pandas的基础知识(3)
1、加载numpy和pandas,pandas中的 DataFrame,Series。
使用数组生成一个5*5的DataFrame,分别使用'Name','Salary','Age','Sex','flag'作为索引,赋值给df1;df2=df1.T表示将df1转置后赋值为df2;type(df2)查看df2的类型;如图所示

2、由DataFrame的一列生成Series。
df2['Salary']表示取df2的一列;type(df2['Salary'])表示查看df2['Salary']的类型(显示为Series);如图所示

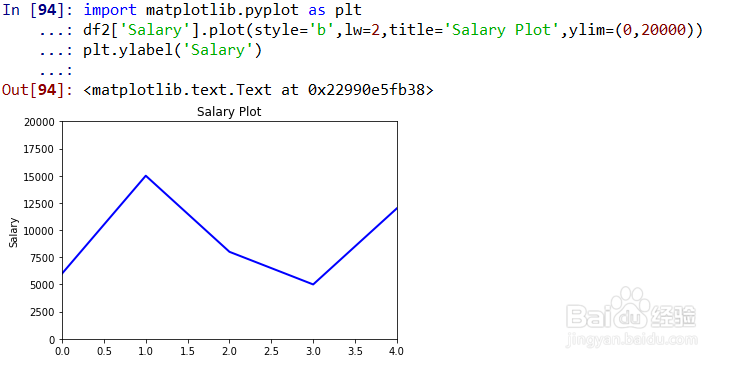
3、Series的绘图。
加载matplotlib.pyplot绘图库;
df2['Salary'].plot(style='b',lw=2,title='Salary Plot',ylim=(0,20000))表示对Series进行绘图,style='b'表示用蓝色,lw=2表示线宽为2,title='Salary Plot'表示图形标题为'Salary Plot',ylim=(0,20000)表示Y轴的范围;
plt.ylabel('Salary')表示给Y轴添加标签;如图所示
4、DataFrame的groupby操作(单个字段分组)。
df2.Salary=df2.Salary.astype(float)表示将df2的字段Salary转化为float;group1=df2.groupby(['Sex'])['Salary']表示df2按照'Sex'分组后对'Salary'字段进行统计;group1.mean()、group1.max()、group1.size()分别表示按‘Sex’分组后每组‘Salary’的均值、最大值、个数;如图所示

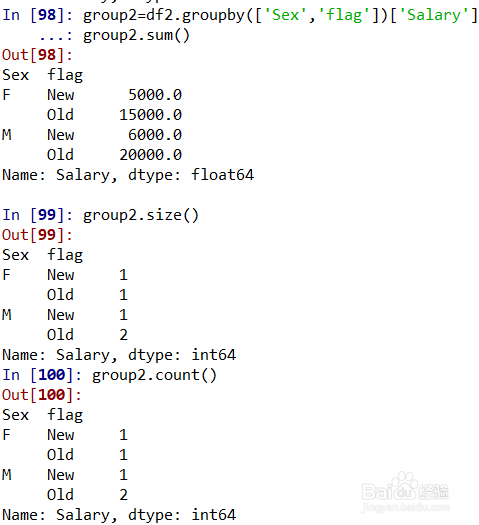
5、DataFrame的groupby操作(多个字段分组)。
group2=df2.groupby(['Sex','flag'])['Salary']表示df2按照'Sex'和'flag'分组后,对‘Salary’进行统计;group2.sum()和group2.size()分别表示按'Sex'、'flag'分组后每组的薪水总和、每组的个数;(group2.size()和group2.count()效果一样的)如图所示