a','b','c',如图所示

4、修改df1的索引。
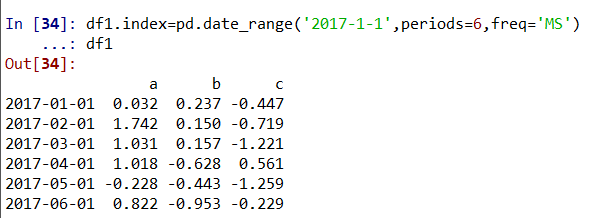
df1.index=pd.date_range('2017-1-1',periods=6,freq='MS')表示用date_range生成一个长度为6,起始日期为'2017-1-1',使用月初格式的DatatimeIndex对象数据来作为df1的索引;如图所示
5、将DataFrame再转化为ndarray。
np.array(df1)表示将df1这个DataFrame再转化为数组,如图所示

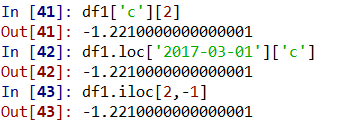
6、df1元素的获取方法(获取第三行第三列的数据)。
df1['c'][2]表示df1的‘c’列数据中第3个数据(‘c’列即第三列);df1.loc['2017-03-01']['c']表示df1的索引为‘2017-03-01’的‘c’列数据(‘c’列即第三列);df1.iloc[2,-1]表示df1的第三行最后一列数据(最后一列即第三列);三种方法结果一样,如图所示
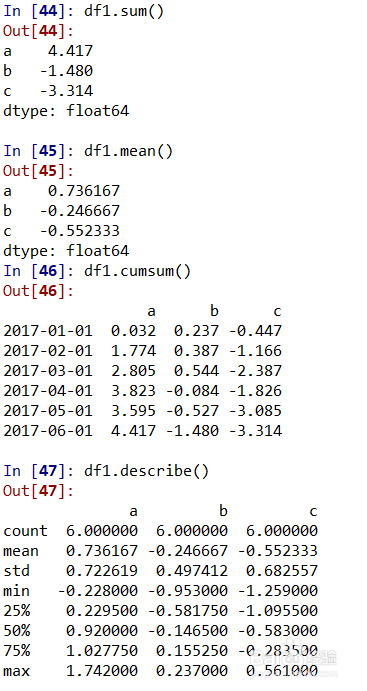
7、df1的统计计算。
df1.sum()表示按列求和;df1.mean()表示按列求均值;df1.cumsum()表示按列累计求和;df1.describe()表示对df1进行多个字段的统计(个数,均值,标准差,最小值,25%分位数,50%分位数,75%分位数,最大值);如图所示
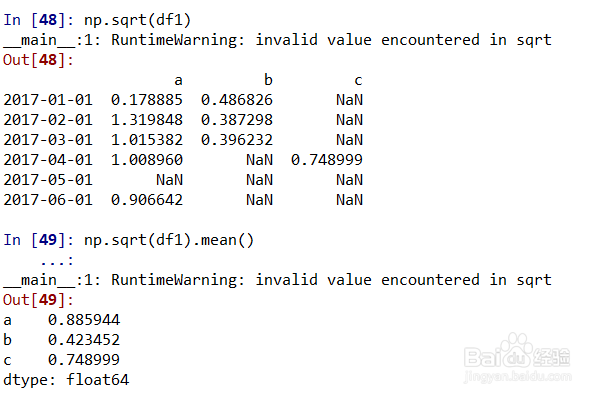
8、numpy通用函数对df1的应用;结果的再计算。
np.sqrt(df1)表示对df1的每个元素进行开方计算(注意:负数的开方结果给出的是NaN);
np.sqrt(df1).mean()表示对df1的没有元素开方后再按列求均值;如图所示
9、df1的简单绘图。
%matplotlib inline表示将matplotlib的图表直接嵌入到Notebook之中;
df1.cumsum().plot(lw=1.5)是表示df1的按列累计求和绘制一个线宽为1.5的折线图,如图所示
