stata中的_n和_N的简单应用?
1、问题1:什么是_n?
在stata中输入:
sysuse nlsw88.dta, clear //打开stata自带数据
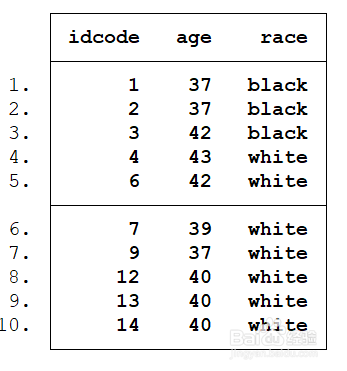
list idcode age race in 1/10
看下图中最左边的1,2就是n的内容
list idcode
输入上述命令后,见图2,最左边的数字2246就是idcode样本个数

2、知道了_n的含义之后,我们将_n应用在其他命令中
现在假设我们想对数据有一个直观感觉,我想敢看这个数据中age最小巨敏的10个样本
sort age //从小到大对hours进行排序
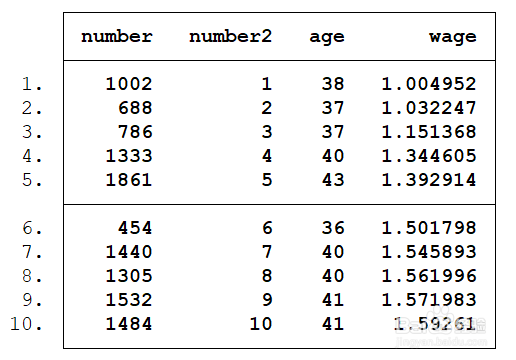
gen number = _n
list number age in 1/10

3、现在我们想看看,年龄珠排排和工资的关系
sort wage
gen number2 = _n // 第二个 _n 的内容
list number number2 age wage in 1/10
4、接下来我们再来看看_N的概念
dis _N
通过这个命令,我们可以看看我们有多少样本
scalar obs = _N
这个命令的意思是产生一个标量obs,stata中不止能储存向量,还能储存标量。
sum wage //对wage这个变量进行基本统计
di r(mean)*obs
di r(sum)
可以看到两个值相同栗痕。_N表示的是样本个数,有时候,我们可以利用_N自己计算一些数值。
补充:这个r(),里面包含的都是标量,stata的计算结束后,会保存下来一些值,之后我们会详细讲解这些问题。

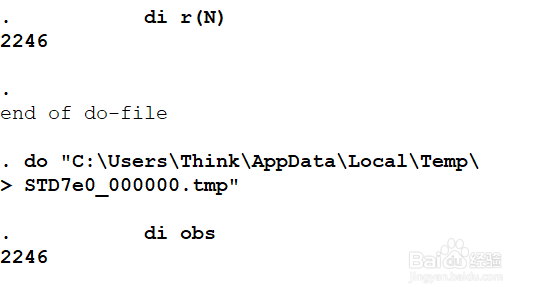
5、看看sum中的N值,_N和r(N)的值一样
sum idcode
di r(N)
di obs
这两个值其实是一个值
6、总结一下:
通过学习之后,我们理解了_N和_n
一个数据集中只有一个N,是一个标量,就是指整个数据集中有多少数据
每一行数据都有一个_n,指的就是数据的行数。他实际上是一个向量。
观察我手绘的概念和简单应用已经介绍完毕,高级应用我会再下一讲进行介绍。
